Over time I've noticed the repetition of various misconceptions and apprehensions about crowdsourcing for cultural heritage and digital history, so since this is a large part of my PhD topic I thought I'd collect various resources together as I work to answer some FAQs. I'll update this post over time in response to changes in the field, my research and comments from readers. While this is partly based on some writing for my PhD, I've tried not to be too academic and where possible I've gone for publicly accessible sources like blog posts rather than send you to a journal paywall.
If you'd rather watch a video than read, check out the Crowdsourcing Consortium for Libraries and Archives (CCLA)'s 'Crowdsourcing 101: Fundamentals and Case Studies' online seminar.
[Last updated: February 2016, to address 'crowdsourcing steals jobs'. Previous updates added a link to CCLA events, crowdsourcing projects to explore and a post on machine learning+crowdsourcing.]
What is crowdsourcing?
Definitions are tricky. Even Jeff Howe, the author of 'Crowdsourcing' has two definitions:
The White Paper Version: Crowdsourcing is the act of taking a job traditionally performed by a designated agent (usually an employee) and outsourcing it to an undefined, generally large group of people in the form of an open call.
The Soundbyte Version: The application of Open Source principles to fields outside of software.
For many reasons, the term 'crowdsourcing' isn't appropriate for many cultural heritage projects but the term is such neat shorthand that it'll stick until something better comes along. Trevor Owens (@tjowens) has neatly problematised this in The Crowd and The Library:
'Many of the projects that end up falling under the heading of crowdsourcing in libraries, archives and museums have not involved large and massive crowds and they have very little to do with outsourcing labor. … They are about inviting participation from interested and engaged members of the public [and] continue a long standing tradition of volunteerism and involvement of citizens in the creation and continued development of public goods'
Defining crowdsourcing in cultural heritage
To summarise my own thinking and the related literature, I'd define crowdsourcing in cultural heritage as an emerging form of engagement with cultural heritage that contributes towards a shared, significant goal or research area by asking the public to undertake tasks that cannot be done automatically, in an environment where the tasks, goals (or both) provide inherent rewards for participation.

Who is 'the crowd'?
Good question! One tension underlying the 'openness' of the call to participate in cultural heritage is the fact that there's often a difference between the theoretical reach of a project (i.e. everybody) and the practical reach, the subset of 'everybody' with access to the materials needed (like a computer and an internet connection), the skills, experience and time… While 'the crowd' may carry connotations of 'the mob', in 'Digital Curiosities: Resource Creation Via Amateur Digitisation', Melissa Terras (@melissaterras) points out that many 'amateur' content creators are 'extremely self motivated, enthusiastic, and dedicated' and test the boundaries between 'between definitions of amateur and professional, work and hobby, independent and institutional' and quotes Leadbeater and Miller's 'The Pro-Am Revolution' on people who pursue an activity 'as an amateur, mainly for the love of it, but sets a professional standard'.
There's more and more talk of 'community-sourcing' in cultural heritage, and it's a useful distinction but it also masks the fact that nearly all crowdsourcing projects in cultural heritage involve a community rather than a crowd, whether they're the traditional 'enthusiasts' or 'volunteers', citizen historians, engaged audiences, whatever. That said, Amy Sample Ward has a diagram that's quite useful for planning how to work with different groups. It puts the 'crowd' (people you don't know), 'network' (the community of your community) and 'community' (people with a relationship to your organisation) in different rings based on their closeness to you.
'The crowd' is differentiated not just by their relationship to your organisation, or by their skills and abilities, but their motivation for participating is also important – some people participate in crowdsourcing projects for altruistic reasons, others because doing so furthers their own goals.
I'm worried about about crowdsourcing because…
…isn't letting the public in like that just asking for trouble?
@lottebelice said she'd heard people worry that 'people are highly likely to troll and put in bad data/content/etc on purpose' – but this rarely happens. People worried about this with user-generated content, too, and while kids in galleries delight in leaving rude messages about each other, it's rare online.
It's much more likely that people will mistakenly add bad data, but a good crowdsourcing project should build any necessary data validation into the project. Besides, there are generally much more interesting places to troll than a cultural heritage site.
And as Matt Popke pointed out in a comment, 'When you have thousands of people contributing to an entry you have that many more pairs of eyes watching it. It's like having several hundred editors and fact-checkers. Not all of them are experts, but not all of them have to be. The crowd is effectively self-policing because when someone trolls an entry, somebody else is sure to notice it, and they're just as likely to fix it or report the issue'. If you're really worried about this, an earlier post on Designing for participatory projects: emergent best practice' has some other tips.
…doesn't crowdsourcing take advantage of people?
