The first museum pecha kucha night was held in London at the British Museum on June 18, 2009. I took rough notes during the presentations, and have included the slides and notes from my own presentation. The event used the tag 'mwpkn' to gather together tweets, photos, etc. The focus of this first museum pecha kucha was on sharing insights and inspiration from the Museums and the Web conference held in Indianapolis in April.
The event was organised by Shelley Mannion, who introduced the event, emphasising that it was about fun and connecting the museum tech community in an interesting way.
Gail Durbin (V&A), takeaways from MW2009
She's a practical person, looks for ideas to nick. Good idea as things get hazy after a conference, good intentions disappear.
First takeaway – Dina Helal let her play with her iPhone, decided she had to have one. She liked her mobile for the first time in her life.
Second – twittering was very important. Decided to do something with it. Twittering is hard, sending out messages that are interesting is difficult.
Enthusiasm at conferences is short lived – e.g. people excited about wedding site, but did they send in wedding photos? She talked to people about a self-portraiture idea, 'life on a postcard', but hasn't had a single response.
RSS feeds – came away knowing we had to review our RSS feeds, had been without attention for a long time.
Learnt that wikis are very hard work, they don't automatically look after themselves.
Creative use of Flickr – museum 'my karsh' collection
Resolved that had to work with Development. Looking at something like the British Library's – adopt a book for fathers day.
Something that bothers her – many museums think of 'Web 2.0' just as more channels to push out information, there's no sense of pulling in information about visitors.
Beck Tench, one of the most interesting people she met at the conference – practice and work go together very closely. Flickr plant project. She wants to get staff involved – has meeting on Fridays, in local bar, tweets to everyone, conducts something called Experimonth.
Last thing learnt – librarians have better cakes.
Silvia Filippini Fantoni (British Museum and Sorbonne University)
Silvia makes a plea for extra seconds as a non-native speaker (and synthesis not the best feature of Italians). Lecturer in museum informatics and evaluation methods at Sorbonne and project manager for multimedia guide project at British Museum.
So her focus at the conference was mostly on guides. Particularly Samis and Pau and others. Mini workshops and workshops on the topic before and during the conference. Demos from Paul Clifford (Museum of London). Exhibitors. Lots of museums are planning to develop applications.
Interest in using mobile technology as an interpretive tool is constantly growing, especially delivered on visitors own devices. Proliferations of mobile platforms. Proliferation of different functionalities – not just audio – visual, games, way finding, web access and communication, notes and comments. Have all these new platforms and functionalities improved the visitor experience? Yes, but there are some disadvantages.
Asks: aren't we trying to do too much? Are we trying to turn a useful interpretive tool into something too complex? Aren't we forgetting about core audio guide audience?
Are people interested in using their own devices? Do they have the time to pre-download, do they bring their devices? Samis and Pau – the answer is no/not yet. For the medium and short term still need to provide media in the museums. Touch screen devices are easier to use. Limited functionality makes interface simpler. Focus on content – AV messages, touch and listen.
Importance of sharing and learning from best practice. Some efforts at and after MW2009 – handheldconference.org. Discussion of developing open source content management system for mobile devices – contact Nancy Proctor.
Daniel Incandela (Indianapolis Museum of Art)
He's from America so should have extra time too. Also sick and medicated (so at least one of us will have a good time during the presentation).
Enjoys robots, dinosaurs, football and a good point. On holiday while here.
Slide – Shelley's twitter profile – she's responsible for him being here while on holiday.
He blogged about preparing for the presentation and got a comment from one of the pecha kucha founders – the main thing is to have fun, be passionate about something you love.
Twitterfall on the big screen was a major breakthrough at MW2009, (#mw2009 trended as a topic and attracted the attention of) pantygirl.
Digital story telling and tech can't happen without support, Max Anderson has been dream leader.
He's here representing IMA so going to showcase some projects – Roman Art from Louvre webisodes – paved the way for informal, agile, multiple content source creation.
Art Babble. IMA blog – ripped off other museums – gives many departments from museum a digital voice.
Half time experiment with awkward silence (blank slide). [In the pub afterwards, I discovered that this actually made at least one of the English people feel socially awkward!]
Brooklyn Museum – for him the real innovators for digital content for museums, won many awards at MW2009.
