Explaining by analogy: Miko Coffey summarises the semantic web as:
- Web 1.0 is like buying a can of Campbell's Soup
- Web 2.0 is like making homemade soup and inviting your soup-loving friends over
- The semantic web is like having a dinner party, knowing that Tom is allergic to gluten, Sally is away til next Thursday and Bob is vegetarian.
And she's got a great image in the same post to help explain it.
To extend the analogy, it's also as if the semantic web could understand that when your American aunt's soup recipe says 'cilantro', you'd look for 'coriander' in shops in Australia or the UK.
Explaining by doing: this review 'Why I Migrated Over to Twine (And Other Social Services Bit the Dust)' of Twine gives lots of great examples of how semantic web stuff can help us:
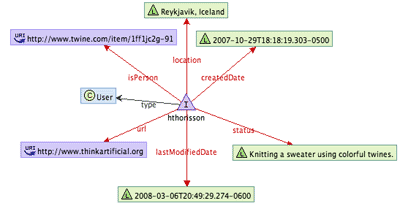
So for example when Stanley Kubrick is mentioned in the bookmarklet fields, or in the document you upload, or in the email you send into Twine — the system will analyze and identify him as a person (not as a mere keyword). This is called entity extraction and is applied to all text on Twine.
Under the hood, a person is defined in a larger ontology in relation to other things. Here’s an example of a very small portion of my own graph within Twine:
Some may not find the point of this clear. So to explain: Just as HTML enables computers to display data — this extra semantic information markup (RDF, OWL, etc.) enables computers to understand what the data is they’re displaying. And moreover, to understand what things are in relation to other things.
Example Search
For an example, when we search for “Stanley Kubrick” on regular search engines, the words “Stanley” and “Kubrick” are usually regarded as mere keywords: a series of letters that the search engine then tries to find pages with those series of letters. But in the world of semantic web, the engines know “Stanley Kubrick” is a person. This results in a lot less irrelevant items from the search’s results….If you weren’t already aware, the systems I just described above are the basic semantic web concept: Encapsulating data in a new layer of machine processable information to help us search, find and organize the overwhelming and ever-growing sea of pictures, videos, text and whatever else we’re creating.

{kind=link}
I think these are both useful when explaining the benefits of the semantic web to non-geeks and may help overcome some of the fear of the unknown (or fear of investment in the pointless buzzword) we might encounter. If we believe in the semantic web, it's up to us to explain it properly to other people it's going to effect.
I also discovered a good post by Mike on the 'Innovation Manifesto'.
Very useful analogy. I'm in the middle of trying to move our team into this mindset for some search / browse work we're doing, and I've been stuck sometimes trying to explain why it's important to know what the words "mean" rather than just using them as keywords. Of course, getting that meaning extracted is another story, but… :)
I keep wondering if the museum sector could work with something like OpenCalais to teach it our vocabulary so it gets better at pulling out cultural heritage specific concepts/keywords… The Powerhouse example demonstrates that it can provide a 'good enough' place to start.
Bryan at the SMM had a good link to another review of Twine: http://tinyurl.com/2abbql