I'm at The Albert M. Greenfield Digital Center for the History of Women's Education at Bryn Mawr College for the inaugural Women's History in the Digital World Conference. Since I'm about to speak and ask historians to share their research and write history in public, I thought I should also be brave and share my draft talk notes (which I've now updated with formatted references, though Blogger is still re-formatting things slightly oddly).
Introduction: New challenges in digital history: sharing women's history on Wikipedia
[slide – title, my details]
Hi, I'm Mia. I'm actually doing a PhD on scholarly crowdsourcing, or collaboratively creating online resources, and, thinking about the impact of digitality on the practices of historians, so this paper is indirectly related to my research but isn't core to it.
I proposed this paper as a deliberate provocation: 'if we believe the subjects of our research are important, then we should ensure they are represented on freely available encyclopedic sites like Wikipedia'. Just in case you're not familiar with it, Wikipedia is a free online encyclopedia 'that anyone can edit.' It contains 25 million articles, over 4 million of them in English, but also in 285 other languages, and has 100,000 active contributors[1].
 |
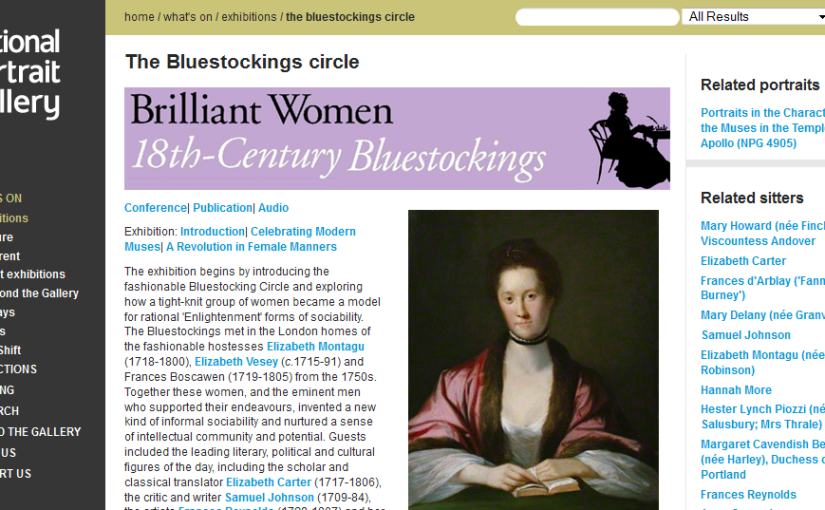
| 'Brilliant Women' at the National Portrait Gallery |
The genesis of this paper was two-fold. The 2008 exhibition 'Brilliant Women: 18th Century Bluestockings' at the UK National Portrait Gallery, made the point that 'Despite the fact that 'bluestockings' made a substantial contribution to the creation and definition of national culture their intellectual participation and artistic interventions have largely been forgotten'. As a computer programmer, reinventing the wheel and other inefficient processes drive me crazy, and I began to think about how digital publishing could intervene in the cycle of remembering and forgetting that seemed to be the fate of brilliant women throughout history. How could historians use digital platforms to stop those histories being lost and to make them easy for others to find?
[Screenshot – Caitlin Moran quote from How to be a woman: 'Even the ardent feminist historian, male or female – citing Amazons and tribal matriarchies and Cleopatra – can't conceal that women have done basically f*ck-all for the last 100,000 years']
A few years later, by then a brand-new PhD student, I attended the Women's History Network conference in London in 2011 and learnt of so many interesting lives that challenged conventional mainstream historical narratives of gender. I wished that others could hear those stories too. But when I asked if any of these histories were available outside academia on sites like Wikipedia, there was a strong sense that editing Wikipedia was something that other people did. But who better to make a case for better representation of women's histories than the people in that room? Who else has the skills, knowledge and the passion? Some academic battles may have been won regarding the importance of women's histories, but representing women's histories on the sites where ordinary people start their queries is hugely important. The quote on this slide illustrates why – even if it was meant in jest, it represents a certain world view.
 |
| WikiWomen's Collaborative |
[slide – logos from http://en.wikipedia.org/wiki/Wikipedia:WikiWomen%27s_History_Month http://meta.wikimedia.org/wiki/WikiWomen%27s_Collaborative ]
Of course, I'm not the first, and definitely not the most qualified to make this point. I would also like to acknowledge the work of many groups and individuals, particularly within Wikipedia, that's preceded this.[2]
[slide – Scripps editathon, #tooFEW]
Things move fast in the digital world and we're at a different moment than the one when I proposed this paper. Gender issues on Wikipedia had been discussed for a number of years but there's been a recent burst of activity, including the #tooFEW ('Feminists Engage Wikipedia') editathons – 'a scheduled time where people edit Wikipedia together, whether offline, online, or a mix of both' – [3], held online and in person across four physical sites.[4] [5] I was going to be provocative and ask you to create Wikipedia entries about the histories you've invested so much in researching, but some of that is happening already. As a result, this is version 2 of this paper, but my starting question remains the same – assuming we believe that women's history is important, what's wrong with our current methods of research dissemination and dialogue?
