Here are my notes from the Digital Humanities 2014 paper on 'Play as Process and Product' I did with Brian Croxall, Scott Kleinman and Amy Papaelias based on the work of the 2013 One Week One Tool team.
Here are my notes from the Digital Humanities 2014 paper on 'Play as Process and Product' I did with Brian Croxall, Scott Kleinman and Amy Papaelias based on the work of the 2013 One Week One Tool team.
Scott has blogged his notes about the first part of our talk, Brian's notes are posted as '“If hippos be the Dude of Love…”: Serendip-o-matic at Digital Humanities 2014' and you'll see Amy's work adding serendip-o-magic design to our slides throughout our three posts.
I'm Mia, I was dev/design team lead on Serendipomatic, and I'll be talking about how play shaped both what you see on the front end and the process of making it.
How did play shape the process?

How can a project based around boring things like APIs and panic be playful? Technical decision-making is usually a long, painful process in which we juggle many complex criteria. But here we had to practice 'rapid trust' in people, in languages/frameworks, in APIs, and this turned out to be a very freeing experience compared to everyday work.
First, two definitions as background for our work…
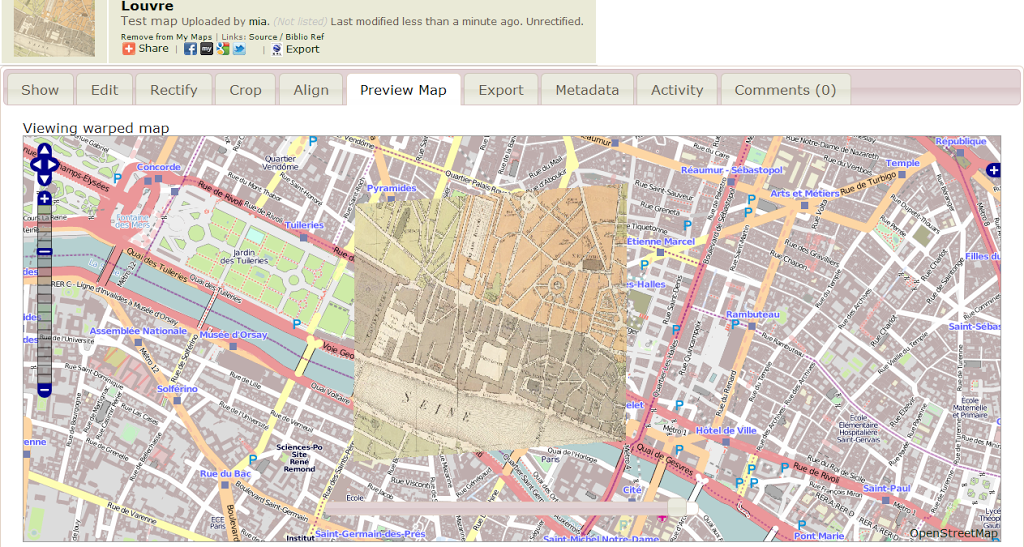
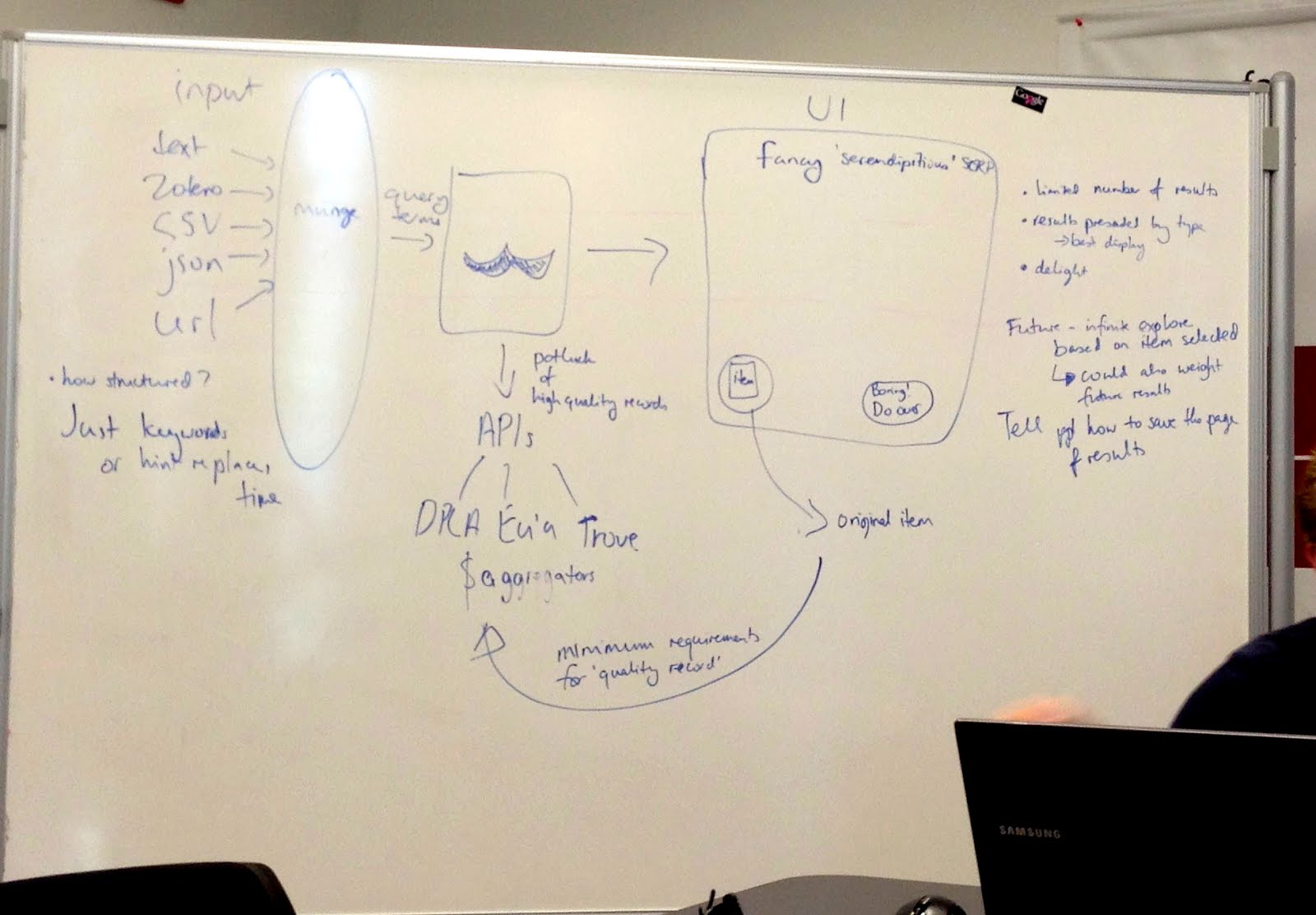
Just in case anyone here isn't familiar with APIs, APIs are a set of computational functions that machines use to talk to each other. Like the bank in Monopoly, they usually have quite specific