In September I was invited to give a keynote at the Museum Theme Days 2016 in Helsinki. I spoke on 'Reaching out: museums, crowdsourcing and participatory heritage. In lieu of my notes or slides, the video is below. (Great image, thanks YouTube!)
Two YouGov posts on American and British people's knowledge of their recent family history provide some useful figures on how many people in each region have researched family history.
iNaturalist Bioblitz's are also more evidence for the value of time-limited challenges, or as they describe them, 'a communal citizen-science effort to record as many species within a designated location and time period as possible'.
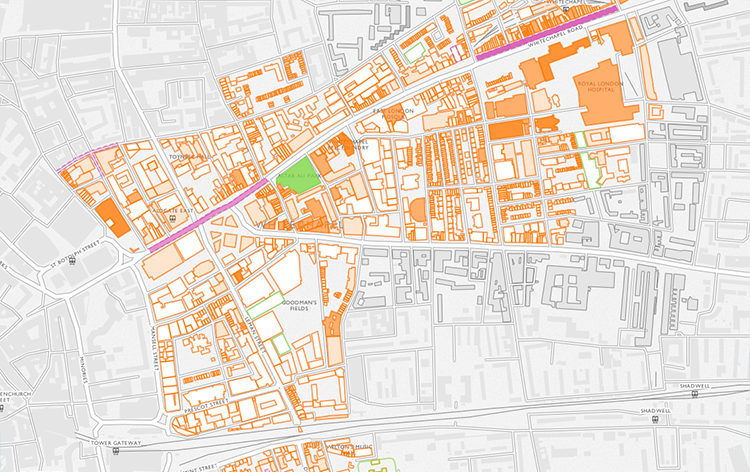
Survey of London and CASA launched the Histories of Whitechapel website, providing 'a new interactive map for exploring the Survey’s ongoing research into Whitechapel' and 'inviting people to submit their own memories, research, photographs, and videos of the area to help us uncover Whitechapel’s long and rich history'.
New Zooniverse project Mapping Change: 'Help us use over a century's worth of specimens to map the distribution of animals, plants, and fungi. Your data will let us know where species have been and predict where they may end up in the future!'
New Europeana project Europeana Transcribe: 'a crowdsourcing initiative for the transcription of digital material from the First World War, compiled by Europeana 1914-1918. With your help, we can create a vast and fully digital record of personal documents from the collection.'
'Holiday pictures help preserve the memory of world heritage sites' introduces Curious Travellers, a 'data-mining and crowd sourced infrastructure to help with digital documentation of archaeological sites, monuments and heritage at risk'. Or in non-academese, send them your photos and videos of threatened historic sites, particularly those in 'North Africa, including Cyrene in Libya, as well as those in Syria and the Middle East'.
I've added two new international projects, Les herbonautes, a French herbarium transcription project led by the Paris Natural History Museum, and Loki a Finnish project on maritime, coastal history to my post on Crowdsourcing the world's heritage – as always, let me know of other projects that should be included.
A small* collection of links from the past little while.
Projects
A new Zooniverse project, Decoding the Civil War, launched in June: 'Witness the United States Civil War by transcribing and deciphering messages and codes from the United States Military Telegraph'.
Another Zooniverse project, Camera CATalogue: 'Analyze Wildlife Photos to Help Panthera Protect Big Cats'.
Dillon, Justin, Robert B. Stevenson, and Arjen E. J. Wals, ‘Introduction: Special Section: Moving from Citizen to Civic Science to Address Wicked Conservation Problems’, Conservation Biology, 30 (2016), 450–55 <http://dx.doi.org/10.1111/cobi.12689> – has an interesting new model, putting citizen sciences 'on a continuum from highly instrumental forms driven by experts or science to more emancipatory forms driven by public concern. The variations explain why citizens participate in CS and why scientists participate too. To advance the conversation, we distinguish between three strands or prototypes: science-driven CS, policy-driven CS, and transition-driven civic science.'
