A quick report from hack4europe London, one of four hackathons organised by Europeana to 'showcase the potential of the API usage for data providers, partners and end-users'.
I have to confess that when I arrived I wasn't feeling terribly inspired – it's been a long month and I wasn't sure what I could get done at a one-day hack. I was intrigued by the idea of 'stealth culture' – putting cultural content out there for people to find, whether or not they were intentionally looking for 'a cultural experience' – but I couldn't think of a hack about it I could finish in about six hours. But I happened to walk past Owen Stephen's (@ostephens) screen and noticed that he was googling something about WordPress, and since I've done quite a lot of work in WordPress, I asked what his plans were. After a chat we decided to work together on a WordPress plugin to help people blog about cool things they found on museum visits. I'd met Owen at OpenCulture 2011 the day before (though we'd already been following each other on twitter) but without the hackday it's unlikely we would have ever worked together.
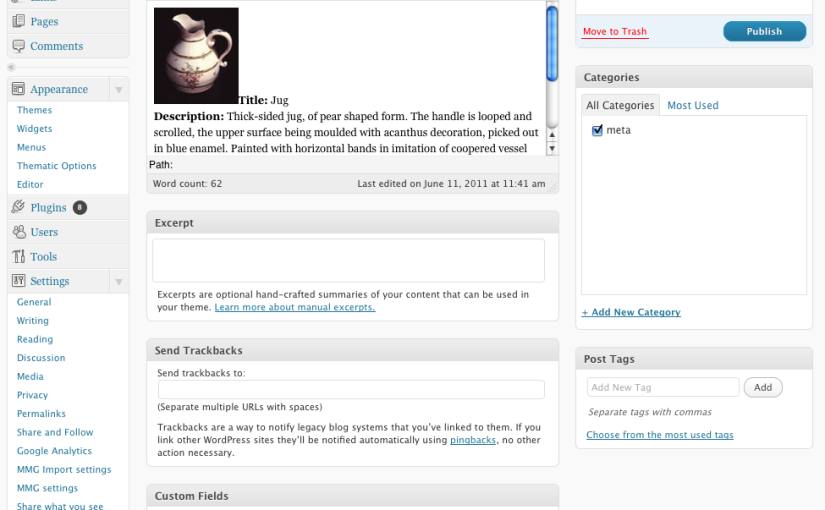
So what did we make? 'Share What You See' is a plugin designed to make a museum and gallery visit more personal, memorable and sociable. There's always that one object that made you laugh, reminded you of friends or family, or was just really striking. The plugin lets you search for the object in the Europeana collection (by title, and hopefully by venue or accession number), and instantly create a blog post about it (screenshot below) to share it with others.
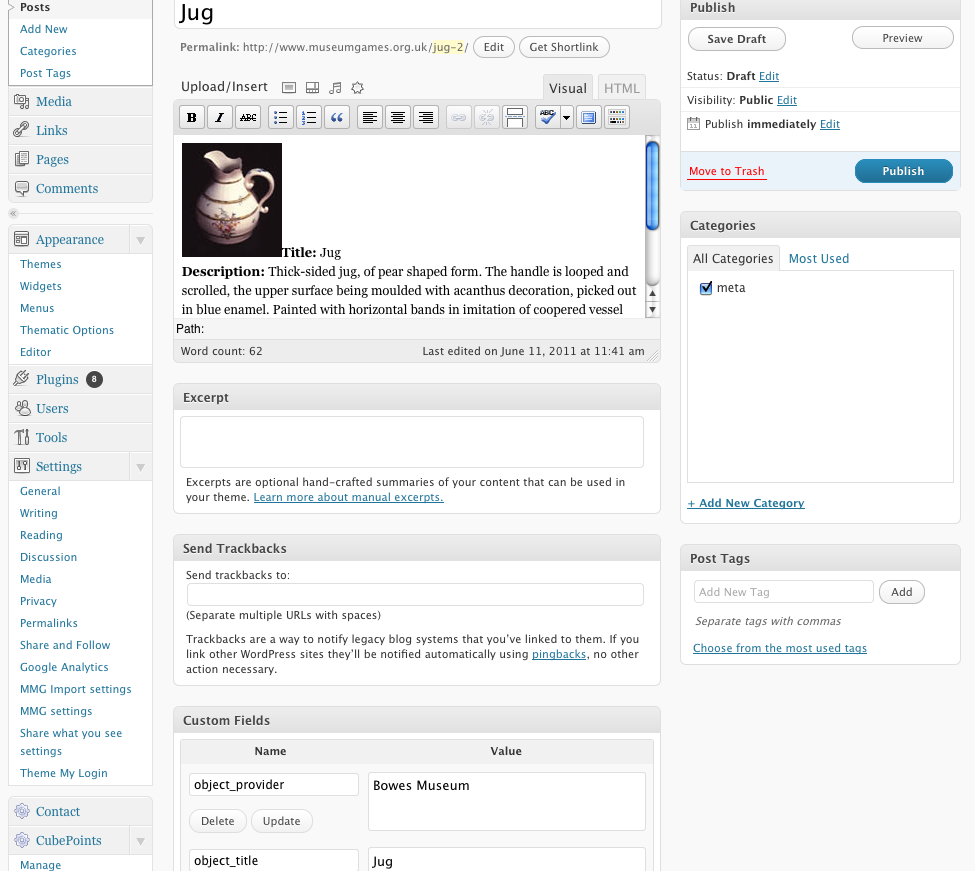 |
| Screenshot: post pre-populated with information about the object. |
Once you've found your object, the plugin automatically inserts an image of it, plus the title, description and venue name.
You can then add your own text and whatever other media you like. The plugin stores the originally retrieved information in custom fields so it's always there for reference if it's updated in the post. Once an image or other media item is added, you can use all the usual WordPress tools to edit it.
If you're in a gallery with wifi, you could create a post and share an object then and there, because WordPress is optimised for mobile devices. This help makes collection objects into 'social objects', embedding them in the lives of museum and gallery visitors. The plugin could also be used by teachers or community groups to elicit personal memories or creative stories before or after museum visits.
The code is at https://github.com/mialondon/Share-what-you-see and there's a sample blog post at http://www.museumgames.org.uk/jug/. There's still lots of tweaks we could have made, particularly around dealing with some of the data inconsistencies, and I'd love a search by city (in case you can't quite remember the name of the museum), etc, but it's not bad for a couple of hours work and it was a lot of fun. Thanks to the British Library for hosting the day (and the drinks afterwards), the Collections Trust/Culture Grid for organising, and Europeana for setting it up, and of course to Owen for working with me. Oh, and we won the prize for "developer's choice" so thank you to all the other developers!