The case of the Invisible Scholarship
[slide – outline of section]
Cumulative centuries of archival and theoretical work have been spent recovering women's histories, yet much of this inspiring scholarship might as well not exist when so few people have access to it. Sadly, it's currently the case that scholarship that isn't deliberately made public is invisible outside academia. The open access movement, with all its thorny complications, is one potential solution. Engaging in new forms of open scholarship and disseminating research on sites where the public already goes to learn about history is another.
If it's not Googleable, it doesn't exist.
[slide – screenshot of unsuccessful search for Ina von Grumbkow]
Most content searches start and end online. The content and links available to search engines inform their assumptions about the world, and they in turn shape the world view presented on the results screen. If the name of a historical figure doesn't show up in Google, how else would someone find out about them? While college students might be heavy users of Google's specialist Google Scholar search, it's unlikely that people would come across it accidentally, not least because there's a 'semantic gap' between the language used in academia and the language used in everyday speech. Writing for Wikipedia means writing in everyday language, and the site is heavily indexed by search engines – it doesn't take long for content created on Wikipedia – even on a user's talk page and not the main site – to show up in Google results. So one reason to take history on Wikipedia seriously is that it affects what search engines know about the world.
'Did you mean… hegemony?'
 |
| Search for 'Viscountess Ranelagh', Google says 'Did you mean Viscount'. No. |
[slide – screenshot of search for 'Viscountess Ranelagh and the Authorisation of Women's Knowledge in the Hartlib Circle', Google says 'Did you mean Viscount'. No.]
Scholarship and sources contained in specialist online archives and repositories are often off-limits to the Google bots that crawl the web looking for content to index. Because search engines normalise certain assumptions about the world, getting more content about women's histories in publically accessible spaces will eventually have an effect in the algorithms that determine suggestions for 'did you mean' etc. Contributions to sites like Wikipedia can eventually become contributions to the 'knowledge graphs' that determine the answers to questions we ask online.
If it's behind a paywall, it only exists for a privileged few
[Slide – Screenshot of blocked attempt to access 'Wives and daughters of early Berlin geoscientists and their work behind the scenes']
Specialist users will be able to find academic research via Google Scholar, but any independent scholars in attendance will be able to speak to the difficulties in gaining access to journal articles without membership of an institutional library. Journal articles obviously have a lot of value within academic communities, but the research they represent is only available to a privileged few.
Why does Wikipedia matter?
[slide: For some, Wikipedia is the font of all wisdom]
Wikipedia is one of the most visited websites in the world. As one commentator said, 'people turn to Wikipedia as an objective resource' but ' it's not so objective in many ways.'[6]
However, as the free online encyclopedia 'that anyone can edit', it also provides the ability to take direct action to fix the under-representation of women's history. President of the AHA, William Cronon said, 'Wikipedia provides an online home for people interested in histories long marginalized by the traditional academy'[7] – this may not be entirely true yet, but we can hope.
Wikipedia is not yet encyclopedic
[Slide – Ina screenshot]
The English version of Wikipedia has over 4 million articles but it still has some way to go to become truly encyclopedic. Martha Saxton has noted the absence of women's history content on Wikipedia and was distressed by 'its superficiality and inaccuracies when present [8]'. Just as female assistants, secretaries, collectors, illustrators, correspondents, translators, salonists, cataloguers, text book writers, popularisers, explorers, pioneers and colleagues have been left out of traditional academic histories and gradually reclaimed by historians, they are often still invisible on Wikipedia. This may be partly because not enough women edit Wikipedia – as Wikipedia User Gobonobo says, 'editors often contribute to topics they are familiar with and that concern them […] This systemic bias has the potential to exacerbate an historical record that already gives undue emphasis to men.' [9]
The under-representation of women's history undermines Wikipedia's claim to be encyclopedic. Issues include missing entries or omissions in coverage for existing topics, entries with inaccurate content, a failure to represent a truly 'neutral point of view', and a representation of 'male' as the default gender.
Many notable women have been buried in pages titled for their husbands, brothers, tutors, etc. In 1908 Ina von Grumbkow undertook an expedition to Iceland. She later made significant contributions to the field of natural history and wrote several books but other than passing references online and a mention on her husband's Wikipedia page, her story is only available to those with access to sources like the ' Earth Sciences History' journal[10][11].
