I've been thinking about principles for documenting where AI was used to create or enhance metadata records in library, museum and archive catalogues/collections management systems. Ideally, one could also document the tool and version used, which is always helpful context and might also be used to note e.g. where re-doing automatic text transcription (ATR) with newer tools might make a big difference.
Edit, 26 Feb 2026: It's also important in situations where an organisation might feel the need to deploy 'good enough' tools to meet legislative accessibility requirements, or feel that any description, even if potentially inaccurate, is better than no description. In that case, they'd probably want to record which fields in which records have 'good enough for the time' information so it could be improved in future.
It's become timely in conversations with the oral history team and digital curator for ATR at the BL. I'd posted about it in various places, including the jiscmail 'AI in CH' list (AI in cultural heritage, not to be confused with AI4LAM!). It's hard to link to threads on jiscmail so as most of the posts are mine, and the other is a helpful post from the always-helpful Stephen McConnachie, I've copied them here to make them shareable:
I have a question from our Digital Curator for Automatic Text Recognition that we're hoping others working with digitised texts have some thoughts on. Do you know of any standards or processes for providing information about the use of AI/ML tools to create transcriptions for metadata for collections management or public interfaces? Or, given the wider focus of this group, the use of any other AI/ML tools to create or enhance metadata records?
I know that some libraries (like the BnF's Gallica) share OCR error rates in public interfaces, and others include information about the software/software version/date of processing in ALTO files, but is everyone doing this in a slightly bespoke way, or are any shared conventions or standards emerging?
I’ve had related conversations with the British Library's Metadata Standards team about recording the use of AI/ML to enhance metadata in MARC fields for printed heritage items, but many of the items we're looking at might be newspapers and periodicals catalogued differently, as well as sound/AV and manuscript/archive files.
I'm not aware of any emerging or established standards for documenting and contextualising text extraction via OCR or similar – would certainly be keen to find out though, so thanks very much for raising it.
'A disclaimer is added to every keyword extracted in this way, indicating that AI was used in the matching process: the disclaimer identifies the origin of the keyword, the field and character position it was extracted from, its confidence score, and the date and time of extraction.'
The sample text says: 'This was added using Al-based entity linking. Entity text between character 66 and 71 in the 'description' field, occurrence 1. Entity label: PERSON. Confidence score: 97.85%. Date/time of extraction job creation:2025-02-12T08:46:25. Entity UUID: a63853c8-dca4-4dc9-9ec0-07eb36eb8843.'
Adding to this thread in case people are interested…
Owen King got in touch via the AI4LAM Slack (join link) to share an update from the AI4LAM Speech-to-Text WG: 'we have been trying to find a standard way to record metadata about the provenance, especially the AI tooling used, of our audio transcripts. It seems to me that almost all of it applies to ATR and HTR transcripts as well. This is our current draft. Is this of any help?'
And while I'm here, is anyone working on the ethics of oral history recordings online and AI transcription? I had an interesting conversation with a European university librarian who reported that their oral history recordings were behind a login, but that browsers were now offering to transcribe the recordings, raising new questions about data scraping etc.
I've turned a version of the talks I've been doing on 'AI in libraries' for the past few years into an article for a library magazine. This is very much a pre-print, but it'll serve to capture a moment in time.Apparently it's an 11 minute read.
Artificial Intelligence has become one of the most discussed technologies of our time, but what does it actually mean for libraries and other cultural heritage institutions? In a decade working in digital scholarship at the British Library, I've witnessed firsthand the potential for AI to transform access to our collections – while also learning about its very real limitations.
Understanding AI: Beyond the Hype
Before exploring what AI can and can’t do for libraries, it's worth defining what we mean by AI. The term encompasses several related technologies that have evolved over time. Several years ago we talked about digital research with big data, then we were excited about machine learning and data science methods for developing software that was able to complete more complex tasks. We experimented with assistive or discriminative machine learning tools that could transcribe handwritten text, predict tags for images, detect entities like people, places and dates in text, or correct your spelling. These tools were useful, but relatively narrow in scope.
Now we have generative AI tools that can produce plausible new texts, images, and videos. However, it's crucial to understand their limitations: they can't count or do mathematics reliably, they don't truly understand words or concepts, they can't grasp real-world physics, and they can't determine truth.
I often use an image I generated with an AI tool using the prompt ‘rare books and special collections’ to illustrate this point. The result looks impressive – it has all the visual elements we associate with ancient books, including leather binding and aged paper. But when you examine it closely, it's a physically impossible ‘book’. The pages can't be opened; the text can't be read. It captures the superficial appearance of a rare book without any of the characteristics of a physical book. This perfectly demonstrates both AI's impressive capabilities and its fundamental limitations.
Figure 1 An image generated by AI with the prompt ‘rare books and special collections’.
Or to put it more flippantly, we call it 'machine learning' when it works, and 'AI' when it doesn't.
Practical Applications in Library Collections
Despite these limitations, AI and machine learning offer significant benefits for libraries. One of the most powerful applications for libraries is automatic text transcription from images and audio. A whole world of possibilities opens up once you have digital text.
Librarian and developer Matt Miller demonstrated what is possible with an early version of GPT: he took digitised images of a handwritten historical diary, and used AI to automatically transcribe the text, generate summaries of each entry, extract dates and locations, and identify people and places mentioned within. This transforms previously inaccessible handwritten documents into searchable, structured data which can be used in research or to find related items. Entity detection and linking – identifying people, places, dates, and concepts within text – allows us to create rich connections across our collections.
Object detection in images is another breakthrough. AI can identify items in photographs and generate keywords, labels, and descriptions. This technology is probably already working on your smartphone – you can search your photos for concepts like ‘dog’ or ‘dinner’, or select, copy and paste text from a photo. For libraries, this means our visual collections become much more discoverable.
Perhaps most importantly for library users, AI can cluster similar images and words, enabling conceptual rather than keyword-based searching. Instead of users needing to know how library catalogues work, they can search for ‘vibes’ or concepts, making library collections far more accessible to diverse audiences.
We can also translate text and speech into other languages – if you attended my talk at Knihovny současnosti 2025, then you probably saw the live transcription and translation of my Australian-accented English into Czech subtitles. AI can also rewrite content for different audiences, perhaps explaining complex research for tourists or children.
As an example – the process of writing this article was augmented by AI/machine learning tools. I recorded my rehearsal and live delivery of my conference presentation, then copied the text transcriptions my phone generated from those recordings into an AI tool (Claude AI). I asked the tool to turn my spoken words into an article, then edited the result into the article you’re reading now. It’s all my own thoughts, but with a level of polish that it would have taken me a lot longer to produce.