…
'We combined Jickling and Wals’ (2008) heuristic for understanding environmental and sustainability education (Jickling & Wals 2008) and M. Fox and R. Gibson's problem typology (Fig. 1) to provide an overview of the different possible configurations of citizen science (Fig. 2). The heuristic has 2 axes. We call the horizontal axis the participation axis, along which extend the possibilities (increasing from left to right) for stakeholders, including the public, to participate in setting the agenda; determining the questions to be addressed; deciding the mechanisms and tools to be used; choosing how to monitor, evaluate, and interpret data; and choosing the course of action to take. The vertical (goal) axis shows the possibilities for autonomy and self-determination in setting goals and objectives. The resulting quadrants correspond to a particular strand of citizen science. All three occupied quadrants are important and legitimate.'
A heuristic of citizen science based on Wals and Jickling (2008). From Dillon, Justin, Robert B. Stevenson, and Arjen E. J. Wals (2016)
* It's a short list this month as I've been busy and things seem quieter over the northern hemisphere summer.
A quick signal boost for the collaborative notes taken at the DH2016 Expert Workshop: Beyond The Basics: What Next For Crowdsourcing? (held in Kraków, Poland, on 12 July as part of the Digital Humanities 2016 conference, abstract below). We'd emphasised the need to document the unconference-style sessions (see FAQ) so that future projects could benefit from the collective experiences of participants. Since it can be impossible to find Google Docs or past tweets, I've copied the session overview below. The text is a summary of key takeaways or topics discussed in each session, created in a plenary session at the end of the workshop.
Key takeaway – questions for projects to ask at the start; don't impose your own ethics on a project, discussing them is start of designing the project.
Where to start
Engaging volunteers, tips including online communities, being open to levels of contribution, being flexible, setting up standards, quality
Workflow, lifecycle, platforms
What people were up to, the problems with hacking systems together, iiif.io, flexibility and workflows
Options, schemas and goals for text encoding
Encoding systems will depend on your goals; full-text transcription always has some form of encoding, data models – who decides what it is, and when? Then how are people guided to use it?Trying to avoid short-term solutions
UX, flow, motivation
Making tasks as small as possible; creating a sense of contribution; creating a space for volunteers to communicate; potential rewards, issues like badgefication and individual preferences. Supporting unexpected contributions; larger-scale tasks
Project scale – thinking ahead to ending projects technically, and in terms of community – where can life continue after your project ends
Finding and engaging volunteers
Using social media, reliance on personal networks, super-transcribers, problematic individuals who took more time than they gave to the project. Successful strategies are very-project dependent. Something about beer (production of Itinera Nova beer with label containing info on the project and link to website).
Ecosystems and automatic transcription
Makes sense for some projects, but not all – value in having people engage with the text. Ecosystem – depending on goals, which parts work better? Also as publication – editions, corpora – credit, copyright, intellectual property
Plenary session, possible next steps – put information into a wiki. Based around project lifecycle, critical points? Publication in an online journal? Updateable, short-ish case studies. Could be categorised by different attributes. Flexible, allows for pace of change. Illustrate principles, various challenges.
Crowdsourcing – asking the public to help with inherently rewarding tasks that contribute to a shared, significant goal or research interest related to cultural heritage collections or knowledge – is reasonably well established in the humanities and cultural heritage sector. The success of projects such as Transcribe Bentham, Old Weather and the Smithsonian Transcription Center in processing content and engaging participants, and the subsequent development of crowdsourcing platforms that make launching a project easier, have increased interest in this area. While emerging best practices have been documented in a growing body of scholarship, including a recent report from the Crowd Consortium for Libraries and Archives symposium, this workshop looks to the next 5 – 10 years of crowdsourcing in the humanities, the sciences and in cultural heritage. The workshop will gather international experts and senior project staff to document the lessons to be learnt from projects to date and to discuss issues we expect to be important in the future.
The workshop is organised by Mia Ridge (British Library), Meghan Ferriter (Smithsonian Transcription Centre), Christy Henshaw (Wellcome Library) and Ben Brumfield (FromThePage).
In my presentation, I responded to some of the questions posed in the workshop outline:
In this workshop we want to explore how network visualisations and infrastructures will change the research and outreach activities of cultural heritage professionals and historians. Among the questions we seek to discuss during the workshop are for example: How do users benefit from graphs and their visualisation? Which skills do we expect from our users? What can we teach them? Are SNA [social network analysis] theories and methods relevant for public-facing applications? How do graph-based applications shape a user’s perception of the documents/objects which constitute the data? How can applications benefit from user engagement? How can applications expand and tap into other resources?
