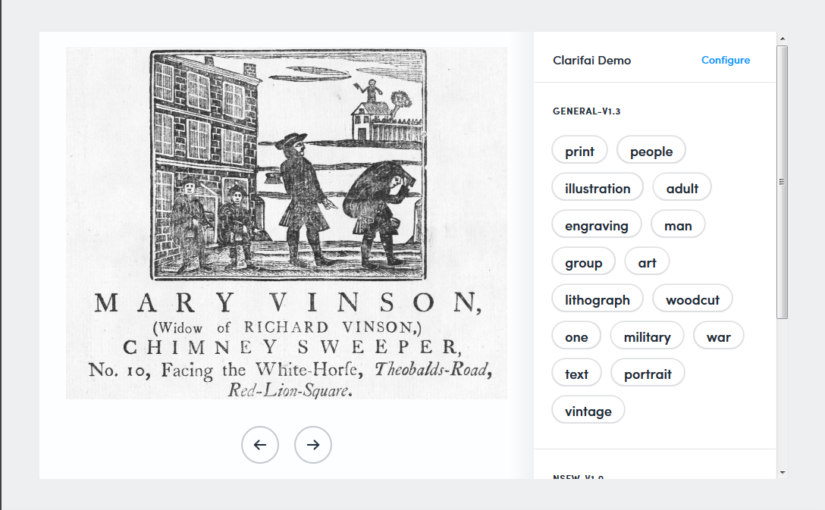
My rough notes from the Digital Humanities 2019 conference in Utrecht. All the usual warnings about partial attention / tendency for distraction apply. My comments are usually in brackets.
I found the most useful reference for the conference programme to be https://www.conftool.pro/dh2019/index.php?page=browseSessions&path=adminSessions&print=export&presentations=show but it doesn't show the titles or abstracts for papers within panels.
Some places me and my colleagues were during the conference: https://blogs.bl.uk/digital-scholarship/2019/07/british-library-digital-scholarship-at-digital-humanities-2019-.html http://livingwithmachines.ac.uk/living-with-machines-at-digital-humanities-2019/
DH2019 Keynote by Francis B. Nyamnjoh, 'African Inspiration for Understanding the Compositeness of Being Human through Digital Technology'
https://dh2019.adho.org/wp-content/uploads/2019/07/Nyamnjoh_Digital-Humanities-Keynote_2019.pdf
- Notion of complexity, and incompleteness familiar to Africa. Africans frown on attempts to simplify
- How do notions of incompleteness provide food for thought in digital humanities?
- Nyamnjoh decries the sense of superiority inspired by zero sum games. 'Humans are incomplete, nature is incomplete. Religious bit. No one can escape incompleteness.' (Phew! This is something of a mantra when you work with collections at scale – working in cultural institutions comes with a daily sense that the work is so large it will continue after you're just a memory. Let's embrace rather than apologise for it)
- References books by Amos Tutuola
- Nyamnjoh on hidden persuaders, activators. Juju as a technology of self-extension. With juju, you can extend your presence; rise beyond ordinary ways of being. But it can also be spyware. (Timely, on the day that Zoom was found to allow access to your laptop camera – this has positives and negatives)
- Nyamnjoh: DH as the compositeness of being; being incomplete is something to celebrate. Proposes a scholarship of conviviality that takes in practices from different academic disciplines to make itself better.
- Nyamnjoh in response to Micki K's question about history as a zero-sum game in which people argue whether something did or didn't happen: create archives that can tell multiple stories, complexify the stories that exist
DH2019 Day 1, July 10
LP-03: Space Territory GeoHumanities
https://www.conftool.pro/dh2019/index.php?page=browseSessions&path=adminSessions&print=export&ismobile=false&form_session=455&presentations=show Locating Absence with Narrative Digital Maps
How to combine new media production with DH methodologies to create kit for recording and locating in the field.
Why georeference? Situate context, comparison old and new maps, feature extraction, or exploring map complexity.