Building Institutional Capacity
The British Library's experiments with machine learning and AI didn’t happen overnight. We've invested in training and digital literacy around AI and machine learning for over a decade as part of our broader digital scholarship programme. This long-term commitment has made an enormous difference in our staff's ability to undertake experiments and be effective collaborators.
When researchers or external partners approach us with digital research projects, our staff have a sense of what might be involved, ideas for improvement, and suggestions for avoiding common pitfalls. In addition to the extensive skills required for their own jobs, this knowledge comes from hands-on experience with specific tools to understand both their capabilities and limitations, and most importantly, learning about the substantial work required to prepare data for these systems.
As we used to say in data visualisation and data science, 80% of the work is cleaning and preparing data, while only 20% is the exciting analytical or work. This remains true for AI applications in libraries.
Real-World Experiments and Collaborations
Our institutional capacity has enabled numerous experiments. For example, computational linguists analysed web archives to track how language evolves over time. For example, the term ‘blackberry’ shifted from being associated with fruit to smartphones and keyboards during BlackBerry's market dominance, then reverted as the company declined. Similarly, ‘cloud’ transformed from a meteorological term to a computing concept.
Elsewhere, Library staff developed machine learning models to detect mislabelled images in our digitised manuscript collections and created systems to identify when digitised images are upside down so they can be automatically corrected. One particularly successful project used machine learning to identify languages on title pages of digitised books. Combined with crowdsourcing verification through the Zooniverse platform, this work added 141 previously unidentified languages to our catalogue.
Our work with automatic text recognition (ATR) spans printed materials using optical character recognition (OCR), handwritten materials using handwritten text recognition (HTR), and hopefully in the future, speech-to-text for audio collections. Colleague Adi Keinan-Schoonbaert has focused particularly on extending these capabilities to non-English and non-Roman scripts – Arabic, Japanese, and other languages that aren't as well-resourced as English in current AI systems. Our work has shown how important it is to understand work you seek to automate – we talk to staff across the Library to understand their processes.
Case Study: Living with Machines
The Living with Machines project represents our most ambitious exploration to date of AI's potential for historical research. As principal investigator Ruth Ahnert described it, this was simultaneously ‘a data-driven history project and a historically informed data science project’.
We chose the name ‘living with machines’ deliberately. In 2017-2018, we realised we were on the cusp of a machine learning-led transformation that would eventually fundamentally change society. The project's meta-nature involved using 19th-century texts, newspapers and maps to understand how mechanisation transformed that era, thereby helping us understand our own relationship with emerging technologies.
British Library staff initiated the project in part to understand how machine learning was going to transform what library professionals and researchers could do with collections. We wanted to understand what AI could do well, and where it was likely to fail. The project also allowed us to explore some of the complex copyright issues around computational access (including the vital role of the text and data mining exception) and the biases potentially introduced through the selection of items for digitisation.
This massive undertaking involved over 40 people across its lifetime, typically 20-25 simultaneously. The scale reflected both the enormous collections we were analysing – millions of digitised newspaper pages and books – and our ambition to understand what happens when you bring together humanities scholars, library professionals, software engineers and data scientists to solve complex problems.
The project produced remarkable bespoke tools that responded to the challenges of working with digitised sources at scale. Place names can be slippery – it’s important to distinguish between different locations with the same name worldwide and understand when ‘Brussels’ refers to EU governance versus the physical city, so the toponym resolution system, T-Res, could identify and disambiguate place names in text. Other team members developed methods for tracking individuals across census decades, allowing them to understand how occupations changed over time.
Linguistic analysis revealed how machines were given human-like agency in historical texts. We combined crowdsourcing and vector databases to examine how mechanisation changed the meanings of words like ‘trolley’ and ‘cart’ as railways and automobiles transformed transportation.
Additional work included developing tools for searching through poor-quality optical character recognition, understanding potential biases in our digitised newspaper corpus, and pioneering computer vision approaches for reading historical maps and extracting semantic information from cartographic symbols. Impressively, the tool designed to search across Ordnance Survey maps has been adopted by scientists outside the project.
The Current Landscape: From Custom to Commodity
The AI landscape has evolved dramatically since we began Living with Machines. Wardley Mapping proposes that technologies pass through successive ‘evolution’ stages. The Living with Machines project operated during the ‘custom-built’ stage, when AI and data science tools were experimental and unique, requiring specialist expertise to build. This also allowed the project to co-create bespoke tools with humanities scholars.
Today it is much more likely that libraries can find existing products that meet their needs for common tasks like text and speech recognition, detecting objects in images, keyword search expansion, and even suggesting subject headings. Tools like ChatGPT and other large language models have made tasks possible now that were impossible in the early years of Living with Machines. Library professionals can experiment with AI tools on their desktop to prototype bespoke workflows and tasks.
Challenges and Limitations
However, we don't yet have the AI that libraries truly need and deserve. Current machine learning models embed prejudices – particularly racism, sexism, and structural inequalities expressed in historical training data. They don't represent all cultures or historical periods equally, and they often reflect commercial rather than cultural heritage values.
Ethical questions surround how training data was obtained, with numerous ongoing legal cases addressing these concerns. Environmental costs can be substantial, and companies aren't always transparent about water usage and carbon footprints.
Most critically for libraries – institutions that prize accuracy and precision – we know AI-generated content contains errors, but we can't predict where they'll occur. Even with error rates as low as 5-10%, we must carefully consider where mistakes are acceptable. Less precise keywords might be fine for discoverability, but errors in authoritative catalogue records are more problematic.
Since we often need to manually check everything or conduct sample validation anyway, it's sometimes unclear how much time these tools really save.
Looking Forward: Community and Continuous Learning
Despite these challenges, AI technologies continue advancing rapidly. What seems impossible today may be routine in a year's time.
Of course, this can make it hard to keep up with changes in the field. I encourage everyone to engage with communities like AI4LAM (Libraries, Archives, and Museums), which hosts regular online calls about different topics and maintains extensive archives of previous sessions on YouTube. They also provide Slack channels and a mailing list for ongoing conversation. These resources offer invaluable insights into how different organisations tackle specific challenges and enhance their collections.
AI and machine learning offer genuine opportunities to transform how we work with library collections, making them more accessible, discoverable, and useful for researchers and the public. However, success requires understanding both the potential and limitations of these technologies.
