I noticed the following link when reading a BBC article today:
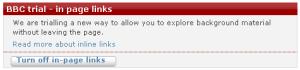
If you turn on inline links, they appear as subtly blue text against the usual grey. Some have icons indicating which site the link relates to (YouTube, Wikipedia), others don't. Links with an icon open the content directly over the article; links without icons open the link in the same window, taking you from the BBC story. Screenshot below:
The 'Read more' links to a page, Story links trial, that says:
For a limited period the BBC News Website is experimenting with clickable links within the body of news stories.
If you click on one of these links, a window will appear containing background material relevant to that word that is highlighted. The links have been carefully chosen by our journalists.
We are doing this trial because we want to see if you enjoy exploring background material presented in this way. It's part of our continuing efforts to provide the best possible experience.
In addition to background material from the BBC News website, we are also displaying content from other sites, including Wikipedia, You Tube and Flickr.
I'd be really interested to know what the results of the trial are, and I hope the BBC share them. I've been thinking about inline links and faceted browsing for collections sites recently, and while the response would presumably vary if the links were only to related content on the same site, it would be useful to know how the two types of links are received.
The story I noticed the link on is also interesting because it shows how content created in a 'social software' way can be (probably wilfully, in this case) misinterpreted:
"Downing Street has been accused of wasting taxpayers' money after making a jokey video in response to a petition for Jeremy Clarkson to be made PM.
…
A Conservative Party spokesman said: "While the British public is having to tighten its belts, the government is spending taxpayers' money on a completely frivolous project.""