Maps Re-imagined: Digital, Informational, and Perceptional Experimentations in Progress by Tyng-Ruey Chuang, Chih-Chuan Hsu, Huang-Sin Syu used OpenStreetMap with historical Taiwanese maps. Interesting base map options inc ukiyo style https://bcfuture.github.io/tileserver/Switch.html
Oceanic Exchanges: Transnational Textual Migration And Viral Culture
https://www.conftool.pro/dh2019/index.php?page=browseSessions&path=adminSessions&print=export&ismobile=false&form_session=477&presentations=show Oceanic Exchanges studies the flow of information, searching for historical-literary connections between newspapers around the world; seeks to push the boundaries of research w newspapers
- Challenges: imperfect comparability of corpora – data is provided in different ways by each data provider; no unifying ontology between archives (no generic identification of specific items); legal restrictions; TEI and other work hasn't been suitable for newspaper research
- Limited ability to conduct research across repositories. Deep semantic multilingual text mining remains a challenge. Political (national) and practical organisation of archives currently determines questions that can be asked, privileges certain kinds of enquiry.
- Oceanic Exchanges project includes over 100 million pages. Corpus exploration tool needed to support: exploring data (metadata and text); other things that went by too quickly.
The Past, Present and Future of Digital Scholarship with Newspaper Collections
I was on this panel so I tweeted a bit but have no notes myself.
- My abstract: https://www.openobjects.org.uk/2019/07/the-past-present-and-future-of-digital-scholarship-with-newspaper-collections/
- My slides: https://www.slideshare.net/miaridge/living-with-machines-at-the-past-present-and-future-of-digital-scholarship-with-newspaper-collections-154700888
- See also: http://livingwithmachines.ac.uk/living-with-machines-at-digital-humanities-2019/
- @RossiAtanassova Laurel Brake: A researcher's wish list for digitised newspaper journals pic.twitter.com/rNmuuBOFb8
- @giovanni1085 @printjournalism list of existing (and very much felt) problems/challenges for digital media history. But, there is hope and we persevere #DH2019 pic.twitter.com/LSilbMi9vg
- @juliannenyhan Crucial points by @Ajprescott about necessity of developing critical frameworks for scholarship with digital newspapers that assist in helping us understand how & why digital newspaper collections take form they do & how e.g. power, bias & absence act on and through them #dh2019 pic.twitter.com/WSfjC2aq2t
Working with historical text (digitised newspapers, books, whatever) collections at scale has some interesting challenges and rewards. Inspired by all the newspaper sessions? Join an emerging community of practitioners, researchers and critical friends via this document from a 'DH2019 Lunch session – Researchers & Libraries working together on improving digitised newspapers' https://docs.google.com/document/d/1JJJOjasuos4yJULpquXt8pzpktwlYpOKrRBrCds8r2g/edit
- Zotero group for Historical Periodicals https://www.zotero.org/groups/704613/historical_periodicals
- Discussion list https://groups.google.com/forum/#!forum/digital-historical-periodica
Complexities, Explainability and Method
https://www.conftool.pro/dh2019/index.php?page=browseSessions&path=adminSessions&print=export&ismobile=false&form_session=486&presentations=show I enjoyed listening to this panel which is so far removed from my everyday DH practice.
Other stuff
Tweet: If you ask a library professional about digitisating (new word alert!) a specific collection and they appear to go quiet, this is actually what they're doing – digitisation takes shedloads of time and paperwork https://twitter.com/CamDigLib/status/1148888628405395456
Posters
- 'Why engage with digital source criticism' seems particularly relevant to our 'fake news' era https://ranke2.uni.lu pic.twitter.com/JxV83RFTY6
- Good 'DH for fun' poster https://correspsearch.net/quotesalute/ 'inspiring greetings for your correspondence'
- I missed the special poster session so excited to see PDFs and links at 'Digital Humanities – the perspective of Africa'https://dhafrica.blog/outcomes/
@LibsDH ADHO Lib & DH SIG meetup
There was a lunchtime meeting for 'Libraries and Digital Humanities: an ADHO Special Interest Group', which was a lovely chance to talk libraries / GLAMs and DH. You can join the group via https://docs.google.com/forms/d/e/1FAIpQLSfswiaEnmS_mBTfL3Bc8fJsY5zxhY7xw0auYMCGY_2R0MT06w/viewform or the mailing list at http://lists.digitalhumanities.org/mailman/listinfo/libdh-sig
DH2019 Day 2, July 11
XR in DH: Extended Reality in the Digital Humanities
Another panel where I enjoyed listening and learning about a field I haven't explored in depth. Tweet from the Q&A: 'Love the 'XR in DH: Extended Reality in the Digital Humanities' panel responses to a question about training students only for them to go off and get jobs in industry: good! Industry needs diversity, PhDs need to support multiple career paths beyond academia'
Data Science & Digital Humanities: new collaborations, new opportunities and new complexities
https://www.conftool.pro/dh2019/index.php?page=browseSessions&path=adminSessions&print=export&ismobile=false&form_session=532&presentations=show Beatrice Alex, Anne Alexander, David Beavan, Eirini Goudarouli, Leonardo Impett, Barbara McGillivray, Nora McGregor, Mia Ridge
My work with open cultural data has led to me asking 'how can GLAMs and data scientists collaborate to produce outcomes that are useful for both?'. Following this, I presented a short paper, more info at https://www.openobjects.org.uk/2019/07/in-search-of-the-sweet-spot-infrastructure-at-the-intersection-of-cultural-heritage-and-data-science/ https://www.slideshare.net/miaridge/in-search-of-the-sweet-spot-infrastructure-at-the-intersection-of-cultural-heritage-and-data-science.