The key lies in building institutional capacity through training and experimentation, working collaboratively with technical experts, and maintaining critical awareness of biases and limitations. Most importantly, we must remember that AI works best when it augments human expertise rather than replacing it.
As we continue living with these machines, the goal isn't to automate everything, but to amplify our capabilities while preserving the values and standards that make libraries essential cultural institutions. The future of AI in libraries will be written by practitioners who understand both the technology and the unique mission of libraries in preserving and sharing human knowledge.
I've shared these at work and thought it might be helpful to post my notes from the launch of the Museum Data Service at Bloomberg last week in public too.
The MDS aggregates museum (and museum-like) metadata, encouraging use by data scientists, researchers, the public, etc. The MDS doesn't include images, but links to them if they're available on museum websites. (When they open APIs, presumably people could build their own image-focused site on the service).
It was launched by Sir Chris Bryant (Minister of State at the Department for Science, Innovation and Technology and the Department for Culture, Media and Sport) who said it could be renamed the ‘Autolycus project', after Shakespeare's snapper up of unconsidered trifles. He presented it as a rare project that sits between his two portfolios.
Allan Sudlow of the AHRC (one of the funders) described it as secure, reliable digital infrastructure for GLAMs, especially providing security and sustainability for smaller museums, and meeting a range of needs, including reciprocal relationships between museums and researchers. He positioned it as part of the greater ecosystem, infrastructure for digital creativity and innovation. Kevin Gosling (Collections Trust) mentioned that it helps deliver the Mendoza Report's ‘dynamic collections'.
I'd seen a preview over the summer and was already impressed with the way it builds on decades of experience managing and aggregating real museum data between internal and centralised systems. They've thought hard about what museums really need to represent their collections, what they find hard about managing data/tech, and what the MDS can do to lighten that load.
The MDS can operate as a backup of last resort, including data that isn't shared even inside the organisation. They're not trying to pre-shape the data in any way, to allow for as many uses as possible (apart from the process of mapping specific museum data to their fields). It has persistent links (fundamental to FAIR data and citing records). They're linking to wikidata (and creating records there where necessary). APIs will be available soon (which might finally mean an end to the ‘does every museum need an API' debate).
The site https://museumdata.uk/ has records for institutions, collections, object records, and ‘new and enhanced data' about object records (e.g. exhibition interpretation, AI-generated keywords). It feels a bit like a rope bridge – lightweight but strong and flexible infrastructure that meets a community need.
I admire the way they've used just enough technology to deliver it both practically and elegantly. They've also worked hard on explaining why it matters to different stakeholders, and finding models for funding and sustainability.
On a personal note, the launch was a bit like a school reunion (if you went to a particularly nerdy school). It was great to see people like David Dawson, Richard Light and Gordon McKenna there (plus Andy Ellis, Ross Parry and Kevin Gosling) as they'd shared visions for a service like this many years ago, and finally got to see it go live.
Back in November 2015, Tara Andrews invited me to give a guest lecture on 'digital history' for the Introduction to Digital Humanities course at the University of Bern, where she was then a professor. This is a slightly shortened version of my talk notes, finally posted in 2024 as I go back to thinking about what 'digital history' actually is.
I called my talk '57 varieties of digital history' as a play on the number of activities and outputs called 'digital history'. While digital history and digital humanities are often linked and have many methods in common, digital history also draws on the use of computers for quantitative work, and digitisation projects undertaken in museums, libraries, archives and academia. Digital tools have enhanced many of the tasks in the research process (which itself has many stages – I find the University of Minnesota Libraries' model with stages of 'discovering', 'gathering', 'creating' and 'sharing' useful), but at the moment the underlying processes often remain the same.
So, what is digital history?
…using computers for writing, publishing
A historian on twitter once told me about a colleague who said they're doing digital history because they're using PowerPoint. On reflection, I think they have a point. These simple tools might be linked to fairly traditional scholarship – writing journal articles or creating presentations – but text created in them is infinitely quotable, shareable, and searchable, unlike the more inert paper equivalents. Many scholars use Word documents to keep bits of text they've transcribed from historical source materials, or to keep track of information from other articles or books. These become part of their personal research collections, which can build up over years into substantial resources in their own right. Even 'helper' applications like reference managers such as Zotero or EndNote can free up significant amounts of time that can then be devoted to research.
…the study of computers
When some people hear 'digital history', they imagine that it's the study of computers, rather than the use of digital methods by historians. While this isn't a serious definition of digital history, it's a reminder that viewing digital tools through a history of science and technology lens can be fruitful.
…using digitised material
Digitisation takes many forms, including creating or transcribing catalogue records about heritage collections, writing full descriptions of items, and making digital images of books, manuscripts, artworks etc. Metadata – information about the item, such as when and where it was made – is the minimum required to make collections discoverable. Increasingly, new forms of photography may be applied to particular types of objects to capture more information than the naked eye can see. Text may be transcribed, place names mapped, marginalia annotated and more.
The availability of free (or comparatively inexpensive) historical records through heritage institutions and related commercial or grassroots projects means we can access historical material without having to work around physical locations and opening hours, negotiate entry to archives (some of which require users to be 'bona fide scholars'), or navigate unknown etiquettes. Text transcription allows readers who lack the skills to read manuscript or hand-written documents to make use of these resources, as well as making the text searchable.
For some historians, this is about as digital as they want to get. They're very happy with being able to access more material more conveniently; their research methods and questions are still pretty unchanged.
…creating digital repositories
Most digitised items live in some broader system that aggregates and presents material from a particular institution, or related to a particular topic. While some digital repositories are based on sub-sets of official institutional collections, most aren't traditional 'archives'. One archivist describes digital repositories as a 'purposeful collection of surrogates'.
Repositories aren't always created by big, funded projects. Personal research collections assembled over time are one form of ad hoc repository – they may contain material from many different archives collected by one researcher over a number of years.
Themed collections may be the result of large, scholarly projects with formal partners who've agreed to contribute material about a particular time, place, group in society or topic. They might also be the result of work by a local history society with volunteers who digitise material and share it online.
'Commons' projects (like Flickr or Wikimedia Commons) tend to be less focused – they might contain collections from specific institutions, but these specific collections are aggregated into the whole repository, where their identity (and the provenance of individual items) may be subsumed. While 'commons' platforms technically enable sharing, the cultural practices around sharing are yet to change, particularly for academic historians and many cultural institutions.
Repositories can provide different functionality. In some 'scholarly workbenches' you can collect and annotate material; in others you can bookmark records or download images. They allow support different levels of access. Some allow you to download and re-use material without restriction, some only allow non-commercial use, and some are behind paywalls.
