
Enriching cultural heritage collections through a Participatory Commons platform: a provocation about collaborating with users
Mia Ridge, Open University Contact me: @mia_out or https://miaridge.com/
 Today I'd like to present both a proposal for something called the 'Participatory Commons', and a provocation (or conversation starter): there's a paradox in our hopes for deeper audience engagement through crowdsourcing: projects that don't grow with their participants will lose them as they develop new skills and interests and move on. This talk presents some options for dealing with this paradox and suggests a Participatory Commons provides a way to take a sector-wide view of active engagement with heritage content and redefine our sense of what it means when everybody wins.
Today I'd like to present both a proposal for something called the 'Participatory Commons', and a provocation (or conversation starter): there's a paradox in our hopes for deeper audience engagement through crowdsourcing: projects that don't grow with their participants will lose them as they develop new skills and interests and move on. This talk presents some options for dealing with this paradox and suggests a Participatory Commons provides a way to take a sector-wide view of active engagement with heritage content and redefine our sense of what it means when everybody wins.
I'd love to hear your thoughts about this – I'll be following the hashtag during the session and my contact details are above.
Before diving in, I wanted to reflect on some lessons from my work in museums on public engagement and participation.
My philosophy for crowdsourcing in cultural heritage (aka what I've learnt from making crowdsourcing games)
 One thing I learnt over the past years: museums can be intimidating places. When we ask for help with things like tagging or describing our collections, people want to help but they worry about getting it wrong and looking stupid or about harming the museum.
One thing I learnt over the past years: museums can be intimidating places. When we ask for help with things like tagging or describing our collections, people want to help but they worry about getting it wrong and looking stupid or about harming the museum.
The best technology in the world won't solve a single problem unless it's empathically designed and accompanied by social solutions. This isn't a talk about technology, it's a talk about people – what they want, what they're afraid of, how we can overcome all that to collaborate and work together.
Dora's Lost Data
So a few years ago I explored the potential of crowdsourcing games to make helping a museum less scary and more fun. In this game, 'Dora's Lost Data', players meet a junior curator who asks them to tag objects so they'll be findable in Google. Games aren't the answer to everything, but identifying barriers to participation is always important. You have to understand your audiences – their motivations for starting and continuing to participate; the fears, anxieties, uncertainties that prevent them participating. [My games were hacked together outside of work hours, more information is available at My MSc dissertation: crowdsourcing games for museums; if you'd like to see more polished metadata games check out Tiltfactor's http://www.metadatagames.org/#games]
Mutual wins – everybody's happy
My definition of crowdsourcing: cultural heritage crowdsourcing projects ask the public to undertake tasks that cannot be done automatically, in an environment where the activities, goals (or both) provide inherent rewards for participation, and where their participation contributes to a shared, significant goal or research area.
It helps to think of crowdsourcing in cultural heritage as a form of volunteering. Participation has to be rewarding for everyone involved. That sounds simple, but focusing on the audiences' needs can be difficult when there are so many organisational needs competing for priority and limited resources for polishing the user experience. Further, as many projects discover, participant needs change over time…
What is a Participatory Commons and why would we want one?
First, I have to introduce you to some people. These are composite stories (personas) based on my research…
Two archival historians, Simone and Andre. Simone travels to archives in her semester breaks to stock up on research material, taking photos of most documents 'in case they're useful later', transcribing key text from others. Andre is often at the next table, also looking for material for his research. The documents he collected for his last research project would be useful for Simone's current book but they've never met and he has no way of sharing that part of his 'personal research collection' with her. Currently, each of these highly skilled researchers take their cumulative knowledge away with them at the end of the day, leaving no trace of their work in the archive itself. Next…
Two people from a nearby village, Martha and Bob. They joined their local history society when they retired and moved to the village. They're helping find out what happened to children from the village school's class of 1898 in the lead-up to and during World War I. They are using census returns and other online documents to add records to a database the society's secretary set up in Excel. Meanwhile…

A family historian, Daniel. He has a classic 'shoebox archive' – a box containing his grandmother Sarah's letters and diary, describing her travels and everyday life at the turn of the century. He's transcribing them and wants to put them online to share with his extended family. One day he wants to make a map for his kids that shows all the places their great-grandmother lived and visited. Finally, there's…
Crowdsourcer Nisha.She has two young kids and works for a local authority. She enjoys playing games like Candy Crush on her mobile, and after the kids have gone to bed she transcribes ship logs on the Old Weather website while watching TV with her husband. She finds it relaxing, feels good about contributing to science and enjoys the glimpses of life at sea. Sites like Old Weather use 'microtasks' – tiny, easily accomplished tasks – and crowdsourcing to digitise large amounts of text.