A rough version of my talk notes is below. The original slides are also online.
Network visualisations and the 'so what?' problem
Caveat
While I may show examples of individual network visualisations, this talk isn't a critique of them in particular. There's lots of good practice around, and these lessons probably aren't needed for people in the room.
Fundamentally, I think network visualisations can be useful for research, but to make them more effective tools for outreach, some challenges should be addressed.
Context
I'm a Digital Curator at the British Library, mostly working with pre-1900 collections of manuscripts, printed material, maps, etc. Part of my job is to help people get access to our digital collections. Visualisations are a great way to firstly help people get a sense of what's available, and then to understand the collections in more depth.
I've been teaching versions of an 'information visualisation 101' course at the BL and digital humanities workshops since 2013. Much of what I'm saying now is based on comments and feedback I get when presenting network visualisations to academics, cultural heritage staff (who should be a key audience for social network analyses).
Provocation: digital humanists love network visualisations, but ordinary people say, 'so what'?
And this is a problem. We're not conveying what we're hoping to convey.
Network visualisation http://fredbenenson.com
When teaching datavis, I give people time to explore examples like this, then ask questions like 'Can you tell what is being measured or described? What do the relationships mean?'. After talking about the pros and cons of network visualisations, discussion often reaches a 'yes, but so what?' moment.
Here are some examples of problems ordinary people have with network visualisations…
Location matters
Spatial layout based on the pragmatic aspects of fitting something on the screen using physics, rules of attraction and repulsion doesn't match what people expect to see. It's really hard for some to let go of the idea that spatial layout has meaning. The idea that location on a page has meaning of some kind is very deeply linked to their sense of what a visualisation is.
Animated physics is … pointless?
People sometimes like the sproinginess when a network visualisation resettles after a node has been dragged, but waiting for the animation to finish can also be slow and irritating. Does it convey meaning? If not, why is it there?
Size, weight, colour = meaning?
The relationship between size, colour, weight isn't always intuitive – people assume meaning where there might be none.
In general, network visualisations are more abstract than people expect a visualisation to be.
'What does this tell me that I couldn't learn as quickly from a sentence, list or table?'
Table of data, via http://fredbenenson.com/
Scroll down the page that contains the network graph above and you get other visualisations. Sometimes they're much more positively received, particularly people feel they learn more from them than from the network visualisation.
Onto other issues with 'network visualisations as communication'…
Which algorithmic choices are significant?
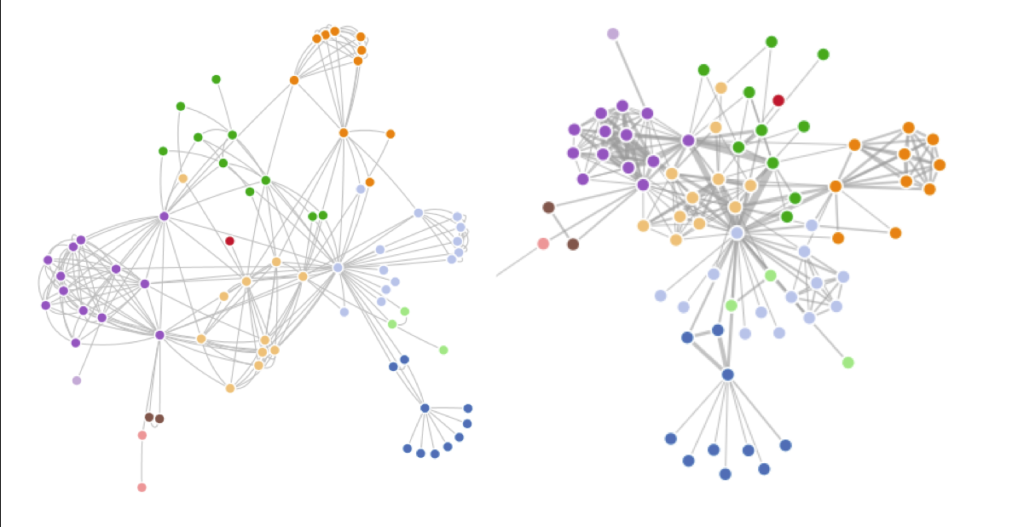
Mike Bostock's force-directed and curved line versions of character co-occurrence in Les Misérables
It's hard for novices to know which algorithmic and data-cleaning choices are significant, and which have a more superficial impact.