…creating datasets
The Old Bailey Online project has digitised the proceedings of the Old Bailey, making court cases from 1674 to 1913 available online. They haven't just transcribed text from digital images, they've added structure to the text. For example, the defendant's name, the crime he was accused of and the victim's name have all been tagged. The addition of this structure means that the material can be studied as text, or analysed statistically.
Adding structure to data can enable innovative research activities. If the markup is well-designed, it can support the exploration of questions that were not envisaged when the data was created. Adding structure to other datasets may become less resource-intensive as new computational techniques become available.
…creating visualisations and innovative interfaces
Some people or projects create specialist interfaces to help people explore their datasets. They might be maps or timelines that help people understand the scope of a collection in time and place, while others are more interpretive, presenting a scholarly argument through their arrangement of interface elements, the material they have assembled, the labels they use and the search or browse queries they support. Ideally, these interfaces should provide access to the original records underlying the visualisation so that scholars can investigate potential new research questions that arise from their use of the interface.
…creating linked data (going from strings to things)
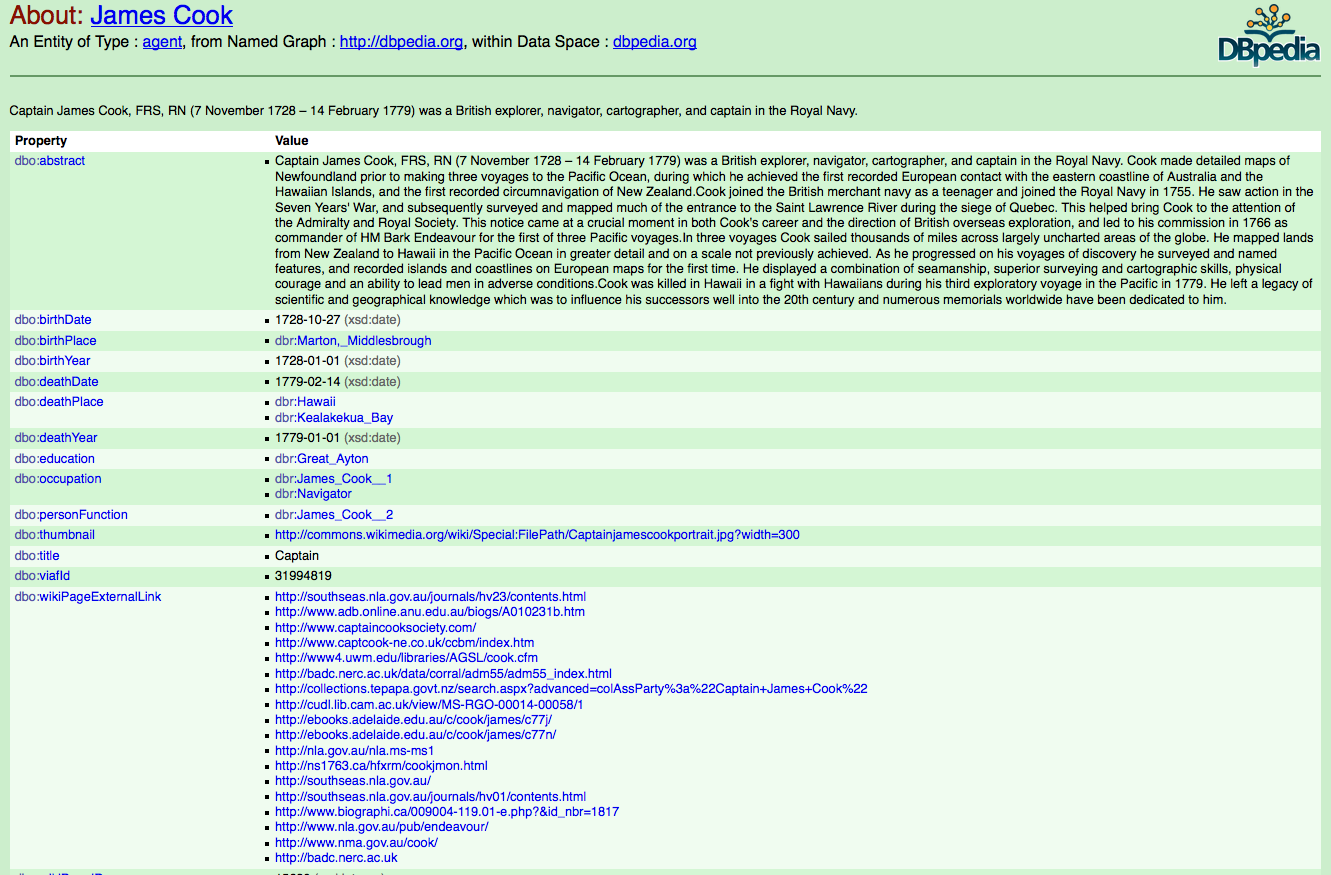
As well as marking up records with information like 'this bit is a defendant's name', we can also link a particular person's name to other records about them online. One way to do this is to link their name to published lists of names online. These stable identifiers mean that we could link any mention of a particular person in a text to this online identifier, so that 'Captain Cook' or 'James Cook' are understood to be different strings about the same person.
dbpedia page for 'James Cook', 2015
This also helps create a layer of semantic meaning about these strings of text. Software can learn that strings that represent people can have relationships with other things – in this case, historical voyages, other people, natural history and ethnographic collections, and historical events.
…applying computational methods, tools to digitised sources
So far some of what we've seen has been heavily reliant on manual processing – someone has had to sit at a desk and decide which bit of text is about the defendant and which about the victim in an Old Bailey case.
So people are developing software algorithms to find concepts – people, places, events, etc – within text. This is partly a response to amount of digitised text now available; partly a response to recognition of power of structured data. Techniques like 'named entity recognition' help create structure from unstructured data. This allows data to be queried, contextualised and presented in more powerful ways.
The named entity recognition software here [screenshot lost?] knows some things about the world – the names of places, people, dates, some organisations. It also gets lots of things wrong – it doesn't understand 'category five storm' as a concept, it mixes up people and organisations – but as a first pass, it has potential. Software can be trained to understand the kinds of concepts and things that occur in particular datasets. This also presents a problem for historians, who may have to use software trained for modern, commercial data.
This is part of a wider exploration of 'distant reading', methods for understanding what's in a corpus by processing the text en masse rather than by reading each individual novel or document. For example, it might be used to find linguistic differences between genres of literature, or between authors from different countries.