[Slide: 'Main articles: List of Fellows of the Royal Society and List of female Fellows of the Royal Society '.]
Some of the categories used in Wikipedia posit the default gender as male. For example, there's a ' List of Fellows of the Royal Society ' and ' List of female Fellows of the Royal Society'.
Wikipedia and the challenges of digital history
Writing for Wikipedia encapsulates many, but not all, of the challenges of digital history.
New forms of writing
Writing for Wikipedia calls upon historians to write engaging, intellectually accessible, succinct text that still accurately represents its subject. It not only means valuing the work and skills in writing public history, it requires the ability to write history in public.
Writing for a 'neutral point of view' – one of the key values of Wikipedia – is challenging for historians. Many may find difficult to believe that it's even possible, and it's difficult to achieve [12].
Unlike traditional historical scholarship, characterised by 'possessive individualism' [13] and honed to perfection before publication, Wikipedia entries are considered a work in progress, and anyone who spots an issue is asked to fix it themselves or flag it for others to review.
It won't advance your career
While it might have a large public impact, editing Wikipedia is work that isn't credited in academia, and it takes time that could be used for projects that would count for career advancement. More importantly from Wikipedia's point of view, you can't promote your own work on the site, so writing about your own research interests is not straightforward if not many people have published in your area of expertise.
“On the internet, nobody knows you're a professor”
In a comment with 'pointers for academics who would like to contribute to Wikipedia' on a Chronicle article, commentator 'operalala' said, '"On the internet nobody knows you're a professor." If you're used to deferential treatment at your home institution, you'll be treated like everybody else in the Wide Open Internet.'[14] Or in William Cronon's words, you must 'give up the comfort of credentialed expertise'.[15] Anyone can edit, re-shape or even delete your work.
Just like academia, Wikipedia has ways of establishing the credibility and reputation of a contributor, and just like any other community, there are etiquettes and conventions to observe. As newcomers to the community, Claire Potter warns that it's important not to think of Wikipedia as 'another realm for intellectuals to colonize and professionalize'.[16]
The opportunities and challenges of women's history as public history on Wikipedia
Opportunities
Wikipedia uses red links to represent entries that could be created but don't yet exist. Women's history editathons often create lists of red-linked names as suggested topics that could be created [17] . Projects on and outside Wikipedia, and events at institutions like the Smithsonian and Royal Society and just last weekend at three THATCamps across the United States might be part of a critical mass of people learning how to edit Wikipedia to better include women's history.
Compared to the lengthy process of writing for academic publication, a new Wikipedia entry can be created in a few hours, allowing for time to structure the content and format the references as necessary to pass the first quality bar. An existing entry can be corrected in minutes. Each editathon or personal edit improves the representation of women's history, and there's something very satisfying about turning red links blue.
 |
| Ina von Grumbkow's name red-linked on her husband's Wikipedia page |
Adding the brackets that turn a piece of text into a red link, suggesting the possibility of an entry to be created is a small but potentially powerful intervention. Red links can render the gaps and silences visible.
Resistance
Creating or editing entries on women's history may be relatively easy, but making sure they stay there is less so. There are countless examples of women having to fight to keep changes in as other editors revert them, argue about their choice of sources, the significance or notability of their topic. Wikipedians are zealous in preventing spammers and crackpots polluting the quality of the site, which explains some of the rapid 'nominations for deletion', but some pockets of the site are also hostile to women's history or to women themselves.
Saxton said editing Wikipedia is 'not for the faint of heart' and 'a lesson in how little women's history has penetrated mainstream culture'. There's work to be done in sharing and normalising an understanding of the historical circumstances and cultural contexts that created difficulties for women. We might know that, as Janet Abbate said, 'The laws and social conventions of a given time and place strongly shape the kinds of technical training available to women and men, the career options open to them, their opportunities for advancement and recognition' [18] but until other Wikipedians understand that, there will continue to be issues around 'notability'. Having those conversations as many times as necessary might be tiring and uncomfortable or even controversial, but it's part of the work of representing women's history on Wikipedia.
Tensions
'Reliable sources'
Wikipedians may have different definitions of 'reliable sources' than scholarly researchers. As one academic discovered:
"Wikipedia is not 'truth,' Wikipedia is 'verifiability' of reliable sources. Hence, if most secondary sources which are taken as reliable happen to repeat a flawed account or description of something, Wikipedia will echo that."' [19]
The same gatekeepers matter
As some academics have found, 'Wikipedia differs from primary-source research, from scholarly writing, and how it privileges existing rather than new knowledge' [20] [21] Wikipedia is not the place to redress fundamental issues with silences in the archives or in the profession overall, not least because on Wikipedia, primary research is bad and secondary sources are good [22] . This puts the onus back on to traditional academic publishing in peer-reviewed journals and books that can be cited in Wikipedia articles, though other published works such as 'credible and authoritative books' and 'reputable media sources' can also be cited.
