I've developed this exercise on computational data generation and entity extraction for various information/data visualisation workshops I've been teaching lately. These exercises help demonstrate the biases embedded in machine learning and 'AI' tools. As these methods have become more accessible, my dataviz workshops have included more discussion of computational methods for generating data to be visualised. There are two versions of the exercise – the first works with images, the second with text.
In teaching I've found that services that describe images were more accessible and generated richer discussion in class than text-based sites, but it's handy to have the option for people who work with text. If you try something like this in your classes I'd love to hear from you.
It's also a chance to talk about the uses of these technologies in categorising and labelling our posts on social media. We can tell people that their social media posts are analysed for personality traits and mentions of brands, but seeing it in action is much more powerful.
Image exercise: trying computational data generation and entity extraction
Time: c. 5 – 10 minutes plus discussion.
Goal: explore methods for extracting information from text or an image and reflect on what the results tell you about the algorithms
1. Find a sample image
Find an image (e.g. from a news site or digitised text) you can download and drag into the window. It may be most convenient to save a copy to your desktop. Many sites let you load images from a URL, so right- or control-clicking to copy an image location for pasting into the site can be useful.
2. Work in your browser
It's probably easiest to open each of these links in a new browser window. It's best to use Firefox or Chrome, if you can. Safari and Internet Explorer may behave slightly differently on some sites. You should not need to register to use these sites – please read the tips below or ask for help if you get stuck.
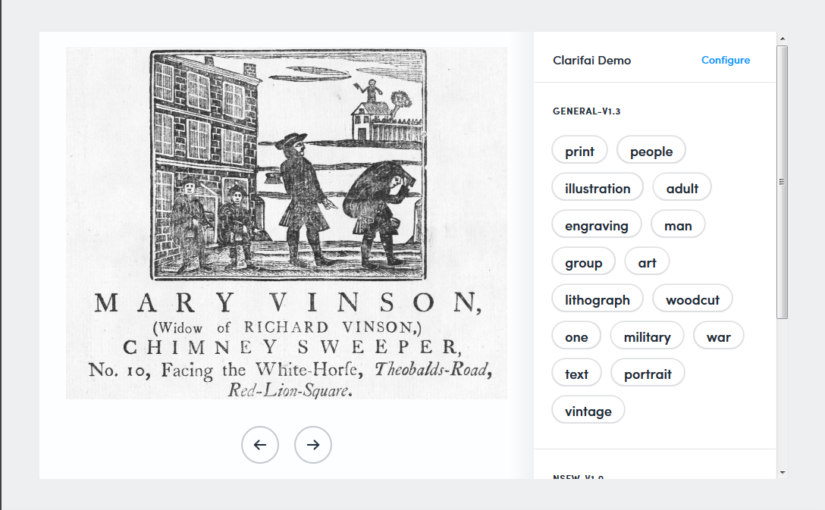
- Clarifai https://www.clarifai.com/demo – you can drag and drop, open the file explorer to find an image, or load one from a URL via the large '+' in the bottom right-hand corner. You can adjust settings via the 'Configure' tab.
- Google Cloud Vision API https://cloud.google.com/vision/ – don't sign up, scroll down to the 'Try the API' box. Drag and drop your image on the box or click the box to open the file finder. You may need to go through the 'I am not a robot' process.
- Microsoft Computer Vision API https://www.microsoft.com/cognitive-services/en-us/computer-vision-api – scroll to 'Analyze an image'. You can use one of their sample images, paste a URL and hit 'Submit', or click on the 'browse' button to upload your own image.
- IBM Watson Visual Recognition https://visual-recognition-demo.mybluemix.net/ – scroll to 'Try the service'. Drag an image onto the grey box or click in the grey box to open the file finder. You can also load an image directly from a URL. (You can no longer try this without signing up so it doesn't work for a quick exercise).
- Blippar https://developer.blippar.com/portal/vs-api/index/#demoSection – scroll to the 'Analyze any image' section – the upload and URL options are below the sample images and tags
- Caffe http://demo.caffe.berkeleyvision.org/ – provide a URL or upload an image
3. Review the outputs
Make notes, or discuss with your neighbour. Be prepared to report back to the group.
- What attributes does each tool report on?
- Which attributes, if any, were unique to a service?
- Based on this, what do companies like Clarifai, Google, IBM and Microsoft seem to think is important to them (or to their users)? (e.g. what does 'safe for work' really mean?)
- Who are their users – the public or platform administrators?
- How many of possible entities (concepts, people, places, events, references to time or dates, etc) did it pick up?
- Is any of the information presented useful?
- Did it label anything incorrectly?
- What options for exporting or saving the results did the demo offer? What about the underlying service or software?
- For tools with configuration options – what could you configure? What difference did changing classifiers or other parameters make?
- If you tried it with a few images, did it do better with some than others? Why might that be?
Text exercise: trying computational data generation and entity extraction
Time: c. 5 minutes plus discussion
Goal: explore the impact of source data and algorithms on input text
1. Grab some text
You will need some text for this exercise. The more 'entities' – people, places, dates, concepts – discussed, the better. If you have some text you're working on handy, you can use that. If you're stuck for inspiration, pick a front page story from an online news site. Keep the page open so you can copy a section of text to paste into the websites.
2. Compare text entity labelling websites
- Open four or more browser windows or tabs. Open the links below in separate tabs or windows so you can easily compare the results.
- Go to DBpedia Spotlight https://dbpedia-spotlight.github.io/demo/. Paste your copied text into the box, or keep the sample text in the box. Hit 'Annotate'.
- Go to Ontotext http://tag.ontotext.com/. You may need to click through the opening screen. Paste your copied text into the box. Hit 'annotate'.
- Finally, go to Stanford Named Entity Tagger http://nlp.stanford.edu:8080/ner/. Paste your text into the box. Hit 'Submit query'.
3. Review the outputs
- How many possible entities (concepts, people, places, events, references to time or dates, etc) did each tool pick up? Is any of the other information presented useful?
- Did it label anything incorrectly?
- What if you change classifiers or other parameters?
- Does it do better with different source material?
- What differences did you find between the two tools? What do you think caused those differences?
- How much can you find out about the tools and the algorithms they use to create labels?
- Where does the data underlying the process come from?
Spoiler alert!
.@mia_out: "According to image recognition software, the world can be divided into safe for work & not safe for work" #beyondtheblackbox
— Anouk Lang (@a_e_lang) February 15, 2017
One thought on “Trying computational data generation and entity extraction for images and text”