As summarised in tweets:
- https://twitter.com/semames1/status/1149250799232540672, 'data science can provide new routes into library collections; libraries can provide new challenging sources of information (scale, untidy data) for data scientists';
- https://twitter.com/sp_meta/status/1149251010025656321 'library staff are often assessed by strict metrics of performance – items catalog, speed of delivery to reading room – that isn’t well-matched to messy, experimental collaborations with data scientists';
- https://twitter.com/melissaterras/status/1149251480576303109 'Copyright issues are inescapable… they are the background noise to what we do';
- https://twitter.com/sp_meta/status/1149251656720289792 'How can library infrastructure change to enable collaboration with data scientists, encouraging use of collections as data and prompting researchers to share their data and interpretations back?';
- (me) 'I'm wondering about this dichotomy between 'new' or novel, and 'useful' or applied – is there actually a sweet spot where data scientists can work with DH / GLAMs or should we just apply data science methods and also offer collections for novel data science research? Thinking of it as a scale of different aspects of 'new to applied research' rather than a simple either/or'.
SP-19: Cultural Heritage, Art/ifacts and Institutions
“Un Manuscrit Naturellement ” Rescuing a library buried in digital sand
- 1979, agreement with Ministry of Culture and IRHT to digitise all manuscripts stored in French public libraries. (Began with microfilm, not digital). Safe, but not usable. Financial cost of preserving 40TB of data was prohibitive, but BnF started converting TIFFs to JP2 which made storage financially feasible. Huge investment by France in data preservation for digitised manuscripts.
- Big data cleaning and deduplication process, got rid of 1 million files. Discovered errors in TIFF when converting to JP2. Found inconsistencies with metadata between databases and files. 3 years to do the prep work and clean the data!
- ‘A project which lasts for 40 years produces a lot of variabilities’. Needed a team, access to proper infrastructure; the person with memory of the project was key.
A Database of Islamic Scientific Manuscripts — Challenges of Past and Future
- (Following on from the last paper, digital preservation takes continuous effort). Moving to RDF model based on CIDOC-CRM, standard triple store database, standard ResearchSpace/Metaphactory front end. Trying to separate the data from the software to make maintenance easier.
Analytical Edition Detection In Bibliographic Metadata; The Emerging Paradigm of Bibliographic Data Science
- Tweet: Two solid papers on a database for Islamic Scientific Manuscripts and data science work with the ESTC (English Short Title Catalogue) plus reflections on the need for continuous investment in digital preservation. Back on familiar curatorial / #MuseTech ground!
- Lahti – Reconciling / data harmonisation for early modern books is so complex that there are different researchers working on editions, authors, publishers, places
Syriac Persons, Events, and Relations: A Linked Open Factoid-based Prosopography
- Prosopography and factoids. His project relies heavily on authority files that http://syriaca.org/ produces. Modelling factoids in TEI; usually it’s done in relational databases.
- Prosopography used to be published as snippets of narrative text about people that enough information was available about
- Factoid – a discrete piece of prosopographical information asserted in a primary source text and sourced to that text.
- Person, event and relation factoids. Researcher attribution at the factoid level. Using TEI because (as markup around the text) it stays close to the primary source material; can link out to controlled vocabulary
- Srophe app – an open source platform for cultural heritage data used to present their prosopographical data https://srophe.app/
- Harold Short says how pleased he is to hear a project like that taking the approach they have; TEI wasn’t available as an option when they did the original work (seriously beautiful moment)
- Why SNAP? ‘FOAF isn’t really good at describing relationships that have come about as a result of slave ownership’
- More on factoid prosopography via Arianna Ciula https://factoid-dighum.kcl.ac.uk/
Day 3, July 12
Complexities in the Use, Analysis, and Representation of Historical Digital Periodicals
- Torsten Roeder: Tracing debate about a particular work through German music magazines and daily newspapers. OCR and mass digitisation made it easier to compose representative text corpora about specific subjects. Authorship information isn’t available so don’t know their backgrounds etc, means a different form of analysis. ‘Horizontal reading’ as a metaphor for his approach. Topic modelling didn’t work for looking for music criticism.