Te Papa's 'build a squid' had him at 'hello'. First example of a museum project that actually went viral?
Perhaps we could upgrade MW site? Better integration of social media, multimedia from previous conferences.
Loves Bruce Wyman – reason to go to MW2010.
art:21 – smart team, good approaches to publishing across platforms.
Wonders about agility – love new and emerging projects (?) we hear about at conferences, but how do we face an idea and deal with own internal issues?
The Dutch at Indy (were great) – but somewhere outside north America next for Museums and the Web?
Philip Poole (British Museum)
Everything I got from MW2009 can be put into one statement – spread it about. Enable your content to be spread by other people through APIs.
Does spreading out content dilute our authority? By putting it onto other websites, putting it in contact with other people. No, of course not.
Video was big at MW2009.
If going to use different platforms, will people come? We need to tailor content to different websites – can't just build it and assume people will come. Persian coins vs. ritual Mayan sacrifice on YouTube – which will get bigger audience? [Pick content delivery to suit audience and context.]
Platforms include ArtBabble, YouTube (shorter, edgier), iTunes U. Viral content – we can put features on our website, but a YouTube or Vimeo audience are going to spread things better. iTunes, U, can download and listen on train – takes out of website entirely.
Stats are important – e.g. need to include stats of video on different platforms, make sure people above you recognise the value in that. DCMS – very basic stats – perhaps they should be asking for different stats. "If DCMS ask how much video we put on YouTube, we'd all start doing it." [Brilliant point]
API – take content from website and put elsewhere. IMA Explore section – advertise the repeating pattern in their URLs – someone used them but wasn't going very well, they got in contact with him and helped him succeed, now biggest referrer outside search engines. He wants to do that for the British Museum – he knows the quirks, the data.
Why the 'softly softly' approach? Creating an entire API interface is huge mountain, people above you will want to avoid it if you show them the size of the whole mountain.
Digital NZ – fantastic example. Can create custom search, embed on website, also into gallery and people can vote for it
The British Museum is a museum of the world for the world, why should their web presence be any different?
Mia Ridge (Science Museum)
Yes, that's me. My slides on 'Bubbles and Easter eggs – Museum Pecha Kucha' are on slideshare – scroll down the page for full text and notes – or available as a PDF (2mb).
I talked about:
- keeping the post-conference momentum going, particularly the 'do one thing' idea;
- museum technologists as 'double domain experts';
- not hiding museum geeks like Easter eggs but making more of them as a resource;
- the responsibilities of museum geeks as their expertise is recognised;
- breaking down internal silos; intelligent failure;
- broken metrics and better project design (pitch the goal, not the method);
- audience expectations in 2009;
- possible first questions for digital projects and taking a whole museum view for new projects;
- who's talking/listening to your audiences? trust and respect your audiences;
- your museum is an iceberg (lots of the good stuff is hidden);
- (s)mash the system (hold a mashup day);
- and a challenge for your museum – has the web fundamentally changed your organisation?
Frankie Roberto (Rattle)
Went to the conference with a 'fan' hat on, just really enjoys museums. Loved the zoo – live exhibits are interactive, visceral. Role of live interpretation – how could it work with digital technology? Everyone loves dinosaur – Indy Children's Museum. All museums should have a carousel (can't remember what he was going to say about it).
The Power of Children; making a difference – really powerful stories.
Still thinking about the idea of creating visceral experiences.
ArtBabble – shouldn't generally create silos but ArtBabble spotted that YouTube wasn't working for certain types of content.
Davis LAB – kiosks and sofa. Said 'we are on the web'.
Drupal – lots of museums switching to it.
Richard Morgan (V&A) on APIS – ask, what is your museum good at?, and build an API for that – it may not be collections stuff.
'Things to do' page on V&A. Good way of highlighting ways to interact on website.
Semantic data, Aaron's talk on interpretation of bias, relocation from Flickr photos.
Breaking down ideas about authority on where an area is bounded by. OpenStreetMap – wants to add a historical layer to that so can scroll backwards and forwards in time. [I should ask whether this means layering old maps (with older street layouts like pre-Great Fire of London, or earlier representations?). Geo-rectification is expensive because it's time-consuming, but could it be crowdsourced? Geo-locating old images would be easier for the average person to do.]
Open Plaques – alpha project.