functions, like taking requests and giving out information (or taking or giving money) in response to those requests. We used APIs from major cultural heritage repositories – we gave them specific questions like 'what objects do you have related to these keywords?' and they gave us back lists of related objects.
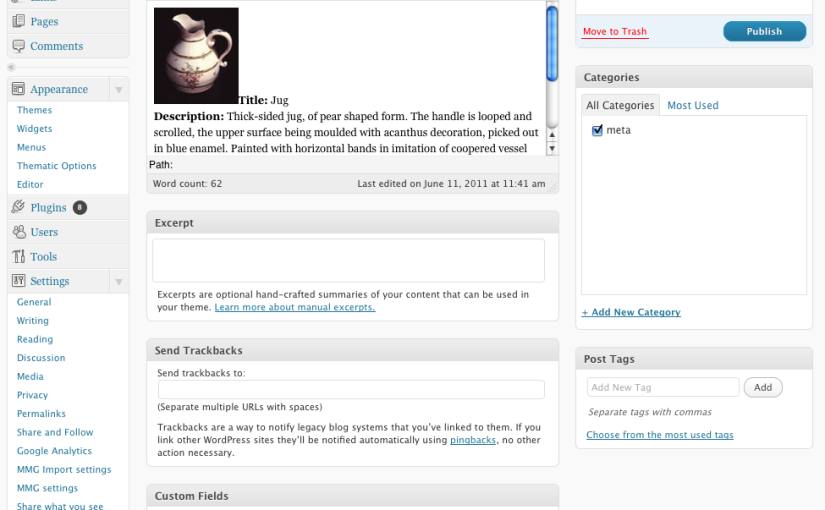
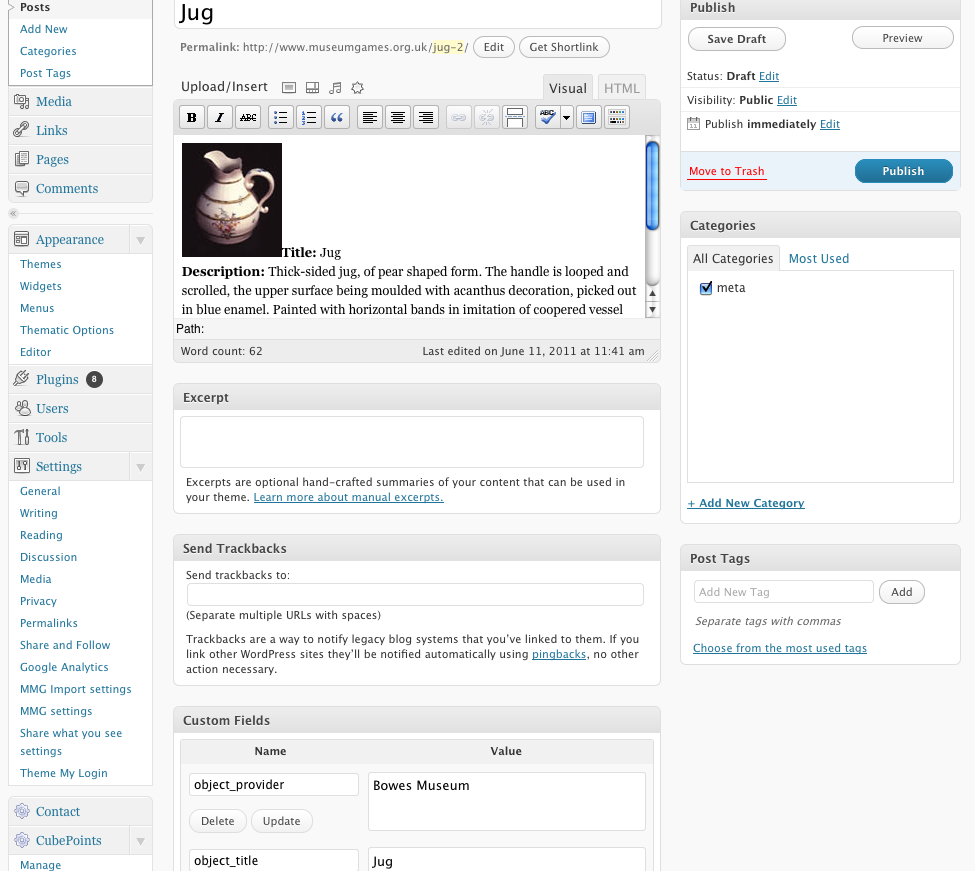
The term 'UX' is another piece of jargon. It stands for 'user experience design', which is the combination of graphical, interface and interaction design aimed at making products both easy and enjoyable to use. Here you see the beginnings of the graphic design being applied (by team member Amy) to the underlying UX related to the 1-2-3 step explanation for Serendipomatic.