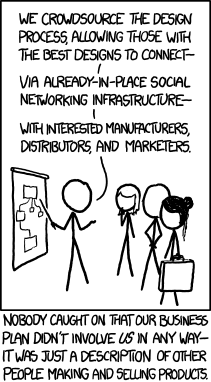
Sadly, yes, some of the activities that are labelled 'crowdsourcing' do. Design competitions that expect lots of people to produce full designs and pay a pittance (if anything) to the winner are rightly hated. (See antispec.com for more and a good list of links).
But in cultural heritage, no. Museums, galleries, libraries, archives and academic projects are in the fortunate position of having interesting work that involves an element of social good, and they also have hugely varied work, from microtasks to co-curated research projects. Crowdsourcing is part of a long tradition of volunteering and altruistic participation, and to quote Owens again, 'Crowdsourcing is a concept that was invented and defined in the business world and it is important that we recast it and think through what changes when we bring it into cultural heritage.'
[Update, May 2013: it turns out museums aren't immune from the dangers of design competitions and spec work: I've written On the trickiness of crowdsourcing competitions to draw some lessons from the Sydney Design competition kerfuffle.]
Anyway, crowdsourcing won't usually work if it's not done right. From A Crowd Without Community – Be Wary of the Mob:
"when you treat a crowd as disposable and anonymous, you prevent them from achieving their maximum ability. Disposable crowds create disposable output. Simply put: crowds need a sense of identity and community to achieve their potential."
…crowdsourcing can't be used for academic work
Reasons given include 'humanists don't like to share their knowledge' with just anyone. And it's possible that they don't, but as projects like Transcribe Bentham and Trove show, academics and other researchers will share the work that helps produce that knowledge. (This is also something I'm examining in my PhD. I'll post some early findings after the Digital Humanities 2012 conference in July).
Looking beyond transcription and other forms of digitisation, it's worth checking out Prism, 'a digital tool for generating crowd-sourced interpretations of texts'.
…it steals jobs
Once upon a time, people starting a career in academia or cultural heritage could get jobs as digitisation assistants, or they could work on a scholarly edition. Sadly, that's not the case now, but that's probably more to do with year upon year of funding cuts. Blame the bankers, not the crowdsourcers.
The good news? Crowdsourcing projects can create jobs – participatory projects need someone to act as community liaison, to write the updates that demonstrate the impact of crowdsourced contributions, to explain the research value of the project, to help people integrate it into teaching, to organise challenges and editathons and more.
What isn't crowdsourcing?
…'the wisdom of the crowds'?
Which is not just another way of saying 'crowd psychology', either (another common furphy). As Wikipedia puts it, 'the wisdom of the crowds' is based on 'diverse collections of independently-deciding individuals'. Handily, Trevor Owens has just written a post addressing the topic: Human Computation and Wisdom of Crowds in Cultural Heritage.
…user-generated content
So what's the difference between crowdsourcing and user-generated content? The lines are blurry, but crowdsourcing is inherently productive – the point is to get a job done, whether that's identifying people or things, creating content or digitising material.
Conversely, the value of user-generated content lies in the act of creating it rather than in the content itself – for example, museums might value the engagement in a visitor thinking about a subject or object and forming a response to it in order to comment on it. Once posted it might be displayed as a comment or counted as a statistic somewhere but usually that's as far as it goes.
And @sherah1918 pointed out, there's a difference between asking for assistance with tasks and asking for feedback or comments: 'A comment book or a blog w/comments isn't crowdsourcing to me … nor is asking ppl to share a story on a web form. That is a diff appr to collecting & saving personal histories, oral histories'.
…other things that aren't crowdsourcing:
[Heading inspired by Sheila Brennan @sherah1918]
- Crowdfunding (it's often just asking for micro-donations, though it seems that successful crowdfunding projects have a significant public engagement component, which brings them closer to the concerns of cultural heritage organisations. It's also not that new. See Seventeenth-century crowd funding for one example.)
- Data-mining social media and other content (though I've heard this called 'passive' or 'implict' crowdsourcing)
- Human computation (though it might be combined with crowdsourcing)
- Collective intelligence (though it might also be combined with crowdsourcing)
- General calls for content, help or participation (see 'user-generated content') or vaguely asking people what they think about an idea. Asking for feedback is not crowdsourcing. Asking for help with your homework isn't crowdsourcing, as it only benefits you.
- Buzzwords applied to marketing online. And as @emmclean said, "I think many (esp mkting) see "crowdsourcing" as they do "viral" – just happens if you throw money at it. NO!!! Must be great idea" – it must make sense as a crowdsourced task.
Ok, so what's different about crowdsourcing in cultural heritage?
