As I'm speaking today at an event that's mostly in French, I'm sharing my slides outline so it can be viewed at leisure, or copy-and-pasted into a translation tool like Google Translate.
Colloque de clôture du projet Testaments de Poilus, Les Archives nationales de France, 25 Novembre 2022
Crowdsourcing as connection: a constant star over a sea of change, Mia Ridge, British Library
GLAM values as a guiding star
(Or, how will AI change crowdsourcing?) My argument is that technology is changing rapidly around us, but our skills in connecting people and collections are as relevant as ever:
- Crowdsourcing connects people and collections
- AI is changing GLAM work
- But the values we express through crowdsourcing can light the way forward
(GLAM – galleries, libraries, archives and museums)
A sea of change
AI-based tools can now do many crowdsourced tasks:
- Transcribe audio; typed and handwritten text
- Classify / label images and text – objects, concepts, 'emotions'
AI-based tools can also generate new images, text
- Deep fakes, emerging formats – collecting and preservation challenges
AI is still work-in-progress
Automatic transcription, translation failure from this morning: 'the encephalogram is no longer the mother of weeks'
- Results have many biases; cannot be used alone
- White, Western, 21st century view
- Carbon footprint
- Expertise and resources required
- Not easily integrated with GLAM workflows
Why bother with crowdsourcing if AI will soon be 'good enough'?
The elephant in the room; been on my mind for a couple of years now
The rise of AI means we have to think about the role of crowdsourcing in cultural heritage. Why bother if software can do it all?
Crowdsourcing brings collections to life
- Close, engaged attention to 'obscure' collection items
- Opportunities for lifelong learning; historical and scientific literacy
- Gathers diverse perspectives, knowledge
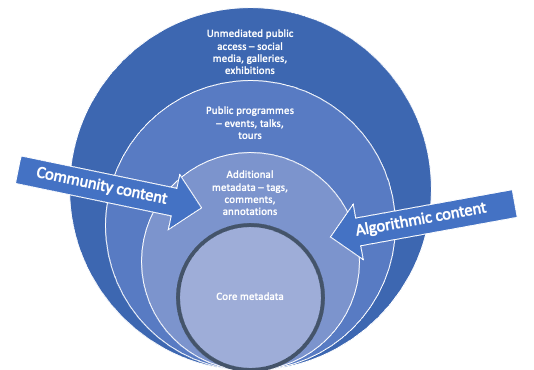
Crowdsourcing as connection
Crowdsourcing in GLAMs is valuable in part because it creates connections around people and collections
- Between volunteers and staff
- Between people and collections
- Between collections
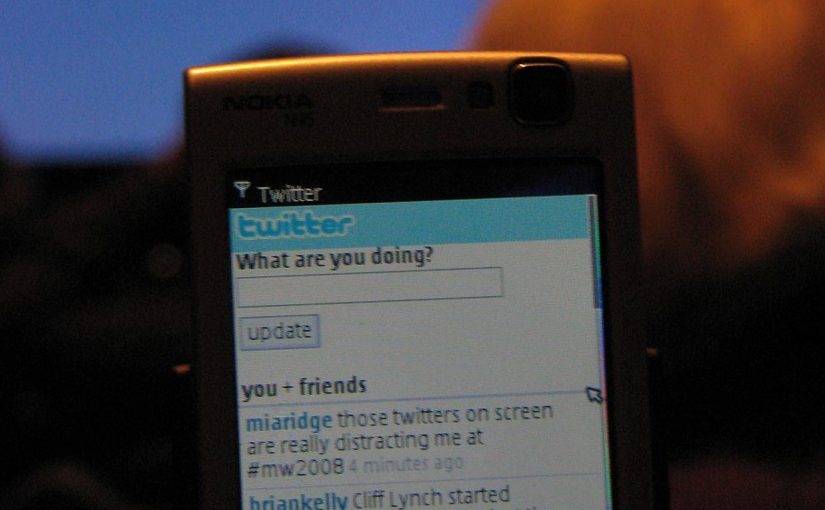
Examples from the British Library
In the Spotlight: designing for productivity and engagement
Living with Machines: designing crowdsourcing projects in collaboration with data scientists that attempt to both engage the public with our research and generate research datasets. Participant comments and questions inspired new tasks, shaped our work.
How do we follow the star?
Bringing 'crowdsourcing as connection' into work with AI
Valuing 'crowdsourcing as connection'
- Efficiency isn't everything. Participation is part of our mission
- Help technologists and researchers understand the value in connecting people with collections
- Develop mutual understanding of different types of data – editions, enhancement, transcription, annotation
- Perfection isn't everything – help GLAM staff define 'data quality' in different contexts
- Where is imperfect, AI data at scale more useful than perfect but limited data?
- 'réinjectée' – when, where, and how?
- How does crowdsourcing, AI change work for staff?
- How do we integrate data from different sources (AI, crowdsourcing, cataloguers), at different scales, into coherent systems?
- How do interfaces show data provenance, confidence?
Transforming access, discovery, use
- A single digitised item can be infinitely linked to places, people, concepts – how does this change 'discovery'?
- What other user needs can we meet through a combination of AI, better data systems and public participation?
Merci de votre attention!
Pour en savoir plus: https://bl.uk/digital https://livingwithmachines.ac.uk
Essayez notre activité de crowdsourcing: http://bit.ly/LivingWithMachines
Nous attendons vos questions: digitalresearch@bl.uk