Untethered images
Images travel extremely well on social media. When they do so, they often leave information behind and end up floating in space. Who created this, and why? What world view does it represent? What source material underlies it, how was it manipulated to produce the image? Can I trust it?
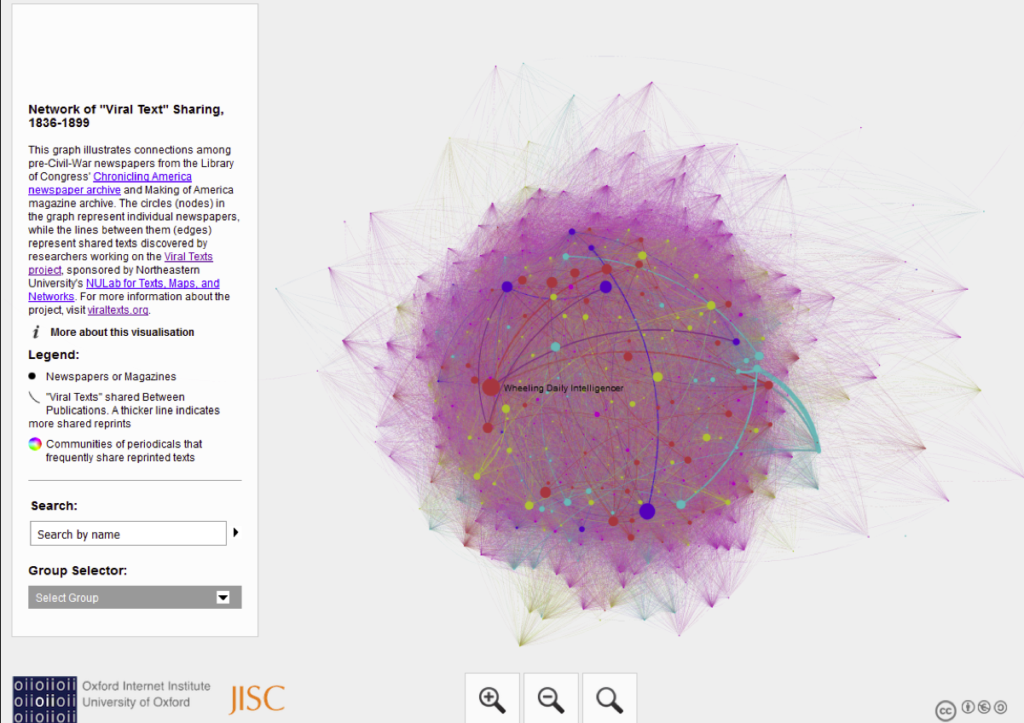
'Can't see the wood for the trees'
When I showed this to a class recently, one participant was frustrated that they couldn't 'see the wood for the trees'. The visualisations gives a general impression of density, but it's not easy to dive deeper into detail.
Stories vs hairballs
But when I started to explain what was being represented – the ways in which stories were copied from one newspaper to another – they were fascinated. They might have found their way there if they'd read the text but again, the visualisation is so abstract that it didn't hint at what lay underneath. (Also I have only very, very rarely seen someone stop to read the text before playing with a visualisation.)
No sense of change over time
This flattening of time into one simultaneous moment is more vital for historical networks than for literary ones, but even so, you might want to compare relationships between sections of a literary work.
No sense of texture, detail of sources
All network visualisations look similar, whether they're about historical texts or cans of baked beans. Dots and lines mask texture, and don't always hint at the depth of information they represent.
There's a lot to take on to really understand what's being expressed in a network graph.
There is some hope…
Onto the positive bit!
Interactivity is engaging
People find the interactive movement, the ability to zoom and highlight links engaging, even if they have no idea what's being expressed. In class, people started to come up with questions about the data as I told them more about what was represented. That moment of curiosity is an opportunity if they can dive in and start to explore what's going on, what do the relationships mean?