- Roeder's requirements: accessible digital copies of newspapers; reliable metadata; high quality OCR or transcriptions; article borders; some kind of segmentation; deep semantic annotation – ‘but who does what?’ What should collection holders / access providers do, and what should researchers do? (e.g. who should identify entities and concepts within texts? This question was picked up in other discussion in the session, on twitter and at an impromptu lunchtime meetup)
- Zeg Segal. The Periodical as a Geographical Space. Relation between the two isn’t unidirectional. Imagined space constructed by the text and its layout. Periodicals construct an imaginary space that refers back to the real. Headlines, para text, regular text. Divisions between articles. His case study for exploring the issues: HaZefirah. (sample slide image https://twitter.com/mia_out/status/1149581497680052224)
- Nanette Rißler-Pipka, Historical Periodicals Research, Opportunities and Limitations. The limitations she encounters as a researcher. Building a corpus of historical periodicals for a research question often means using sources from more than one provider of digitised texts. Different searches, rights, structure. (The need for multiple forms of interoperability, again)
- Wants article / ad / genre classifications. For metadata wants, bibliographical data about the title (issue, date); extractable data (dates, names, tables of contents), provenance data (who digitised, when?). When you download individual articles, you lose the metadata which would be so useful for research. Open access is vital; interoperability is important; the ability to create individual collections across individual libraries is a wonderful dream
- Estelle Bunout. Impresso providing exploration tools (integrate and decomplexify NLP tools in current historical research workflows). https://impresso-project.ch/app/#/
- Working on: expanding a query – find neighbouring terms and frequent OCR errors. Overview of query: where and when is it? Whole corpus has been processed with topic modelling.
- Complex queries: help me find the mention of places, countries, person in a particular thematic context. Can save to collection or export for further processing.
- See the unsearchable: missing issues, failure to digitise issues, failure to OCRise, corrupt files
- Transparency helps researchers discover novel opportunities and make informed decisions about sources.
- Clifford Wulfman – how to support transcriptions, linked open data that allows exploration of notions of periodicity, notions of the periodical. My tweet: Clifford Wulfman acknowledging that libraries don't have the resources to support special 'snowflake' projects because they're working to meet the most common needs. IME this question/need doesn't go away so how best to tackle and support it?
- Q&A comment: what if we just put all newspapers on Impresso? Discussion of standardisation, working jointly, collaborating internationally
- Melodee Beals comments: libraries aren’t there just to support academic researchers, academics could look to supporting the work of creative industries, journalists and others to make it easier for libraries to support them.
- Subject librarian from Leiden University points out that copyright limits their ability to share newspapers after 1880. (Innovating is hard when you can't even share the data)
- Nanette Rißler says researchers don't need fancy interfaces, just access to the data (which probably contradicts the need for 'special snowflake' systems and explains why libraries can never ever make all users happy)
LP-34: Cultural Heritage, Art/ifacts and Institutions
(I was chairing so notes are sketchier)
- Mark Hill, early modern (1500-1800 but 18thC in particular) definitions of ‘authorship’. How does authorship interact with structural aspects of publishing? Shift of authorship from gentlemanly to professional occupation.
- Using the ESTC. Has about 1m actors, 400k documents with actors attached to them. Actors include authors, editors, publishers, printers, translators, dedicatees. Early modern print trade was ‘trade on a human scale’. People knew each other ‘hand-operated printing press required individual actors and relationships’.
- As time goes on, printers work with fewer, publishers work with more people, authors work with about the same number of people.
- They manually created a network of people associated with Bernard Mandeville and compared it with a network automatically generated from ESTC.
- Looking at a work network for Edmond Hoyle’s Short Treatise on the Game of Whist. (Today I learned that Hoyle's Rules, determiner of victory in family card games and of 'according to Hoyle' fame, dates back to a book on whist in the 18thC)
- (Really nice use of social network analysis to highlight changes in publisher and authorship networks.) Eigenvector very good at finding important actors. In the English Civil War, who you know does matter when it comes to publishing. By 18thC publishers really matter. See http://ceur-ws.org/Vol-2364/19_paper.pdf for more.