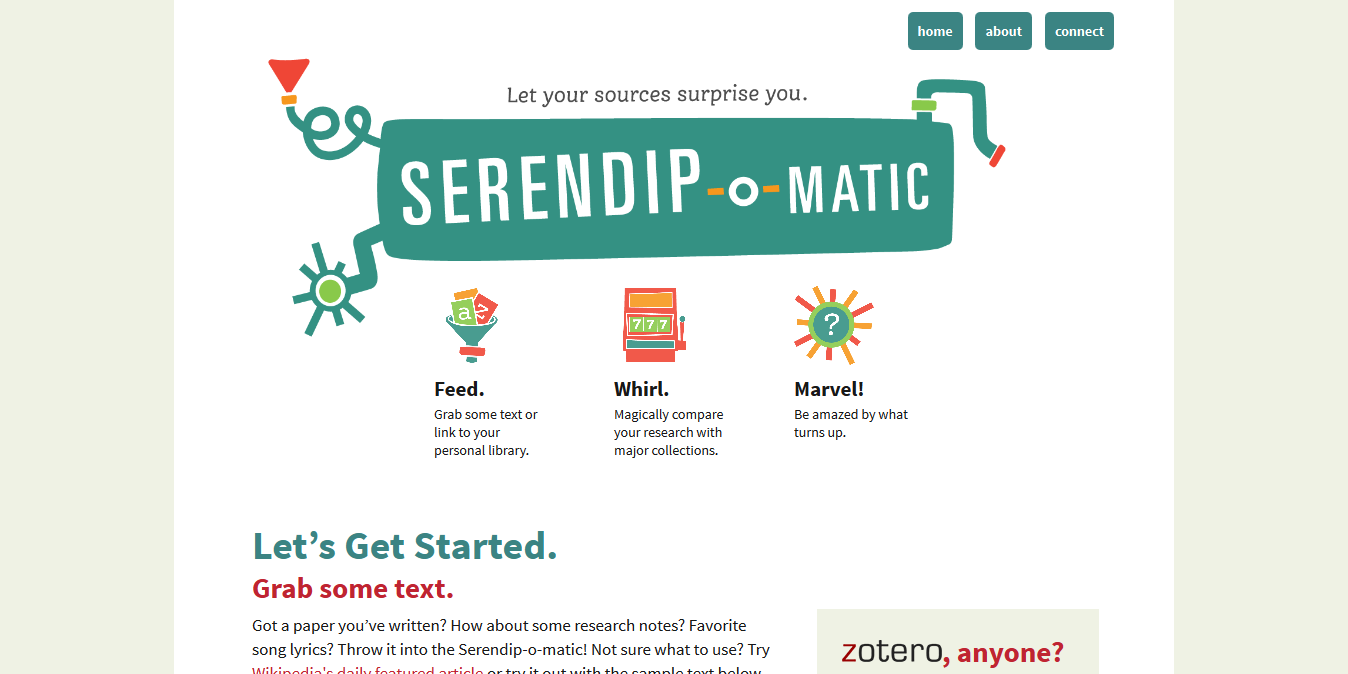
Feed.
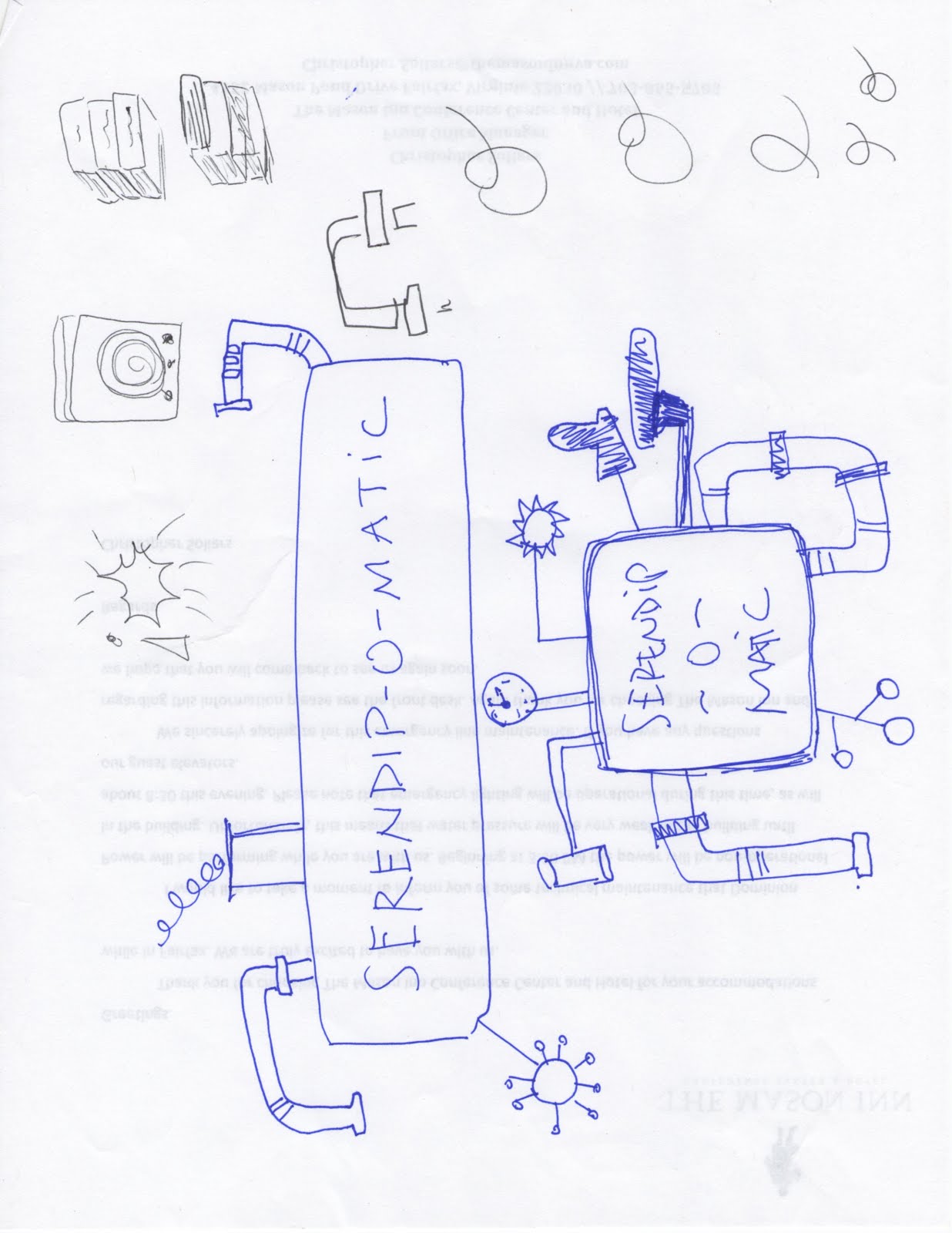
The 'feed' part of Serendipomatic parsed text given in the front page form into simple text 'tokens' and looked for recognisable entities like people, places