…but different users have different interaction needs
For some, there's that frustration expressed earlier they 'can't get to see a particular tree' in the dense woods of a network visualisation. People often want to get to the detail of an instance of a relationship – the lines of text, images of the original document – from a graph.
This mightn't be how network visualisations are used in research, but it's something to consider for public-facing visualisations. How can we connect abstract lines or dots to detail, or provide more information about what the relationship means, show the quantification expressed as people highlight or filter parts of a graph? A harder, but more interesting task is hinting at the texture or detail of those relationships.
Proceed, with caution
One of the workshop questions was 'Are social network analysis theories and methods relevant for public-facing applications?' – and maybe the answer is a qualified yes. As a working tool, they're great for generating hypotheses, but they need a lot more care before exposing them to the public.
[As an aside, I’d always taken the difference between visualisations as working tools for exploring data – part of the process of investigating a research question – and visualisation as an output – a product of the process, designed for explanation rather than exploration – as fundamental, but maybe we need to make that distinction more explicit.]
But first – who are your 'users'?
During this workshop, at different points we may be talking about different 'users' – it's useful to scope who we mean at any given point. In this presentation, I was talking about end users who encounter visualisations, not scholars who may be organising and visualising networks for analysis.
Sometimes a network visualisationisn't the answer … even if it was part of the question.
As an outcome of an exploratory process, network visualisations are not necessarily the best way to present the final product. Be disciplined – make yourself justify the choice to use network visualisations.
No more untethered images
Include an extended caption – data source, tools and algorithms used. Provide a link to find out more – why this data, this form? What was interesting but not easily visualised? Let people download the dataset to explore themselves?
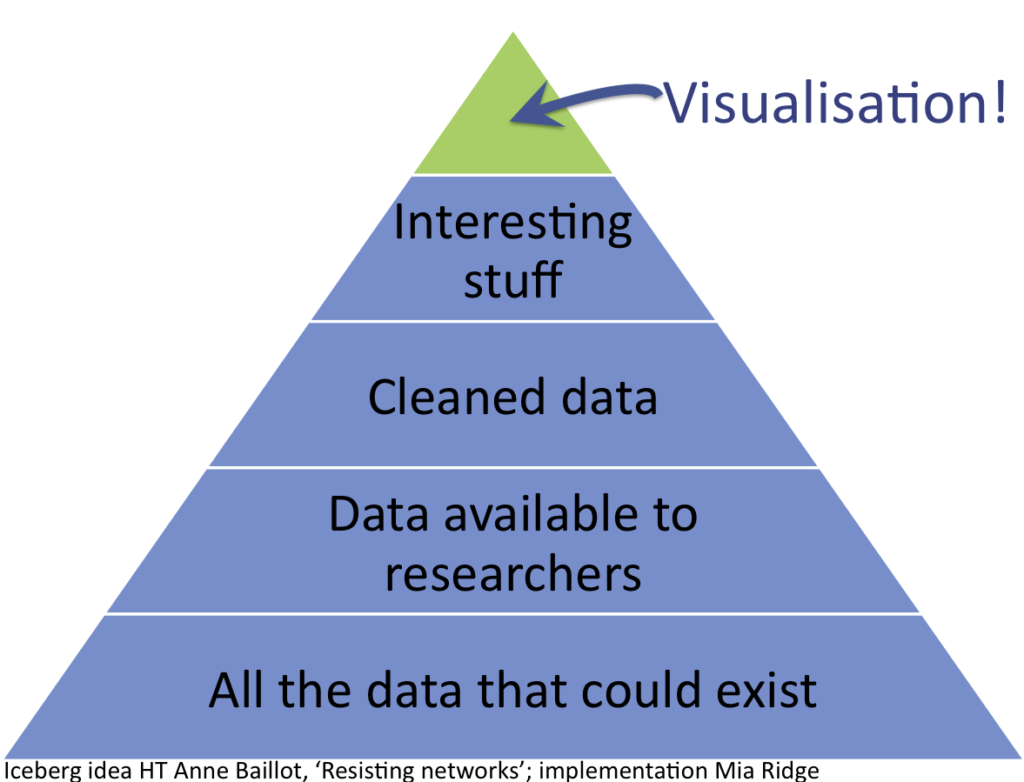
Present visualisations as the tip of the data iceberg
Visualisations are the tip of the iceberg
Lots of interesting data doesn't make it into a visualisation. Talking about what isn't included and why it was left out is important context.