For a start, the process is as valuable as the result. Owens has a great post on this, Crowdsourcing Cultural Heritage: The Objectives Are Upside Down, where he says:
'The process of crowdsourcing projects fulfills the mission of digital collections better than the resulting searches… Far better than being an instrument for generating data that we can use to get our collections more used it is actually the single greatest advancement in getting people using and interacting with our collections. … At its best, crowdsourcing is not about getting someone to do work for you, it is about offering your users the opportunity to participate in public memory … it is about providing meaningful ways for the public to enhance collections while more deeply engaging and exploring them'.
And as I've said elsewhere, ' playing [crowdsourcing] games with museum objects can create deeper engagement with collections while providing fun experiences for a range of audiences'. (For definitions of 'engagement' see The Culture and Sport Evidence (CASE) programme. (2011). Evidence of what works: evaluated projects to drive up engagement (PDF).)
What about cultural heritage and citizen science?
[This was written in 2012. I've kept it for historical reasons but think differently now.]
First, another definition. As Fiona Romeo writes, 'Citizen science projects use the time, abilities and energies of a distributed community of amateurs to analyse scientific data. In doing so, such projects further both science itself and the public understanding of science'. As Romeo points out in a different post, 'All citizen science projects start with well-defined tasks that answer a real research question', while citizen history projects rarely if ever seem to be based around specific research questions but are aimed more generally at providing data for exploration. Process vs product?
I'm still thinking through the differences between citizen science and citizen history, particularly where they meet in historical projects like Old Weather. Both citizen science and citizen history achieve some sort of engagement with the mindset and work of the equivalent professional occupations, but are the traditional differences between scientific and humanistic enquiry apparent in crowdsourcing projects? Are tools developed for citizen science suitable for citizen history? Does it make a difference that it's easier to take a new interest in history further without a big investment in learning and access to equipment?
I have a feeling that 'citizen science' projects are often more focused on the production of data as accurately and efficiently as possible, and 'citizen history' projects end up being as much about engaging people with the content as it is about content production. But I'm very open to challenges on this…
What kind of cultural heritage stuff can be crowdsourced?
I wrote this list of 'Activity types and data generated' over a year ago for my Masters dissertation on crowdsourcing games for museums and a subsequent paper for Museums and the Web 2011, Playing with Difficult Objects – Game Designs to Improve Museum Collections (which also lists validation types and requirements). This version should be read in the light of discussion about the difference between crowdsourcing and user-generated content and in the context of things people can do with museums and with games, but it'll do for now:
| Activity | Data generated |
| Tagging (e.g. steve.museum, Brooklyn Museum Tag! You're It; variations include two-player 'tag agreement' games like Waisda?, extensions such as guessing games e.g. GWAP ESP Game, Verbosity, Tiltfactor Guess What?; structured tagging/categorisation e.g. GWAP Verbosity, Tiltfactor Cattegory) | Tags; folksonomies; multilingual term equivalents; structured tags (e.g. 'looks like', 'is used for', 'is a type of'). |
| Debunking (e.g. flagging content for review and/or researching and providing corrections). | Flagged dubious content; corrected data. |
| Recording a personal story | Oral histories; contextualising detail; eyewitness accounts. |
| Linking (e.g. linking objects with other objects, objects to subject authorities, objects to related media or websites; e.g. MMG Donald). | Relationship data; contextualising detail; information on history, workings and use of objects; illustrative examples. |
| Stating preferences (e.g. choosing between two objects e.g. GWAP Matchin; voting on or 'liking' content). | Preference data; subsets of 'highlight' objects; 'interestingness' values for content or objects for different audiences. May also provide information on reason for choice. |
| Categorising (e.g. applying structured labels to a group of objects, collecting sets of objects or guessing the label for or relationship between presented set of objects). | Relationship data; preference data; insight into audience mental models; group labels. |
| Creative responses (e.g. write an interesting fake history for a known object or purpose of a mystery object.) | Relevance; interestingness; ability to act as social object; insight into common misconceptions. |
You can also divide crowdsourcing projects into 'macro' and 'micro' tasks – giving people a goal and letting them solve it as they prefer, vs small, well-defined pieces of work, as in the 'Umbrella of Crowdsourcing' at The Daily Crowdsource and there's a fair bit of academic literature on other ways of categorising and describing crowdsourcing.
Using crowdsourcing to manage crowdsourcing
There's also a growing body of literature on ecosystems of crowdsourcing activities, where different tasks and platforms target different stages of the process. A great example is Brooklyn Museum’s ‘Freeze Tag!’, a game that cleans up data added in their tagging game. An ecosystem of linked activities (or games) can maximise the benefits of a diverse audience by providing a range of activities designed for different types of participant skills, knowledge, experience and motivations; and can encompass different levels of participation from liking, to tagging, finding facts and links.