In this example [screenshot of topic modelling lost?], statistically unlikely combinations of words have been grouped together into 'topics'. This provides a form of summary of the contents of text files.
Image tagging – 'machine learning' techniques mean that software can learn how to do things rather than having to be precisely programmed in advance. This will have more impact on the future of digital history as these techniques become mainstream.
Audio tagging – software suggests tags, humans verify them. Quicker than doing them from scratch, but possible for software to miss significant moments that a person would spot. (e.g. famous voices, cultural references, etc).
Handwritten text recognition will transform manuscript sources such as much as optical character recognition has transformed typed sources!
Studying born digital material (web archives, social media corpus etc)
Important historical moments, such as the 'Arab spring', happened on social media platforms like twitter, youtube and facebook. The British Library and the Internet Archive have various 'snapshots' of websites, but they can only hope to capture a part of online material. We've already lost significant chunks of web history – every time a social media platform is shut without being archived, future historians have lost valuable data. (Not to mention people's personal data losses).
This also raises questions about how we should study 'digital material culture'. Websites like Facebook really only make sense when they're used in a social context. The interaction design of 'likes' and comments, the way a newsfeed is constructed in seconds based on a tiny part of everything done in your network – these are hard to study as a series of static screenshots or data dumps.
…sharing history online
Sharing research outputs is great. It some point it starts to intersect with public history. But questions remain about 'broadcast' vs 'discursive' modes of public history – could we do more than model old formats online? Websites and social media can be just as one-way broadcast as television unless they're designed for two-way participation.
What's missing?
Are there other research objects or questions that should be included under the heading 'digital history'? [A question to allow for discussion time]
Towards the future of looking at the past
To sum up what we've seen so far – we've seen the transformation of unorganised, unprocessed data into 'information' through research activities like 'classification, rearranging/sorting, aggregating, performing calculations, and selection'.
Historical material is being transformed from a 'page' to a 'dataset'. As some of this process is automated, it raises new questions – how do we balance the convenience of automatic processing with the responsibility to review and verify the results? How do we convey the processes that went into creating a dataset so that another researcher can understand its gaps, the mixture of algorithmic and expert processes applied to it? My work at the British Library has made the importance of versioning a dataset or corpus clear – if a historian bases an argument on one version of OCR text, and the next version is better, they should be able to link to the version they based their work on.
We've thought about how digital text and media allows for new forms of analysis, using methods such as data visualisation, topic modelling or data mining. These methods can yield new insights and provoke new research questions, but most are not yet accessible to the ordinary historian. While automated processes help, preparing data for digital history is still incredibly detailed, time-consuming work.
What are the pros and cons of the forms of digital history discussed?
Cons
The ability to locate records on consumer-facing services like Google Maps is valuable, but commercial, general use mapping tools are not always suitable for historical data, which is often fuzzy, messy, and of highly variable coverage and precision. For example, placing text or points on maps can suggest a degree of certainty not supported by the data. Locating historical addresses can be inherently uncertain in instances where street numbers were not yet in use, but most systems expect a location to be placed as a precise dot (point of interest) on a map; drawing a line to mark a location would at least allow the length of a street to be marked as a possible address.
There is an unmet need for everyday geospatial tools suitable for historians. For example, those with datasets containing historical locations would appreciate the ability to map addresses from specific periods on historical maps that are georeferenced, georectified and displayable on a modern, copyright-free map or the historical map. Similarly, biographical software, particularly when used for family history, collaborative prosopographical or community history projects would benefit from the ability to record the degree of certainty for potential-but-not-yet-proven relationships or identifications, and to link uncertain information to specific individuals.
The complexity of some software packages (or the combination of packages assembled to meet various needs) is a barrier for those short on time, unable to access dedicated support or training, or who do not feel capable of learning the specialist jargon and skills required to assess and procure software to meet their needs. The need for equipment and software licences can be a financial barrier; unclear licensing requirements and costs for purchasing high-resolution historical maps are another. Copyright and licensing are also complex issues.
Sensible historians worry about the sustainability of digital sites – their personal research collection might be around for 30 years or more; and they want to cite material that will be findable later.
There are issues with representing historical data, particularly in modern tools that cannot represent uncertainty, contingency. Here [screenshot lost?]the curator's necessarily fuzzy label of 'early 17th century' has been assigned to a falsely precise date. Many digital tools are not (yet) suitable for historical data. Their abilities have over-stated or their limits not clearly communicated/understood.
Very few peer-reviewed journals are able to host formats other than articles, inhibiting historians' ability to explore emerging digital formats for presenting research.
Faculty historians might dream of creating digital projects tailored for the specific requirements of their historical dataset, research question and audience, but their peers may not be confident in their ability to evaluate the results and assign credit appropriately.
Pros
Material can be recontextualised, transcluded, linked, contextualised. The distance between a reference and the original item reduced to just a link (unless a paywall etc gets in the way). Material can be organised in multiple ways independent of their physical location. Digital tools can represent multiple commentaries or assertions on a single image or document through linked annotations.
Computational techniques for processing data could reduce the gap between well-funded projects and others, thereby reducing the likelihood of digital history projects reinscribing the canon.
Digitised resources have made it easier to write histories of ordinary lives. You can search through multiple databases to quickly collate biographical info (births, deaths, marriages etc) and other instances when their existence might be documented. This isn't just a change in speed, but also in the accessibility of resources without travel, expense.
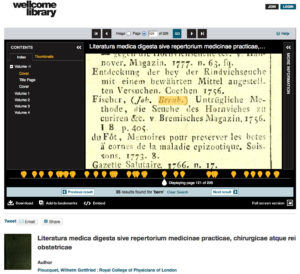
Wellcome's IIIF viewer showing a highlighted search result
Search – any word in a digitised text can be a search result – we're not limited to keywords in a catalogue record. We can also discover some historical material via general search engines. Phonetic and fuzzy searches have also improved the ability to discover sources.
Historians like Professor Katrina Navickas have shown new models for the division of labour between people and software; previously most historical data collection and processing was painstakingly done by historians. She and others have shown how digital techniques can be applied to digitised sources in the pursuit of a historical research question.
Conclusion and questions: digital history, digital historiography?
The future is here, it's just not evenly distributed (this is the downer bit)
Academic historians might find it difficult to explore new forms of digital creation if they are hindered by the difficulties of collaborating on interdisciplinary digital projects and their need for credit and attribution when publishing data or research. More advanced forms of digital history also require access to technical expertise. While historians should know the basics of computational thinking, most may not be able to train as a programmer and as a historian – how much should we expect people to know about making software?