Talk about data that couldn't exist
Beyond the (fuzzy, incomplete, messy) data that's left out because it's hard to visualise, data that never existed in the first place is also important:
'because we're only looking on one axis (letters), we get an inflated sense of the importance of spatial distance in early modern intellectual networks. Best friends never wrote to each other; they lived in the same city and drank in the same pubs; they could just meet on a sunny afternoon if they had anything important to say. Distant letters were important, but our networks obscure the equally important local scholarly communities.' Scott Weingart, 'Networks Demystified 8: When Networks are Inappropriate'
Help users learn the skills and knowledge they need to interpret network visualisations in context.
How? Good question! This is the point at which I hand over to you…
I came across Joshua Sternfeld's definition of 'digital historiography' while I was writing my thesis, and two parts of it very neatly described what I was up to – firstly, the 'interdisciplinary study of the interaction of digital technology with historical practice' – and secondly, seeking to understand the 'construction, use, and evaluation of digital historical representations'.[1]However, the size and shape of the gap between digital historiography and 'digital history' is where I tend to get stuck. I've got a draft post on the various types of 'digital history' that's never quite ready to go live.* Is digital history like art history – a field with its own theoretical concerns and objects of study – or will it eventually merge into 'history' as everyone starts integrating digital methods/tools and digitised sources into their work, in the same way that social or economic history have influenced other fields?
The real reason for me for talking about the digital humanities is that we need to realize the humanities never were the humanities. They are the print humanities and they are conditioned by print. So the question the term “digital humanities” poses is: How must humanities disciplines change if we are no longer working in a print world? This question, to me, is crucial. It is an intellectual question. And the question being proposed is: What happens to the humanities when digital methodologies are applied to them or when they start to interrogate digital methodologies? Both of these questions are crucial and that is what this term — “digital humanities” — keeps front and center.
* Partly because 'digital history' changes at a fairly constant rate and my thoughts shift correspondingly.
[1] Joshua Sternfeld, ‘Archival Theory and Digital Historiography: Selection, Search, and Metadata as Archival Processes for Assessing Historical Contextualization’, American Archivist 74, no. 2 (2011): 544–75, http://archivists.metapress.com/index/644851P6GMG432H0.pdf.
Another quick post with news on crowdsourcing in cultural heritage, citizen science and citizen history in April(ish) 2016…
Acceptances for our DH2016 Expert Workshop: Beyond The Basics: What Next For Crowdsourcing? have been sent out. If you missed the boat, don't panic! We're taking a few more applications on a rolling basis to allow for people with late travel approval for the DH2016 conference in July.
Probably the biggest news is the launch of citizenscience.gov, as it signals the importance of citizen science and crowdsourcing to the US government.
From the press release: 'the White House announced that the U.S. General Services Administration (GSA) has partnered with the Woodrow Wilson International Center for Scholars (WWICS), a Trust instrumentality of the U.S. Government, to launch CitizenScience.gov as the new hub for citizen science and crowdsourcing initiatives in the public sector.
CitizenScience.gov provides information, resources, and tools for government personnel and citizens actively engaged in or looking to participate in citizen science and crowdsourcing projects. … Citizen science and crowdsourcing are powerful approaches that engage the public and provide multiple benefits to the Federal government, volunteer participants, and society as a whole.'
There's also work to 'standardize data and metadata related to citizen science, allowing for greater information exchange and collaboration both within individual projects and across different projects'.
Other news:
Responses to questions about if the volunteers agreed that the Zooniverse… From Science Learning via Participation in Online Citizen Science
One of the questions at our SXSW panel was about crowdsourcing in teaching, which reminded me of this recent post on 'The War Department in the Classroom' in which Zayna Bizri 'describes her approach to using the Papers of the War Department in the classroom and offers suggestions for those who wish to do the same'. In related news, the PWD project is now five years old! There's also this post on Primary School Zooniverse Volunteers.
