I'm in Berlin for the International Council for Public History 20202 #IFPH2022 conference, where I'm on a panel on 'Revisiting A Shared Authority in the Age of Digital Public History'. It's part of a working group with Thomas Cauvin (Luxembourg), Michael Frisch (United States), Serge Noiret (Italy), Mark Tebeau (United States), Mia Ridge (United Kingdom), Sharon Leon (United States), Rebecca Wingo (United States), Dominique Santana (Luxembourg), Violeta Tsenova (Luxembourg). My panel notes will make more sense in that wider context, but I'm sharing them here for reference.
Shared authority as work in progress
What does 'shared authority' mean to cultural heritage institutions? (Or GLAMs – galleries, libraries, archives and museums). The view will really depend on many factors, possibly including whether GLAM staff feel the need to do any professional gatekeeping, reserving 'library' or 'archive' professional status for themselves, much as some historians do more gatekeeping than others around who's allowed to say they're 'doing history'.
Thinking about ephemerality and what’s left of the processes of sharing authority a few years after it happens…
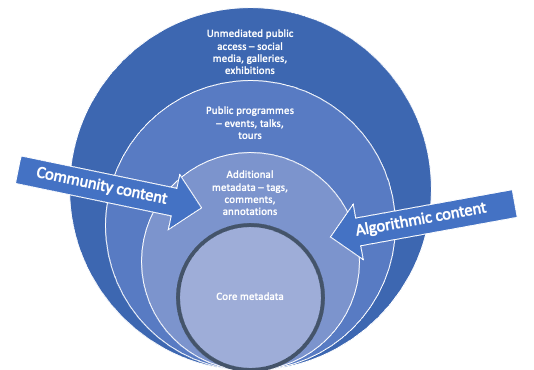
[Visual metaphor – think of the layers around the core of an onion. At the heart are collections, then catalogue metadata about those collections, often an additional layer of related metadata that doesn’t fit into the catalogue but is required for GLAM business, then public programmes including outreach and education, then there’s the unmediated access to collections and knowledge via social media and galleries]
I think GLAMs are getting comfortable with sharing, and shared authority. Crowdsourcing, in its many forms, is relatively common in GLAMs. Collaboration with Wikipedians of various sorts is widespread. There's a body of knowledge about co-curating exhibitions, community collecting and more, shared over conferences and publications and praxis. Texts and metadata and AV of all sorts have been created – usually *by* the public, *for* institutions.
Collaboration with other GLAMs on information standards and shared cataloguing has a long history, and those practices have moved online. [And now we’re sharing authority by putting records on wikidata, where they can be updated by anyone]
There's something interesting in the idea of the 'catalogue' as a source of authority. GLAM cataloguing practices are shaped by the needs of organisations – keeping track of their collections, adding information from structured vocabularies, perhaps adding extensive notes and bibliographies – for internal use and for their readers (particularly for libraries and archives), and by the commercial vendors that produce the cataloguing platforms.
Cataloguing platforms often lag behind the needs of GLAMs, and have been slow to respond to requests to include sources of information outside the organisation. That may be because some of this work in sharing authority happens outside cataloguing and registrar teams, or because there's not one single, clear way in which cataloguing systems should change to include information from the community about collection items.
Some GLAMs are more challenged than others by thinking generously about where 'authority' resides. Researchers in reading rooms, or open collection stores are clearly visibly engaged with specialist research. Their discussions with reference staff will often reveal the depths of their knowledge about specific parts of a collection. Authority is already shared between readers and staff. However, the expertise (or authority) of the same readers is not visible when they use online collections – all online visits and searches look the same in Google Analytics unless you really delve into the reports. Similarly, a crowdsourcing participant transcribing text or tagging images might be entirely new to the source materials, or have a deep familiarity with them. Their questions and comments might reveal something of this, but the data recorded by a crowdsourcing platform lacks the social cues that might be present in an in-person conversation.
In the UK, generations of funding cuts have reduced the number of specialist curators in GLAMs. These days, curators are more likely to be generalists, selected for their ability to speak eloquently about collections and grasp the shape, significance and history of a collection quickly. Looking externally for authoritative information – whether the lived experience of communities who used or still care for similar items, or specialist academic and other researchers – is common.
It's important to remember that 'crowdsourcing' is a broad term that includes 'type what you see' tasks such as transcription or correction, tasks such as free-text tagging or information that rely on knowledge and experience, and more involved co-creative tasks such as organising projects or analysing results. But an important part of my definition is that each task contributes towards a shared, significant goal – if data isn't recorded somewhere, it's just 'user generated content'.
For me, the value of crowdsourcing in cultural heritage is the intimate access it gives members of the public to collection items they would otherwise never encounter. As long as a project offers some way for participants to share things they've noticed, ask questions and mark items for their own use – in short, a way of reflecting on historical items – I consider that even 'simple' transcription tasks have the potential to be citizen history (or citizen science).
The questions participants ask on my projects shape my own practice, and influence the development of new tasks and features – and in the last year helped shape an exhibition I co-curated with another museum curator. The same exhibition featured 'community comments', responses from people I or the museum have worked with over some time. Some of these comments were reflections from crowdsourcing volunteers on how their participation in the project changed how they thought about mechanisations in the 1800s (the subject of the exhibition).
Attitudes have shifted; data hasn't
However, years after folksonomies and web 2.0 were big news, the data the public creates through crowdsourcing is still difficult to integrate with existing catalogues. Flickr Commons, Omeka, Wikidata, Zooniverse and other platforms might hold information that would make collections more discoverable online, but it’s not easy to link data from those platforms to internal systems. That is in part because GLAM catalogues struggle with the granularity of digitised items – catalogues can help you order a book or archive box to a reading room, but they can't as easily store tags or research notes about what's on a particular page of that item. It's also in part because data nearly always needs reviewing and transforming before ingest.
But is it also because GLAMs don't take shared authority seriously enough to advocate and pay for changes to their cataloguing systems to support them recording material from the public alongside internal data? Data that isn't in 'strategic' systems is more easily left behind when platforms migrate and staff move on.
This lack of flexibility in recording information from the public also plays out in ‘traditional’ volunteering, where spreadsheets and mini-databases might be used to supplement the main catalogue. The need for import and export processes to manage volunteer data can intentionally or unintentionally create a barrier to more closely integrating different sources of authoritative information.
So authority might be shared – but when it counts, whose information is regarded as vital, as 'core', and integrated into long-term systems, and whose is left out?
I realised that for me, at heart it’s about digital preservation. If it's not in an organisation’s digital preservation plans, or content is with an organisation that isn't supported in having a digital preservation plan; is it really valued? And if content isn't valued, is authority really shared?