I've hinted at the impact of convenience in accessing digitised historical materials, and in those various stages of 'discovering', 'gathering', 'creating' and 'sharing'… We must also consider how experiences of digital technologies have influenced our understanding of what is possible in historical research, and the factors that limit the impact of digital technologies. The ease with which historians transform data from text notes to spreadsheets to maps to publications and presentations is almost taken for granted, but it shows the impact of digitality on enhancing everyday research practices.
So digital history has potential, is being demonstrated, but there's more to do…
My favourite analogy for AI / machine learning-based tools[1] is that they’re like working with a child. They can spin a great story, but you wouldn’t bet your job on it being accurate. They can do tasks like sorting and labelling images, but as they absorb models of the world from the adults around them you’d want to check that they haven’t mistakenly learnt things like ‘nurses are women and doctors are men’.
Libraries and other GLAMs have been working with machine learning-based tools for a number of years, cumulatively gathering evidence for what works, what doesn’t, and what it might mean for our work. AI can scale up tasks like transcription, translation, classification, entity recognition and summarisation quickly – but it shouldn’t be used without supervision if the answer to the question ‘does it matter if the output is true?’ is ‘yes’.[2] Training a model and checking the results of an external model both require resources and expertise that may be scarce in GLAMs.
But the thing about toddlers is that they’re cute and fun to play with. By the start of 2023, ‘generative AI’ tools like the text-to-image tool DALL·E 2 and large language models (LLMs) like ChatGPT captured the public imagination. You’ve probably heard examples of people using LLMs as everything from an oracle (‘give me arguments for and against remodelling our kitchen’) to a tutor (‘explain this concept to me’) to a creative spark for getting started with writing code or a piece of text. If you don’t have an AI strategy already, you’re going to need one soon.
The other thing about toddlers is that they grow up fast. GLAMs have an opportunity to help influence the types of teenagers then adults they become – but we need to be proactive if we want AI that produces trustworthy results and doesn’t create further biases. Improving AI literacy within the GLAM sector is an important part of being able to make good choices about the technologies we give our money and attention to. (The same is also true for our societies as a whole, of course).
Since the 2017 summit, I’ve found myself thinking about ‘collections as data’ in two ways.[3] One is the digitised collections records (from metadata through to full page or object scans) that we share with researchers interested in studying particular topics, formats or methods; the other is the data that GLAMs themselves could generate about their collections to make them more discoverable and better connected to other collections. The development of specialist methods within computer vision and natural language processing has promise for both sorts of ‘collections as data’,[4] but we still have much to learn about the logistical, legal, cultural and training challenges in aligning the needs of researchers and GLAMs.
The buzz around AI and the hunger for more material to feed into models has introduced a third – collections as training data. Libraries hold vast repositories of historical and contemporary collections that reflect both the best thinking and the worst biases of the society that produced them. What is their role in responsibly and ethically stewarding those collections into training data (or not)?
As we learn more about the different ‘modes of interaction’ with AI-based tools, from the ‘text-grounded’, ‘knowledge-seeking’ and ‘creative’,[5] and collect examples of researchers and institutions using tools like large language models to create structured data from text,[6] we’re better able to understand and advocate for the role that AI might play in library work. Through collaborations within the Living with Machines project, I’ve seen how we could combine crowdsourcing and machine learning to clear copyright for orphan works at scale; improve metadata and full text searches with word vectors that help people match keywords to concepts rather than literal strings; disambiguate historical place names and turn symbols on maps into computational information.
Our challenge now is to work together with the Silicon Valley companies that shape so much of what AI ‘knows’ about the world, with the communities and individuals that created the collections we care for, and with the wider GLAM sector to ensure that we get the best AI tools possible.
[1] I’m going to use ‘AI’ as a shorthand for ‘AI and machine learning’ throughout, as machine learning models are the most practical applications of AI-type technologies at present. I’m excluding ‘artificial general intelligence’ for now.
[2] Tiulkanov, “Is It Safe to Use ChatGPT for Your Task?”
[3] Much of this thinking is informed by the Living with Machines project, a mere twinkle in the eye during the first summit. Launched in late 2018, the project aims to devise new methods, tools and software in data science and artificial intelligence that can be applied to historical resources. A key goal for the Library was to understand and develop some solutions for the practical, intellectual, logistical and copyright challenges in collaborative research with digitised collections at scale. As the project draws to an end five and a half years later, I’ve been reflecting on lessons learnt from our work with AI, and on the dramatic improvements in machine learning tools and methods since the project began.
It features highlights from their collections and 'stories behind our records'. The front page offers options to explore by topic (based on the types of records that TNA holds) and time period. It also has direct links to individual stories, with carefully selected images and preview text. Three clicks in and I was marvelling at a 1904 photo from a cotton mill, and connecting it to other knowledge.
When you click into a story about an individual record, there's a 'Why this record matters' heading, which reminds me of the Australian model for a simple explanation of the 'significance' of a collection item. Things get a bit more traditional 'catalogue record online' when you click through to the 'record details' but overall it's an effective path that helps you understand what's in their collections.
The simplicity of getting to an interesting items has made me wonder about a new UX metric for collections online – 'time to curiosity inspired', or more accurately 'clicks to curiosity triggered'. 'Clicks to specific item' is probably a more common metric for catalogue-based searches, but this is a different type of invitation to explore a collection via loosely themed stories.
The Museums Computer Group's annual conference has been an annual highlight for some years now, and in 2022 I donned my mask and went to their in-person event. And only a few months later I'm posting this lightly edited version of my Mastodon posts from the day of the event in November 2022… Notes in brackets are generally from the original toots/posts.
This was the first event that I live-blogged on Mastodon rather than live-tweeting. I definitely missed the to-and-fro of conversation around a hashtag, as in mid-November Mastodon was a lot quieter than it is even a few weeks later. Anyway, on with the post!
I'm at the Museums Computer Group's #MuseTech2022 conference.
Keynote Kati Price on the last two and a half years – a big group hug or primal scream might help!
She's looking at the consequences of the pandemic and lockdowns in terms of: collaboration, content, cash, churn
Widespread adoption of tools as people found new ways of collaborating from home
Content – the 'hosepipe of requests' for digital content is all too familiar. Lockdown reduced things to one unifying goal – to engage audiences online
(In hindsight, that moment of 'we must find / provide entertainment online' was odd – the world was already full of books, tv, podcasts, videos etc – did we want things we could do together that were a bit like things we'd do IRL?)