'Notability'
'A person is presumed to be notable if he or she has received significant coverage in reliable secondary sources that are independent of the subject. […] the person who is the topic of a biographical article should be "worthy of notice" – that is, "significant, interesting, or unusual enough to deserve attention or to be recorded" within Wikipedia as a written account of that person's life.' [23] 'The common theme in the notability guidelines is that there must be verifiable, objective evidence that the subject has received significant attention from independent sources to support a claim of notability.' [24] This creates obvious difficulties for some women's histories.
It's also difficult to judge where 'notability' should end. When does focusing on exceptional women become counter-productive? When do we risk creating a new canon? When does it stop being remarkable that a woman became prominent in a field and start being more accepted, if still not expected? [25] At what point should writing shift from individual entries to integration into more general topics?
Conclusion
Sometimes it's hard to tell whether Wikipedia lags behind academia's acceptance and general integration of women's history into mainstream history or whether it is representative of the field's more conservative corners. Recent digital history projects are doing a good job in explaining some of the issues with key sources for Wikipedia like the Oxford Dictionary of National Biography [26] , and I'd hope that this continues. As Martha Saxton said, 'integrating women's experience into broad subjects' is 'both more challenging intellectually and ultimately, more to the point of the overall project of bringing women into our acknowledged history'. [27]
But it's also clearly up to us to make a difference. If it's worth researching the life and achievements of a notable woman, it's worth making sure their contribution to history is available to the world while improving the quality of the world's biggest encyclopaedia. And it doesn't mean going it alone. It's still just Women's History Month so it's not too late to sign up and join one of the women's history projects, or to plan something with your students. [28] [29] [30]
I'd like to close with quotes from two different women. Executive Director of the Wikimedia Foundation, Sue Gardner: 'Wikipedia will only contain 'the sum of all human knowledge' if its editors are as diverse as the population itself: you can help make that happen. And I can't think of anything more important to do, than that.' [31]
And to quote Laura Mandell's keynote yesterday: 'Let's write and publish about each other's projects so that future historians will have those sources to write about. … Nothing changes through thinking alone, only through massive amounts of re-iteration'. [32]
[Update: based on questions afterwards, you may want to get started with Wikipedia:How to run an edit-a-thon, or sign up and say hello at Wikipedia:WikiProject Women's History. You could also join in the Global Women Wikipedia Write-In #GWWI on April 26 (1-3pm, US EST), and they have a handy page on How to Create Wikipedia Entries that Will Stick.
And update April 30, 2013: check out 'Learning to work with Wikipedia – New Pages Patrol and how to create new Wikipedia articles that will stick' by the excellent Adrianne Wadewitz.
Update, June 9: if you're thinking of setting a class assignment involving editing Wikipedia, check out their 'For educators' and 'Assignment Design' pages for tips and contact points. June 18: see also Nicole Beale's 'Wikipedia for Regional Museums'.
Update, August 21, 2013: content on Wikipedia appears to have had an additional boost in Google's search results, making it even more important in shaping the world's knowledge. More at 'The Day the Knowledge Graph Exploded'.
New link, February 2014: Jacqueline Wernimont's Notes for #tooFEW Edit a thon based on a training session by Adrianne Wadewitz are a useful basic introduction to editing.]
References
[11] Mohr, B. A. R. 2010. Wives and daughters of early Berlin geoscientists and their work behind the scenes. Earth Sciences History 29 (2): 291–310.
[14] Operalala on Messer-Kruse, 2012 [15] Cronon, 2012.
[18] Janet Abbate, "Guest Editor's Introduction: Women and Gender in the History of Computing," IEEE Annals of the History of Computing, vol. 25, no. 4, pp. 4-8, October-December, 2003
[19] Messer-Kruse, 2012.
[21] Messer-Kruse, 2012.
[24] Various. 2013. ‘Wikipedia:Notability’.
Wikipedia. https://en.wikipedia.org/wiki/Wikipedia:NOTE
[25]
Or as Christie Aschwanden
says when proposing the 'Finkbeiner test' for contemporary journalism about women in science, 'treating female scientists as special cases only perpetuates the idea that there’s something extraordinary about a woman doing science'. Aschwanden, Christie. 2013. ‘The Finkbeiner Test’.
Double X Science. March 5.
http://www.doublexscience.org/the-finkbeiner-test/ [27] Saxton, 2012