A participatory ecosystem can also resolve some of the difficulties around validating specialist tags or long-form, more subjective content by circulating content between activities for validation and ranking for correctness, 'interestingness' (etc) by other players (see for example the 'Contributed data lifecycle' diagram on my MW2011 paper or the 'Digital Content Life Cycle' for crowdsourcing in Oomen and Aroyo's paper below). As Nina Simon said in The Participatory Museum, 'By making it easy to create content but impossible to sort or prioritize it, many cultural institutions end up with what they fear most: a jumbled mass of low-quality content'. Crowdsourcing the improvement of cultural heritage data would also make possible non-crowdsourcing engagement projects that need better content to be viable.
See also Raddick, MJ, and Georgia Bracey. 2009. “Citizen Science: Status and Research Directions for the Coming Decade” on bridging between old and new citizen science projects to aid volunteer retention, and Nov, Oded, Ofer Arazy, and David Anderson. 2011. “Dusting for Science: Motivation and Participation of Digital Citizen Science Volunteers” on creating 'dynamic contribution environments that allow volunteers to start contributing at lower-level granularity tasks, and gradually progress to more demanding tasks and responsibilities'.
What does the future of crowdsourcing hold?
Platforms aimed at bootstrapping projects – that is, getting new projects up and running as quickly and as painlessly as possible – seem to be the next big thing. Designing tasks and interfaces suitable for mobile and tablets will allow even more of us to help out while killing time. There's also a lot of work on the integration of machine learning and human computation; my post 'Helping us fly? Machine learning and crowdsourcing' has more on this.
Find out how crowdsourcing in cultural heritage works by exploring projects
Spend a few minutes with some of the projects listed in Looking for (crowdsourcing) love in all the right places to really understand how and why people participate in cultural heritage crowdsourcing.
Where can I find out more? (AKA, a reading list in disguise)
- Read the original article about crowdsourcing, published in the June, 2006 issue of Wired Magazine or Jeff Howe's book, Crowdsourcing: why the power of the crowd is driving the future of business.
- My MW2011 paper, Playing with Difficult Objects – Game Designs to Improve Museum Collections and (deep breath) I've posted my MSc dissertation 'Playing with difficult objects: game designs for crowdsourcing museum metadata' online
- From tagging to theorizing: deepening engagement with cultural heritage through crowdsourcing. Curator: The Museum Journal, 56(4) pp. 435–450 (Mia Ridge; link is to university repository version for those who don't have access to Curator)
- Workshop activities and notes for 'Crowdsourcing in Libraries, Museums and Cultural Heritage Institutions' (for the British Library's Digital Scholarship programme)
- Trevor Owens' blog on 'User Centered Digital History'
- Rose Holley's (of Trove fame) blog
- @benwbrum's Collaborative Manuscript Transcription blog
- Peer-to-peer foundation crowdsourcing page
- steve.museum reports – the first museum tagging project
- Why Crowdsourcing? Why Scripto?
- Clay Shirky, Cognitive Surplus: Creativity and Generosity in a Connected Age
- Crowdsourcing in the Cultural Heritage Domain: Opportunities and Challenges, by Johan Oomen and Lora Aroyo (PDF).
- Bringing Citizen Scientists and Historians Together
- Final report on 'crowd-sourcing in the humanities' of the AHRC Crowd Sourcing Study
- Accessible resources on doing crowdsourcing well: try How to Effectively Use Incentives in your Crowdsourcing Project, The Magic of Participation, Building and Maintaining a Vibrant, Creative Crowd.
- If you're into mapping, geography or just geospatial work, check out volunteered geographic information (VGI).
- Crowdfunding Culture: Namaste, and Welcome to the Smithsonian lists a hit (yoga, a popular topic) and a miss in crowdfunding at the Smithsonian. You might also find CrowdFunding Website Reviews useful.
There's a lot of academic literature on all kinds of aspects of crowdsourcing, but I've gone for sources that are accessible both intellectually and in terms of licensing. If a key reference isn't there, it might be because I can't find a pre-print or whatever outside a paywall – let me know if you know of one!
 Liked this post? Buy the book! 'Crowdsourcing Our Cultural Heritage' is available through Ashgate or your favourite bookseller…
Liked this post? Buy the book! 'Crowdsourcing Our Cultural Heritage' is available through Ashgate or your favourite bookseller…
Thanks, and over to you!
Thanks to everyone who responded to my call for their favourite 'misconceptions and apprehensions about crowdsourcing (esp in history and cultural heritage)', and to those who inspired this post in the first place by asking questions in various places about the negative side of crowdsourcing. I'll update the post as I hear of more, so let me know your favourites. I'll also keep adding links and resources as I hear of them.
You might also be interested in: Notes from 'Crowdsourcing in the Arts and Humanities' and various crowdsourcing classes and workshops I've run over the past few years.