Thinks we won't need to digitise in the future as stuff will be born digital (ha, as if! Though it depends where you draw the lines about the end of collections – in my imagination they're like that warehouse scene at the end of Indiana Jones and the Raiders of the Lost Arc and we won't run out of things to properly digitise any time soon. Still, it's a useful question.)
Dan Zambonini (Box UK)
'Every film needs a villain'. In his impressions and insights from MW2009 he'll say things we may or may not agree with.
Slide – stuff we can do vs. stuff we can't do on either side of a gulf of perceived complexity. It's hard to progress from one to the other. Three questions to bridge gap – how to make relevant to everyday job, how to show advantages, how to make it easy.
Then he realised should talk about personal things – people and connections made. About people, stuff that happens in the evening. The evening drinks don't happen at UKMW – it's a shame we have to go to the other side of the world to talk to each other. [It does it you're at an event like mashed museum the day before – another reason to open it up to educators, curators, etc.]
Small museums vs. big museums – [should make stuff accessible to small museums.] Can get value by helping people. (He tells his ex-girlfriend that ) small is the new big. Also small quick wins. Break down the big things into smaller things, find ways can get to them through small changes in behaviour, bits of information.
How small is small? Greater or less than one day. If less than a day, might as well try it. If it's going to take a week, not small.
Museums should share data – not just as API – share data on traffic, spill gossip on marketing costs, etc. [Information is power, etc]
Celebrate failure – admit that some things go wrong.
Bigger picture – be honest. Tell us when to shut up (on e.g. the
If not on twitter, get on it. The more people talking to each other, the more powerful we are as a group. [But what happens if you miss a few days of twitter? I like twitter, but it's inaccessible if you don't have time to constantly keep up, or don't have a computer at home. Still, getting more people talking is an excellentbl point, even if twitter itself doesn't work for some people.]
The sector is missing practical, specific blog, not news and opinions. [Do collections system specific user groups take the place of blogs?]
Use grants to innovate and produce open source stuff. Right now private agencies will take a lot of the strain of applying for grants.
Sort out that copyright stuff. How difficult can it be?
Final slide summing up and last bit of innuendo. 'Beer makes you more attractive' – it's the after sessions stuff at conferences that's so valuable.
Frankie, Dan and Daniel's slides are also available in the 'Museum Tech Pecha Kucha' event on slideshare (and mine has now got an audio track, thanks to Shelley).
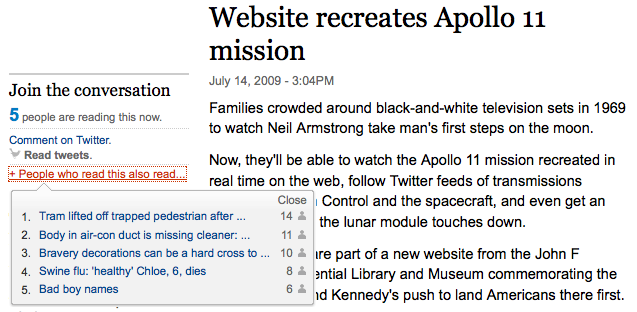
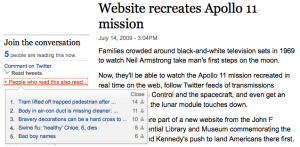 I'm particularly interested in their approach to Twitter. They've used automatically generated hash tags to group together discussion of each article on Twitter. For example, in this article, 'First climate refugees start move to new island home' the hash tag is '#fd-e06x'. If you use their 'Comment on Twitter' link it automatically sends a status to the Twitter site (if you're logged in) with the article URL and '#fd-e06x'.
I'm particularly interested in their approach to Twitter. They've used automatically generated hash tags to group together discussion of each article on Twitter. For example, in this article, 'First climate refugees start move to new island home' the hash tag is '#fd-e06x'. If you use their 'Comment on Twitter' link it automatically sends a status to the Twitter site (if you're logged in) with the article URL and '#fd-e06x'.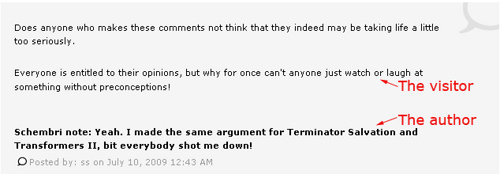
{kind=link}
{kind=link}