or dates. There's nothing inherently playful in this except that we called the system that took in and transformed the text the 'magic moustache box', for reasons lost to time (and hysteria).

Whirl.
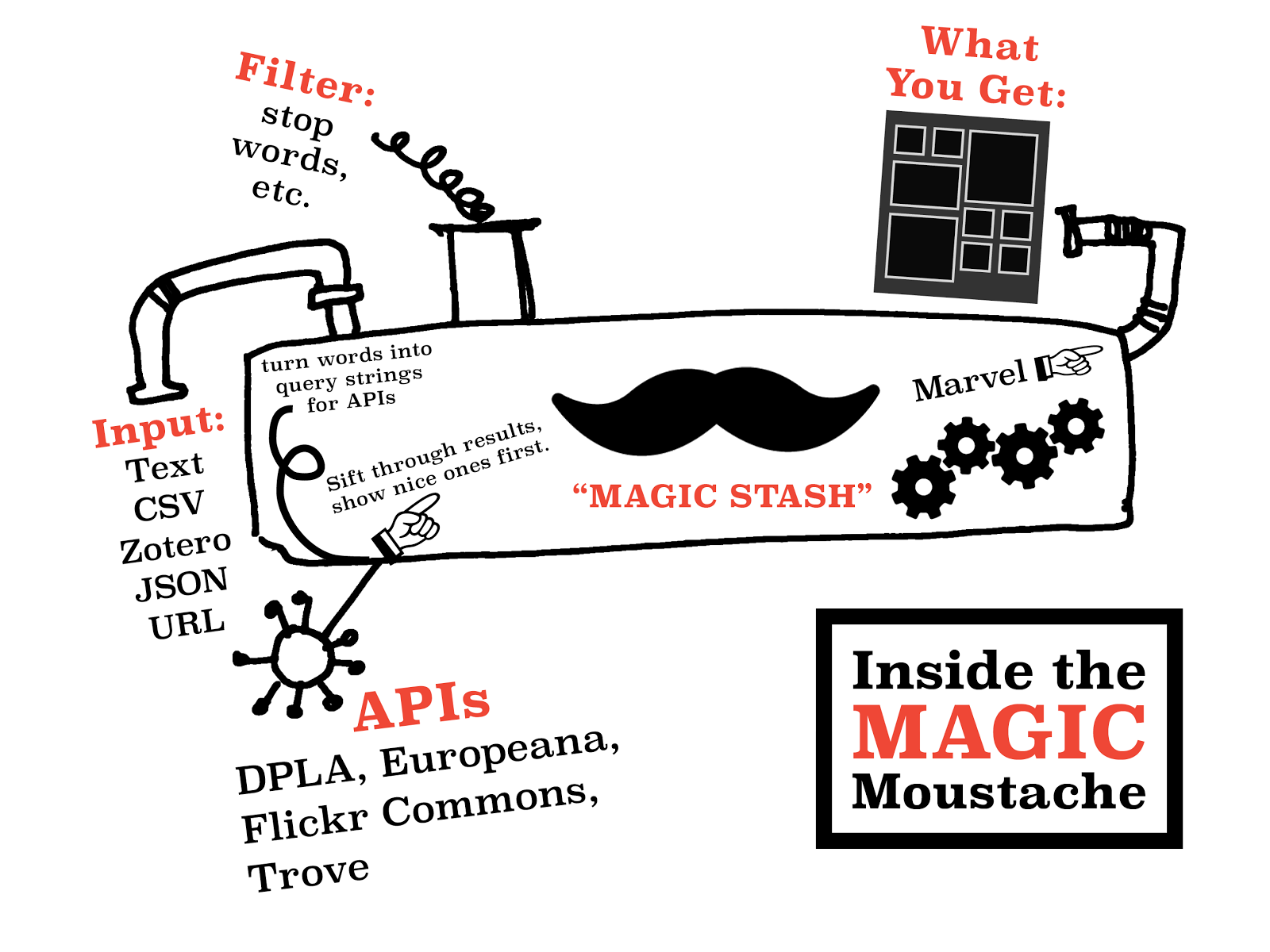
Marvel.