Richard Freedman, David Fiala, Andrew Janco et al
- What is a musical quotation? Borrowing, allusion, parody, commonplace, contrafact, cover, plagiat, sampling, signifying.
- Tweet: Freedman et al.'s slides for 'Citations: The Renaissance Imitation Mass (CRIM) and The Quotable Musical Text in a Digital Age' https://bit.ly/CRIM_Utrecht are a rich introduction to applications of #DigitalMusicology encoding and markup
- I spend so much time in text worlds that it's really refreshing to hear from musicologists who play music to explain their work and place so much value on listening while also exploiting digital processing tools to the max
Digging Into Pattern Usage Within Jazz Improvisation (Pattern History Explorer, Pattern Search and Similarity Search) Frank Höger, Klaus Frieler, Martin Pfleiderer
- 'Dig that lick' jazz similarity search engine https://dig-that-lick.hfm-weimar.de/pattern_search/
Impromptu meetup to discuss issues raised around digitised newspapers research and infrastructure
See notes about DH2019 Lunch session – Researchers & Libraries working together on improving digitised newspapers. 20 or more people joined us for a discussion of the wonderful challenges and wish lists from speakers, thinking about how we can collaborate to improve the provision of digitised newspapers / periodicals for researchers.
- https://twitter.com/saschel/status/1149640870628483072
- Inspired by conversations about digitised newspapers at #DH2019? Think about the points / rants / lessons you’d share in manifestos by/for researchers and GLAMs
Theorising the Spatial Humanities panel
- ?? Space as a container for understanding, organising information. Chorography, the writing of the region.
- Tweet: In the spatial humanities panel where a speaker mentions chorography, which along with prosopography is my favourite digital-history-enabled-but-also-old concept
- Daniel Alves. Do history and literature researchers feel the need to incorporate spatial analysis in their work? A large number who do don’t use GIS. Most of them don’t believe in it (!). The rest are so tired that they prefer theorising (!!) His goal, ref last night keynote, is not to build models, tools, the next great algorithm; it’s to advance knowledge in his specific field.
- Tweet: @DanielAlvesFCSH Is #SpatialDH revolutionary? Do history and literature researchers feel the need to incorporate spatial analysis in their work? A large number who do don’t use GIS. Most of them don’t believe in it(!). The rest are so tired that they prefer theorising(!!)
- Tweet: @DanielAlvesFCSH close reading is still essential to take in the inner subjectivity of historical / literary sources with a partial and biases conception of space and place
- Tien Danniau, Ghent Centre for Digital Humanities – deep maps. How is the concept working for them?
- Tweet: Deep maps! A slide showing some of the findings from the 2012 NEH Advanced Institute on spatial narratives and deep mapping, which is where I met many awesome DH and spatial history people #DH2019pic.twitter.com/JiQepz7kH5
- Katie McDonough, Spatial history between maps and texts: lessons from the 18thC. Refers to Richard White’s spatial history essay in her abstract. Rethinking geographic information extraction. Embedded entities, spatial relations, other stuff.
- Tweet: @khetiwe24 references work discussed in https://www.tandfonline.com/doi/abs/10.1080/13658816.2019.1620235?journalCode=tgis20 … noting how the process of annotating texts requires close reading that changes your understanding of place in the text (echoing @DanielAlvesFCSH 's earlier point)
- Tweet: Final #spatialDH talk 'towards spatial linguistics' #DH2019 https://twitter.com/mia_out/status/1149666605258829824
- Tweet #DH2019 Preserving deep maps? I'd talk to folk in web archiving for a sense of which issues re recording complex, multi-format, dynamic items are tricky and which are more solveable
Closing keynote: Digital Humanities — Complexities of Sustainability, Johanna Drucker
(By this point my laptop and mental batteries were drained so I just listened and tweeted. I was also taking part in a conversation about the environmental sustainability of travel for conferences, issues with access to visas and funding, etc, that might be alleviated by better incorporating talks from remote presenters, or even having everyone present online.)
Finally, the DH2020 conference is calling for reviewers. Reviewing is an excellent way to give something back to the DH community while learning about the latest work as it appears in proposals, and perhaps more importantly, learning how to write a good proposal yourself. Find out more: http://dh2020.adho.org/cfps/reviewers/