Helping each other?
None of our friends above know it, but they're all looking at material from roughly the same time and place. Andre and Simone could help each other by sharing the documents they've collected over the years. Sarah's diaries include the names of many children from her village that would help Martha and Bob's project, and Nisha could help everyone if she transcribed sections of Sarah's diary.
Connecting everyone's efforts for the greater good: Participatory Commons
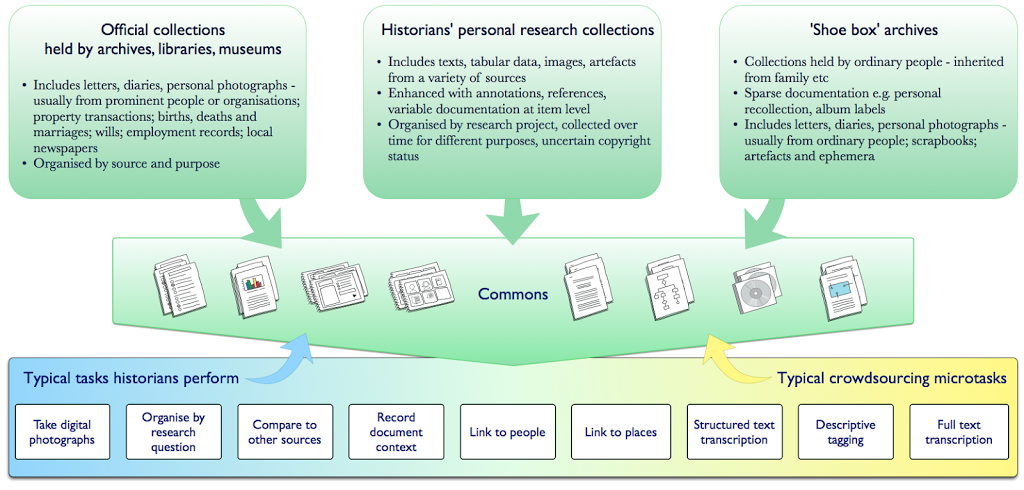
This image shows the two main aspects of the Participatory Commons: the different sources for content, and the activities that people can do with that content.
 |
| The Participatory Commons (image: Mia Ridge) |
The Participatory Commons is a platform where content from different sources can be aggregated. Access to shared resources underlies the idea of the 'Commons', particularly material that is not currently suitable for sites like Europeana, like 'shoebox archives' and historians' personal record collections. So if the 'Commons' part refers to shared resources, how is it participatory?
The Participatory Commons interface supports a range of activities, from the types of tasks historians typically do, like assessing and contextualising documents, activities that specialists or the public can do like identifying particular people, places, events or things in sources, or typical crowdsourcing tasks like fulltext transcription or structured tagging.
By combining the energy of crowdsourcing with the knowledge historians create on a platform that can store or link to primary sources from museums, libraries and archives with 'shoebox archives', the Commons could help make our shared heritage more accessible to all. As a platform that makes material about ordinary people available alongside official archives and as an interface for enjoyable, meaningful participation in heritage work, the Commons could be a basis for 'open source history', redressing some of the absences in official archives while improving the quality of all records.
As a work in progress, this idea of the Participatory Heritage Commons has two roles: an academic thought experiment to frame my research, and as a provocation for GLAMs (galleries, museums, libraries, archives) to think outside their individual walls. As a vision for 'open source history', it's inspired by community archives, public history, participant digitisation and history from below… This combination of a large underlying repository and more intimate interfaces could be quite powerful. Capturing some of the knowledge generated when scholars access collections would benefit both archives and other researchers.