User-focused design was key to making something complicated feel playful. Amy's designs and the Outreach team work was a huge part of it, but UX also encompasses micro-copy (all the tiny bits of text on the page), interactions (what happened when you did anything on the site), plus loading screens, error messages, user documentation.
Without all this work on the graphic design – the look and feel that reflected the ethos of the product – the underlying playfulness would have been invisible. This user focus also meant removing internal references and in-jokes that could confuse people, so there are no references to the 'magic moustache machine'. Instead, 'Serendhippo' emerged as a character who guided the user through the site.
 But how does a magic moustache make a process playful?
But how does a magic moustache make a process playful?
This playfulness meant that writing code (in a new language, under pressure) could then be about making the machine more magic, not about ticking off functions on a specification document. The framing of the week as a challenge and as a learning experience allowed a lack of knowledge or the need to learn new skills to be a challenge, rather than a barrier. My role was to provide just enough structure to let the development team concentrate on the task at hand.
In a way, I performed the role of old-fashioned games master, defining the technical constraints and boundaries much as someone would police the rules of a game. Previous experience with cultural heritage APIs meant I was able to make decisions quickly rather than letting indecision or doubt become a barrier to progress. Just as games often reduce complex situations to smaller, simpler versions, reducing the complexity of problems created a game-like environment.
UX matters
Ultimately, a focus on the end user experience drove all the decisions about the backend functionality, the graphic design and micro-copy and how the site responded to the user.

It's easy to forget that every pixel, line of code or text is there either through positive decisions or decisions not consciously taken. User experience design processes usually involve lots of conversation, questions, analysis, more questions, but at OWOT we didn't have that time, so the trust we placed in each other to make good decisions and in the playful vision for Serendipomatic created space for us to focus on creating a good user experience. The whole team worked hard to make sure every aspect of the design helps people on the site understand our vision so they can get with exploring and enjoying Serendipomatic.
Some possible real-life lessons I didn't include in the paper
One Week One Tool was an artificial environment, but here are some thoughts on lessons that could be applied to other projects:
- Conversations trump specifications and showing trumps telling; use any means you can to make sure you're all talking about the same thing. Find ways to create a shared vision for your project, whether on mood boards, technical diagrams, user stories, imaginary product boxes.
- Find ways to remind yourself of the real users your product will delight and let empathy for them guide your decisions. It doesn't matter how much you love your content or project, you're only doing right by it if other people encounter it in ways that make sense to them so they can love it too (there's a lot of UXy work on 'on-boarding' out there to help with this). User-centred design means understanding where users are coming from, not designing based on popular opinion.you can use tools like customer journey maps to understand the whole cycle of people finding their way to and using your site (I guess I did this and various other UXy methods without articulating them at the time).
- Document decisions and take screenshots as you go so that you've got a history of your project – some of this can be done by archiving task lists and user stories.
- Having someone who really understands the types of audiences, tools and materials you're working with helps – if you can't get that on your team, find others to ask for feedback – they may be able to save you lots of time and pain.
- Design and UX resources really do make a difference, and it's even better if those skills are available throughout the agile development process.