The Science Gossip project is one year old, and they're asking their contributors to decide which periodicals they'll work on next and to start new discussions about the documents and images they find interesting.
I've seen a few interesting studentships and jobs posted lately, hinting at research and projects to come. There's a funded PhD in HCI and online civic engagement and a (now closed) studentship on Co-creating Citizen Science for Innovation.
Apparently you can finish a thesis but you can't stop scanning for articles and blog posts on your topic. Sharing them here is a good way to shake the 'I should be doing something with this' feeling.* This is a fairly random sample of recent material, but if people find it useful I can go back and pull out other things I've collected.
Some of their key findings for museums (PDF) are below, interspersed with my comments. I read this section before the event, and found I didn't really recognise the picture of museums it presented. 'Museums' mightn't be the most useful grouping for a survey like this – the material that MTM London's Ed Corn presented on the day broke the results down differently, and that made more sense. The c2,500 museums in the UK are too varied in their collections (from dinosaurs to net art), their audiences, and their local and organisational context (from tiny village museums open one afternoon a week, to historic houses, to university museums, to city museums with exhibitions that were built in the 70s, to white cube art galleries, to giants like the British Museum and Tate) to be squished together in one category. Museums tend to be quite siloed, so I'd love to know who fills out the survey, and whether they ask the whole organisation to give them data beforehand.
According to the survey, museums are significantly less likely to engage in:
email marketing (67 per cent vs. 83 per cent for the sector as a whole) – museums are missing out! Email marketing is relatively cheap, and it's easy to write newsletters. It's also easy to ask people to sign up when they're visiting online sites or physical venues, and they can unsubscribe anytime they want to. Social media figures can look seductively huge, but Facebook is a frenemy for organisations as you never know how many people will actually see a post.
publish content to their own website (55 per cent vs. 72 per cent) – I wasn't sure how to interpret this – does this mean museums don't have their own websites? Or that they can't update them? Or is 'content' a confusing term? At the event it was said that 10% of orgs have no email marketing, website or Facebook, so there are clearly some big gaps to fill still.
sell event tickets online (31 per cent vs. 45 per cent) – fair enough, how many museums sell tickets to anything that really need to be booked in advance?
post video or audio content (31 per cent vs. 43 per cent) – for most museums, this would require an investment to create as many don't already have filmable material or archived films to hand. Concerns about 'polish' might also be holding some museums back – they could try periscoping tours or sharing low-fi videos created by front of house staff or educators. Like questions about offering 'online interactive tours of real-world spaces' and 'artistic projects', this might reflect initial assumptions based on ACE's experience with the performing arts. A question about image sharing would make more sense for museums. Similarly, the kinds of storytelling that blog posts allow can sometimes work particularly well for history and science museums (who don't have gorgeous images of art that tell their own story).
make use of social media video advertising (18 per cent vs. 32 per cent) – again, video is a more natural format for performing arts than for museums
use crowdfunding (8 per cent vs. 19 per cent) – crowdfunding requires a significant investment of time and is often limited to specific projects rather than core business expenses, so it might be seen as too risky, but is this why museums are less likely to try it?
livestream performances (2 per cent vs. 12 per cent) – again, this is less likely to apply to museums than performing arts organisations
One of the key messages in Ed Corn's talk was that organisations are experimenting less, evaluating the impact of digital work less, and not using data in digital decision making. They're also scaling back on non-core work; some are focusing on consolidation – fixing the basics like websites (and mobile-friendly sites). Barriers include lack of funding, lack of in-house time, lack of senior digital managers, slow/limited IT systems, and lack of digital supplier. (Many of those barriers were also listed in a small-scale survey on 'issues facing museum technologists' I ran in 2010.)
When you consider the impact of the cuts year on year since 2010, and that 'one in five regional museums at least part closed in 2015', some of those continued barriers are less surprising. At one point everyone I know still in museums seemed to be doing at least one job on top of theirs, as people left and weren't replaced. The cuts might have affected some departments more deeply than others – have many museums lost learning teams? I suspect we've also lost two generations of museum technologists – the retiring generation who first set up mainframe computers in basements, and the first generation of web-ish developers who moved on to other industries as conditions in the sector got more grim/good pay became more important. Fellow panelist Ros Lawler also made the point that museums have to deal with legacy systems while also trying to look at the future, and that museum projects tend to slow when they could be more agile.