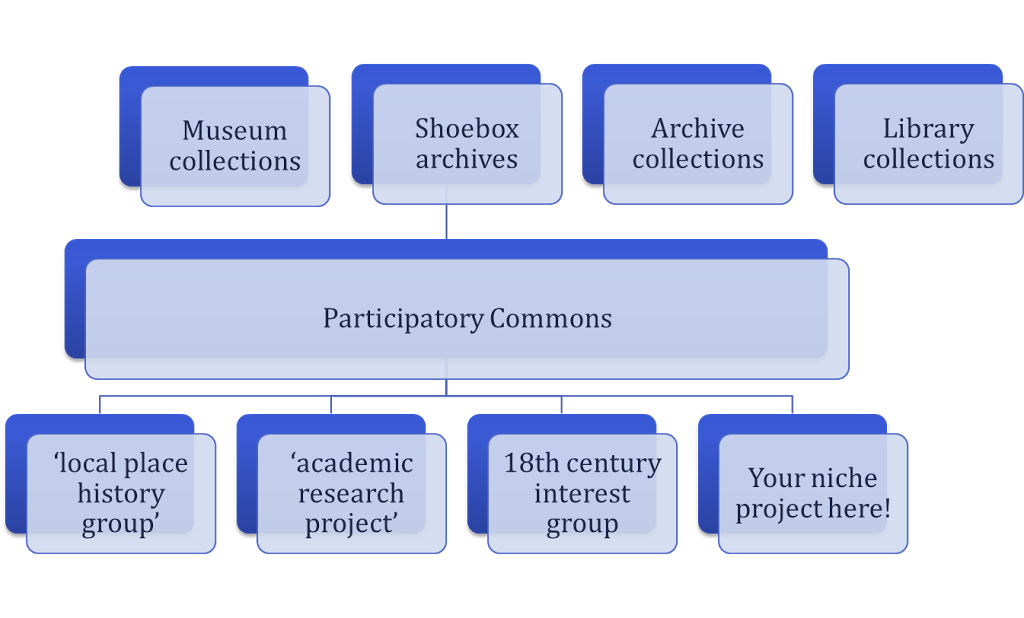
'Niche projects' can be built on a Participatory Commons
As a platform for crowdsourcing, the Participatory Commons provides efficiencies of scale in the backend work for verifying and validating contributions, managing user accounts, forums, etc. But that doesn't mean that each user would experience the same front-end interface.
 |
|
|
My research so far suggests that tightly-focused projects are better able to motivate participants and create a sense of community. These 'niche' projects may be related to a particular location, period or topic, or to a particular type of material. The success of the New York Public Library's What's on the Menu project, designed around a collection of historic menus, and the British Library's GeoReferencer project, designed around their historic map collection, both demonstrate the value of defining projects around niche topics.
The best crowdsourcing projects use carefully designed interactions tailored to the specific content, audience and data requirements of a given project. These interactions are usually For example, the Zooniverse body of projects use much of the same underlying software but projects are designed around specific tasks on specific types of material, whether classifying simple galaxy types, plankton or animals on the Serengeti, or transcribing ship logs or military diaries.
The Participatory Commons is not only a collection of content, it also allows 'niche' projects to be layered on top, presenting more focused sets of content, and specialist interfaces designed around the content, audience and purpose.
Barriers
But there are still many barriers to consider, including copyright and technical issues and important cultural issues around authority, reliability, trust, academic credit and authorship. [There's more background on this at my earlier post on historians and the Participatory Commons and Early PhD findings: Exploring historians' resistance to crowdsourced resources.]
Now I want to set the idea of the Participatory Commons aside for a moment, and return to crowdsourcing in cultural heritage. I've been looking for factors in the success or otherwise of crowdsourcing projects, from grassroots, community-lead projects to big glamorous institutionally-lead sites.
I mentioned that Nisha found transcribing text relaxing. Like many people who start transcribing text, she found herself getting interested in the events, people and places mentioned in the text. Forums or other methods for participants to discuss their questions seem to help keep participants motivated, and they also provide somewhere for a spark of curiosity to grow (as in this forum post). We know that some people on crowdsourcing projects like Old Weather get interested in history, and even start their own research projects.
Crowdsourcing as gateway to further activity
You can see that happening on other crowdsourcing projects too. For example, Herbaria@Homeaims to document historical herbarium collections within museums based on photographs of specimen cards. So far participants have documented over 130,000 historic specimens. In the process, some participants also found themselves being interested in the people whose specimens they were documenting.
As a result, the project has expanded to include biographies of the original specimen collectors. It was able to accommodate this new interest through a project wiki, which has a combination of free text and structured data linking records between the transcribed specimen cards and individual biographies.
'Levels of Engagement' in citizen science
There's a consistent enough pattern in science crowdsourcing projects that there's a model from 'citizen science' that outlines different stages participants can move through, from undertaking simple tasks, joining in community discussion, through to 'working independently on self-identified research projects'.[1]
Is this 'mission accomplished'?
This is Nick Poole's word cloud based on 40 museum missionstatements. With words like 'enjoyment', 'access', 'learning' appearing in museum missions, doesn't this mean that turning transcribers into citizen historians while digitising and enhancing collections is a success? Well, yes, but…
Paths diverge; paradox ahead?

Who has agency?
If people move beyond simple tasks into more complex tasks that require a greater investment of time and learning, then issues of agency – participants' ability to make choices about what they're working on and why – start to become more important. Would Wikipedia have succeeded if it dictated what contributors had to write about? We shouldn't mistake volunteers for a workforce just because they can be impressively dedicated contributors.