V&A moved to capture their Kimono exhibition to share online just before closing for lockdown. Got a Time Out 'Time In'. No fancy tech, just good storytelling
V&A found that people either wanted very short or long form content; some wanted informative, others light-hearted content
Cash – how do you keep creating great experiences when income drops? No visitors, no income.
Churn – 'the great resignation' – we've seen a brain drain in the #MuseTech / GLAM sector, especially as it's hard to attract people given salaries. Not only in tech – loss of expert collections, research staff who help inform online content
UK's heading into recession, so more cuts are probably coming. What should a digital team look like in this new era?
Also, we're all burnt out. (Holler!) Emotional reserves are at an all-time low.
(Thinking about the silos – I feel my work-social circles are dwindling as I don't run into people around the building now most people are WFH most of the time)
Back from the break at #MuseTech2022 for more #MuseTech goodness, starting with Seb Chan and Indigo Holcombe-James on ACMI's CEO Digital Mentoring Program – could you pair different kinds of organisations and increase the digital literacy of senior leaders?
Working with a mentor had tangible and intangible benefits (in addition to making time for learning and reflection). The next phase was shorter, with fewer people. (Context for non-Australians – Melbourne's lockdown was *very* long and very restrictive)
(I wonder what a 'minimum viable mentorship' model might be – does a long coffee with someone count? I've certainly had my brain picked that way by senior leaders interested in digital participation and strategy)
Lessons – cross-art form conversations work really well; everyone is facing similar challenges
(Side note – I'm liking that longer posts mean I'm not dashing off posts to keep up with the talks)
Next up #MuseTech2022 Stephanie Bertrand https://twitter.com/sbrtrandcurator on prestige and aesthetic judgement in the art world. Can you recruit the public's collective intelligence to discover artworks? But can you remove the influence of official 'art world' taste makers in judging artworks?
'Social feedback is a catch-22' – can have runaway inequality where popular content becomes more popular, and artificial manipulation that skews what's valued?
Now Somaya Langley https://twitter.com/criticalsenses on making digital preservation an everyday thing. (Shoutout to the awesome #DigiPres folk who do this hard work) – how can a whole organisation include digital preservation in its wider thinking about collections and corporate records? What about collecting born-digital content so prevalent in modern life?
(Side note – Australia seems to have a much stronger record management culture within GLAMs than in the UK, where IME you really have to search to find organisational expectations about archiving project records)
Moving from Projects to Programmes to Business as Usual is hard
Help people be comfortable with there not being one right answer, and ok with 'it depends'
#MuseTech2022 Next up in Session 2: Collections; Craig Middleton, Caroline Wilson-Barnao, Lisa Enright – documenting intense bushfires in Aus summer 2019/20 and COVID. They used Facebook as a short-term response to the crisis; planned a physical exhibition but a website came to seem more appropriate as COVID went on. https://momentous.nma.gov.au has over 300 unique responses. FB helpful for seeing if a collecting idea works while it's timely, but other platforms better for sustained engagement. Also need to think about comfort levels about sharing content changing as time goes on.
Museums can be places to have difficult conversations, to help people make sense of crises. But museums also need to think beyond physical spaces and include digital from the start.
Also hard when museum people are going through the same crises (links back to Kati's keynote about what we lived through as a sector working for our audiences while living through the pando ourselves)
#MuseTech2022 David Weinczok 'using digital media to go local'
60% of National Museums Scotland's online audiences have never visited their museums. 'Telling the story of an object without the context of the landscape and community it came from' can help link online and in-person audiences and experiences
Blog series 'Objects in Place' – found items in collections from a particular area, looked to tell stories with objects as 'connective threads', not the focus in themselves
'What can we do online to make connections with people and communities offline?'
(So many speakers are finishing with questions – I love this! Way to make the most of being in conversation with the musetech community here)
Next at #MuseTech2022, Amy Adams & Karen Clarke, National Museum of the Royal Navy – digital was always lower priority before COVID; managed to do lots of work on collections data during lockdowns.
They finally got a digital asset management (DAM) system, but then had to think about maintaining it; explaining why implementation takes time. Then there was an expectation that they could 'flip a switch' and put all the collections online. Finding ways to have positive conversations with folk who are still learning about the #MuseTech field.
Also doing work on 'addressing empires' – I like that framing for a very British institution.
Now Rebecca Odell, Niti Acharya, Hackney Museum on surviving a cyber attack. Lost access to collections management database (CMS) and images. Like their digital building had burnt down. Stakeholder and public expectations did not adjust accordingly! 14 months without a CMS.
Know where your backups are! Export DBs as CSV, store it externally. LOCKSS, hard drives
#MuseTech2022 Rebecca Odell, Niti Acharya, Hackney Museum continued – reconstructing your digital stuff from backups, exports, etc takes tiiiiiiime and lots of manual work. The sector needs guides, checklists, templates to help orgs prepare for cyber attacks.
(Lots of her advice also applies to your own personal digital media, of course. Back up your backups and put them lots of places. Leave a hard drive at work, swap one with a friend!)
New Q&A game – track the echo between remote speakers and the AV system in the back. Who's unmuted that should be muted? [One of the joys of a hybrid conference]
We'll be heading out to lunch soon, including the MCG annual general meeting
Adam Coulson (National Museums Scotland) on QR codes: * weren't scanned in all exhibition/gallery contexts * use them to add extra layers, not core content * don't assume everyone will scan * discourage FOMO (explain what's there) * consider precious battery life
Now Sian Shaw (Westminster Abbey) on no longer printing 12,000 sheets of paper a week (given out to visitors with that day's info). Made each order of service (dunno, church stuff, I am a heathen) at the same URL with templates to drop in commonly used content like hymns
It's a web page, not an app – more flexible, better affordances re your place on the page
Some loved the move to sustainability but others don't like having phones out in church.
Ultimately, be led by the problem you're trying to solve (and there's always a paper backup for no/dead phone folk)
Q&A discussion – take small steps, build on lessons learnt
#MuseTech2022 Onto the final panel, 'Funding digital – what two years worth of data tells us'
(It's funny when you have an insight into your own #MuseTech2022 life via a remark at a conference – the first ever museum team I worked in was 'Outreach' at Melbourne Museum, which combined my digital team with the learning team under the one director. I've always known that working in Outreach shaped my world view, but did sitting next to the learning team also shape it?)
And now Daf James is finishing with thanks for the committee members behind the MCG generally and the event in particular – big up @irny for keeping the tech going in difficult circumstances!