Like many in the audience, I really wanted to know who the 'digital leaders' – the 10% of organisations who thought digital was important, did more digital activities and reaped the most benefits from their investment – were, and what made them so successful. What can other organisations learn from them?
It seems that we still need to find ways to share lessons learnt, and to help everyone in the arts and cultural sectors learn how to make the most of digital technologies and social media. Training that meets the right need at the right time is really hard to organise and fund, and there are already lots of pockets of expertise within organisations – we need to get people talking to each other more! As I said at the event, most technology projects are really about people. Front of house staff, social media staff, collections staff – everyone can contribute something.
If you were there, have read the report or explored the data, I'd love to know what you think. And I'll close with a blatant plug: the MCG has two open calls for papers a year, so please keep an eye out for those calls and suggest talks or volunteer to help out!


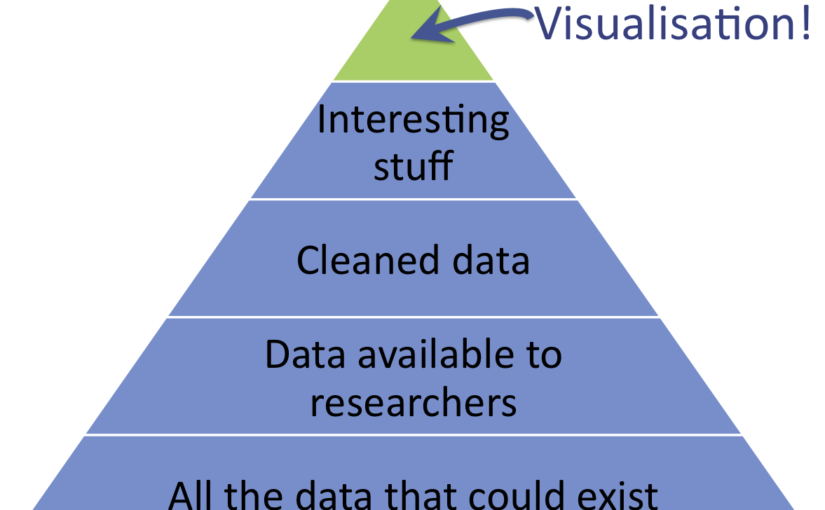
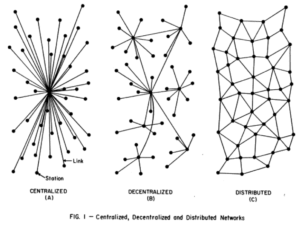 And this is a problem. We're not conveying what we're hoping to convey.
And this is a problem. We're not conveying what we're hoping to convey.





 Some of their key findings for museums (PDF) are below, interspersed with my comments. I read this section before the event, and found I didn't really recognise the picture of museums it presented. 'Museums' mightn't be the most useful grouping for a survey like this – the material that MTM London's Ed Corn presented on the day broke the results down differently, and that made more sense. The c2,500 museums in the UK are too varied in their collections (from dinosaurs to net art), their audiences, and their local and organisational context (from tiny village museums open one afternoon a week, to historic houses, to university museums, to city museums with exhibitions that were built in the 70s, to white cube art galleries, to giants like the British Museum and Tate) to be squished together in one category. Museums tend to be quite siloed, so I'd love to know who fills out the survey, and whether they ask the whole organisation to give them data beforehand.
Some of their key findings for museums (PDF) are below, interspersed with my comments. I read this section before the event, and found I didn't really recognise the picture of museums it presented. 'Museums' mightn't be the most useful grouping for a survey like this – the material that MTM London's Ed Corn presented on the day broke the results down differently, and that made more sense. The c2,500 museums in the UK are too varied in their collections (from dinosaurs to net art), their audiences, and their local and organisational context (from tiny village museums open one afternoon a week, to historic houses, to university museums, to city museums with exhibitions that were built in the 70s, to white cube art galleries, to giants like the British Museum and Tate) to be squished together in one category. Museums tend to be quite siloed, so I'd love to know who fills out the survey, and whether they ask the whole organisation to give them data beforehand.