Participatory project models
Turning again to citizen science – this time public participation in science research, we have a model for participatory projects according to the amount of control participants have over the design of the project itself – or to look at it another way, how much authority the organisation has ceded to the crowd. This model contains three categories: 'contributory', where the public contributes data to a project designed by the organisation; 'collaborative', where the public can help refine project design and analyse data in a project lead by the organisation; and 'co-creative', where the public can take part in all or nearly all processes, and all parties design the project together.[2]
As you can imagine, truly co-creative projects are rare. It seems cultural organisations find it hard to truly collaborate with members of the public; for many understandable reasons. The level of transparency required, and the investment of time for negotiating mutual interests, goals and capabilities increase as collaboration deepens. Institutional constraints and lack of time to engage in deep dialogue with participants make it difficult to find shared goals that work for all parties. It seems GLAMs sometimes try to take shortcuts and end up making decisions for the group, which means their 'co-creative' project is actually more just 'collaborative'.
New challenges
When participants start to out-grow the tasks that originally got them hooked, projects face a choice. Some projects are experimenting with setting challenges for participants. Here you see 'mysteries' set by the UK's Museum of Design in Plastics, and by San FranciscoPublic Library on History Pin. Finding the right match between the challenge set and the object can be difficult without some existing knowledge of the collection, and it can require a lot of on-going time to encourage participants. Putting the mystery under the nose of the person who has the knowledge or skills to solve it is another challenge that projects like this will have to tackle.
Working with existing communities of interest is a good start, but it also takes work to figure out where they hang out online (or in-person) and understand how they prefer to work. GLAMs sometimes fall into the trap of choosing the technology first, or trying something because it's trendy; it's better to start with the intersection between your content and the preferences of potential audiences.
But is it wishful thinking to hope that others will be interested in answering the questions GLAMs are asking?
A tension?
Should projects accept that some people will move on as they develop new interests, and concentrate on recruiting new participants to replace them? Do they try to find more interesting tasks or new responsibilities for participants, such as helping moderate discussions, or checking and validating other people's work? Or should they find ways for the project grow as participants' skill and knowledge increase? It's important to make these decisions mindfully as the default is otherwise to accept a level of turnover as participants move on.
To return to lessons from citizen science, possible areas for deeper involvement include choosing or defining questions for study, analysing or interpreting data and drawing conclusions, discussing results and asking new questions.[3]However, heritage organisations might have to accept that the questions people want to ask might not involve their collections, and that these citizen historians' new interests might not leave time for their previous crowdsourcing tasks.
Why is a critical mass of content in a Participatory Commons useful?
And now we return to the Participatory Commons and the question of why a critical mass of content would be useful.

Increasingly, the old divisions between museum, library and archive collections don't make sense. For most people, content is content, and they don't understand why a pamphlet about a village fete in 1898 would be described and accessed differently depending on whether it had ended up in a museum, library or archive catalogue.
Basing niche projects on a wider range of content creates opportunities for different types of tasks and levels of responsibility. Projects that provide a variety of tasks and roles can support a range of different levels and types of participant skills, availability, knowledge and experience.
A critical mass of material is also important for the discoverability of heritage content. Even the most sophisticated researcher turns to Google sometimes, and if your content doesn't come up in the first few results, many researchers will never know it exists. It's easy to say but less easy to make a reality: the easier it is to find your collections, the more likely it is that researchers will use them.
Commons as party?
More importantly, a critical mass of content in a Commons allows us to re-define 'winning'. If participation is narrowly defined as belonging to individual GLAMs, when a citizen historian moves onto a project that doesn't involve your collection then it can seem like you've lost a collaborator. But the people who developed a new research interest through a project at one museum might find they end up using records from the archive down the road, and transcribing or enhancing their records during their investigation. If all the institutions in the region shared their records on the Commons or let researchers take and share photos while using their collections, the researcher has a critical mass of content for their research and hopefully as a side-effect, their activities will improve links between collections. If the Commons allows GLAMs to take a sector-wide view then someone moving on to a different collection becomes a moment to celebrate, a form of graduation. In our wildest imagination, the Commons could be like a fabulous party where you never know what fabulous interesting people and things you'll discover…
To conclude – by designing platforms that allow people to collect and improve records as they work, we're helping everybody win.
Thank you! I'm looking forward to hearing your thoughts.

Image credits in order of appearance: Glider, Library of Congress, Great hall, Library of Congress, Curzona Allport from Tasmanian Archive and Heritage Office, Hålanda Church, Västergötland, Sweden, Swedish National Heritage Board, Smithsonian Institution, Postmaster, General James A. Farley During National Air Mail Week, 1938, Powerhouse Museum, Canterbury Bankstown Rugby League Football Club's third annual Ball.