Daf James welcomes online and in-person attendees to the Museums Computer Group's Museums+Tech 2022 conference
This is a 'work in progress' post that I hope to add to as I gather information about national portals for crowdsourcing / citizen science / citizen history and other forms of voluntary digital / online participation.
While portals like SciStarter and platforms like Zooniverse, FromThePage, HistoryPin etc are a great way to search across projects for something that matches your interests, I'm interested in the growth of national portals or indexes to projects (they might also be called 'project finders'). It's not so much the sites themselves that interest me as the underlying networks of regional communities of practice, national or regional infrastructure and other signs of national support that they might variously reflect or help create. If you're interested in specific projects outside the UK-US/English-language bubble, check out Crowdsourcing the world's heritage. I've also shared a 2015 list of 'participatory digital heritage sites' that includes many crowdsourcing sites.
If you know of a national portal or umbrella organisation for crowdsourcing, please drop me a line! Last updated: Jan 16, 2025.
Austria
Jan Smeddinck emailed to share the LBG Open Innovation in Science Center https://ois.lbg.ac.at/
This post was inspired by the apparently coordinated approach in France. The Archives nationales participatives site has 'Projets collaboratifs de transcriptions, annotations et indexations' – that is, participatory national archives with collaborative transcription, annotation and indexing projects.
They also have Le réseau Particip-Arc, a 'network of actors committed to participatory science in the fields of culture', supported by the Ministry of Culture and coordinated by the National Museum of Natural History.
European Union
EU-citizen.science is a 'platform for sharing citizen science projects, resources, tools, training and much more'.
Agata Bochynska said, 'Norway has recently formed a national network for citizen science that’s coordinated by Research Council of Norway' – Nasjonalt nettverk for folkeforskning (folkeforskning translates as 'folk research' according to Google).
A Swedish national hub for everyone interested in citizen science (medborgarforskning). The project was funded by Vinnova – Sweden’s innovation agency, the University of Gothenburg, the Swedish University of Agricultural Sciences, Umeå University.
https://app.unv.org/ lists online and on-site (i.e. in-person) opportunities around the world, although some of them might stretch the definition of 'voluntary roles'.
As I'm speaking today at an event that's mostly in French, I'm sharing my slides outline so it can be viewed at leisure, or copy-and-pasted into a translation tool like Google Translate.
Colloque de clôture du projet Testaments de Poilus, Les Archives nationales de France, 25 Novembre 2022
Crowdsourcing as connection: a constant star over a sea of change, Mia Ridge, British Library
GLAM values as a guiding star
(Or, how will AI change crowdsourcing?) My argument is that technology is changing rapidly around us, but our skills in connecting people and collections are as relevant as ever:
Crowdsourcing connects people and collections
AI is changing GLAM work
But the values we express through crowdsourcing can light the way forward
(GLAM – galleries, libraries, archives and museums)
A sea of change
AI-based tools can now do many crowdsourced tasks:
Transcribe audio; typed and handwritten text
Classify / label images and text – objects, concepts, 'emotions'
AI-based tools can also generate new images, text
Deep fakes, emerging formats – collecting and preservation challenges
AI is still work-in-progress
Automatic transcription, translation failure from this morning: 'the encephalogram is no longer the mother of weeks'
Results have many biases; cannot be used alone
White, Western, 21st century view
Carbon footprint
Expertise and resources required
Not easily integrated with GLAM workflows
Why bother with crowdsourcing if AI will soon be 'good enough'?
The elephant in the room; been on my mind for a couple of years now
The rise of AI means we have to think about the role of crowdsourcing in cultural heritage. Why bother if software can do it all?
Crowdsourcing brings collections to life
Close, engaged attention to 'obscure' collection items
Opportunities for lifelong learning; historical and scientific literacy
Gathers diverse perspectives, knowledge
Crowdsourcing as connection
Crowdsourcing in GLAMs is valuable in part because it creates connections around people and collections
Between volunteers and staff
Between people and collections
Between collections
Examples from the British Library
In the Spotlight: designing for productivity and engagement
Living with Machines: designing crowdsourcing projects in collaboration with data scientists that attempt to both engage the public with our research and generate research datasets. Participant comments and questions inspired new tasks, shaped our work.
How do we follow the star?
Bringing 'crowdsourcing as connection' into work with AI
Valuing 'crowdsourcing as connection'
Efficiency isn't everything. Participation is part of our mission
Help technologists and researchers understand the value in connecting people with collections
Develop mutual understanding of different types of data – editions, enhancement, transcription, annotation
Perfection isn't everything – help GLAM staff define 'data quality' in different contexts
Where is imperfect, AI data at scale more useful than perfect but limited data?
'réinjectée' – when, where, and how?
How does crowdsourcing, AI change work for staff?
How do we integrate data from different sources (AI, crowdsourcing, cataloguers), at different scales, into coherent systems?
How do interfaces show data provenance, confidence?
Transforming access, discovery, use
A single digitised item can be infinitely linked to places, people, concepts – how does this change 'discovery'?
What other user needs can we meet through a combination of AI, better data systems and public participation?
I'm delighted to share my latest publication, a collaboration with 15 co-authors written in March and April 2021. It's the major output of my Collective Wisdom project, an AHRC-funded project I lead with Meghan Ferriter and Sam Blickhan.
We have published this first version of our collaborative text to provide early access to our work, and to invite comment and discussion from anyone interested in crowdsourcing, citizen science, citizen history, digital / online volunteer projects, programmes, tools or platforms with cultural heritage collections.
I'm curious to see how much of a difference this period of open comment makes. The comments so far have been quite specific and useful, but I'd like to know where we *really* got it right, and where we could include other examples. You need a pubpub account to comment but after that it's pretty straightforward – select text, and add a comment, or comment on an entire chapter.
Having some distance from the original writing period has been useful for me – not least, the realisation that the title should have been 'perspectives on crowdsourcing in cultural heritage and digital humanities'.


 I called my talk '57 varieties of digital history' as a play on the number of activities and outputs called 'digital history'. While digital history and digital humanities are often linked and have many methods in common, digital history also draws on the use of computers for quantitative work, and digitisation projects undertaken in museums, libraries, archives and academia. Digital tools have enhanced many of the tasks in the research process (which itself has many stages – I find the
I called my talk '57 varieties of digital history' as a play on the number of activities and outputs called 'digital history'. While digital history and digital humanities are often linked and have many methods in common, digital history also draws on the use of computers for quantitative work, and digitisation projects undertaken in museums, libraries, archives and academia. Digital tools have enhanced many of the tasks in the research process (which itself has many stages – I find the