This may be familiar to you if you've worked on a museum website: an object will capture the imagination of someone who starts to spread the link around, there's a flurry of tweets and tumblrs and links (that hopefully you'll notice in time because you've previously set up alerts for keywords or URLs on various media), others like it too and it starts to go viral and 50,000 people look at that one page in a day, 20,000 the next, furious discussions break out on social media and other sites… then they're gone, onto the next random link on someone else's site. It's hugely exciting, but it can also feel like a missed opportunity to show these visitors other cool things you have in your collection, to address some of the issues raised and to give them more information about the object.
There are three key aspects to riding these waves of interest: the ability to spot content that's suddenly getting a lot of hits; the ability to respond with interesting, relevant content while the link is still hot (i.e. within anything from a couple of hours to a couple of days); and the ability to put that relevant content on the page where fly-by-night visitors will see it.
For many museums, caught between a templated CMS and layers of sign-off for new content , it's not as easy as it sounds. When the Science Museum's 'steampunk artificial arm' started circulating on twitter and then made boingboing, I was able to work with curators to get a post on the collections blog about it the next day, but then there was no way of adding that link to the Brought to Life page that was all most people saw.
In his post on “The Guardian’s Facebook app”, Martin Belam discusses how their Facebook app has helped archived content live again:
Someone shares an old article with their friends, some of their friends either already use or install the app, and the viral effect begins to take hold. … We’ve got over 1.3 million articles live on the website, so that is a lot of content to be discovered, and the app means that suddenly any page, languishing unloved in our database, can become a new landing page. When an article becomes popular in the app, we sometimes package it with content. Because we know the attention has come at a specific time from a specific place, we can add related links that are appropriate to the audience rather than to the original content. …when you’ve got the audience there, you need to optimise for them
As a content company with great technical and user experience teams, the Guardian is better placed to put together existing content around a viral article, but still, I'm curious: are any museums currently managing to respond to sudden waves of interest in random objects? And if so, how?
I originally posted this on the Science Museum API documentation wiki.
About this data
These data sets contain information about objects from the collections of the Science Museum, the National Media Museum and the National Railway Museum. These datasets include many items not on display in our galleries, as well as authority records about related people and organisations, events and image files.
The collections include objects relating to aeronautics, agriculture, astronomy, cinematography, medicine, materials, space, television, time measurement, transport and more. They range in size from contact lenses to Concorde 002.
We hope to publish our lists of c9000 people and organisations related to these objects soon, alongside a table linking objects to events.
The data is supplied in CSV (comma-separated format, exported from Excel). The first line of each file contains the field headings. Files may be up to 15mb in size.
The data is released under the Creative Commons Attribution-NonCommercial-ShareAlike (CC BY-NC-SA) licence (http://creativecommons.org/licenses/by-nc-sa/3.0/). Please contact us if you would like to use this data under different conditions.
Why we're releasing the data
We have been providing access to a searchable database of our collections online at http://collectionsonline.nmsi.ac.uk/ for some time now, but through staff attendance at various hack days, we've learned that this interface does not support programmatic search or exploration of the data. We've also learned (through the Cosmos & Culture project) that a number of people found the XML provided by the default .Net service that published the API too complex. CSV is a very simple format, accessible to a wider range of people. We hope that it will be usable by most people.
We're publishing the data in CSV format now as a relatively lightweight experiment. We'd like to understand whether, and if so, how, people would use our data. We'd also like to explore the benefits for the museum and for programmers using our data – your feedback would inform decisions about future investment in more structured data as well as helping shape our understanding of the requirements of those users.
We hope you will be creative with it, but please use it responsibly. If you're not sure whether the museum would be comfortable with your idea, please drop us a line to discuss it.
How you can help
You can help us to improve this resource – let us know if you have any information about our objects, or if you find any errors, though we will probably not republish this data set in the short-term. Please quote the Object Number/s and email: Collections.Online@nmsi.ac.uk
We'd like this experiment to help us understand the needs of potential users but we can only do that with your help – we'd love to hear your comments on how you've used the data, and how we could improve it. If possible, we'd like to feature mashups or other applications made with our data. Please email us at web.team@nmsi.ac.uk, send @sciencemuseum a message on twitter or leave a comment at http://sciencemuseumdiscovery.com/blogs/museumdev.
The unique identifier for a record, based on the museum's own accession number. The number may refer to a single object or (historically) to a collection of objects.
ITEM_NAME
Object name – a simple name or common name. Where possible this is from an established thesaurus (i.e. http://museum-api.pbworks.com/f/NMSI_draft200903_object_name.csv)
TITLE
A short one-line caption or brief description of the object, derived from the existing data. The title should be a summary capturing the essence of an object. Often includes related place and date.
MAKER
The name of the person or company or other organisation that made the object. The Maker field is indexed and linked to the People/Organisation records (to be released shortly) – links should be made by matching strings (internal IDs are not available).
DATE_MADE
The date when an object was made (production date). Dates should be recorded consistently and ranges should be in the format <earlier year>-<later year> e.g. 1671-1700. Approximate dates are written as e.g. c. 1936. This field also contains various strings, including ‘Unknown'.
PLACE_MADE
Place names are indexed in the database and linked into a hierarchy (Getty Thesaurus of Geographic Names with in-house modifications i.e. http://museum-api.pbworks.com/f/NMSI_draft200903_place.csv) and should be recorded consistently because they are derived from a term list. Where known with certainty or reasonable probability the town or city of production is recorded. As a minimum the nation/country of origin or the probable nation/country of production should be recorded. If there is some uncertainty this can be explained in the general description.
MATERIALS
Records what the object is made of and what part of the object is made of that material.
MEASUREMENTS
Record the type of measurements that are most useful for an object, with ‘overall' being the most usual dimensions recorded. Overall will be the amount of space the object takes up when it first arrives in the museum and is stored. Measurements must be recorded consistently in metric units. Compulsory measurements are Size and Weight. The default units of measurement are millimetres and kilograms. Example: overall: 51 mm x 95 mm x 80 mm, 0.371kg,
DESCRIPTION
In this field we try to describe what the what, when, why, where, who information about the object, what it is, what it does, is made of, who made it, where was it made and what makes it unique. This field should be exported as plain text (without markup). The information here is used by the museum to audit an object so it should be described well with each part defined. It should also contain all the information about the object so that an interpreted description can be written (suitable for publication). Technical terms have been avoided as far as possible. Names, dates, places and significant events should be recorded here in a normalized form but will also be recorded in other indexed fields. As far as possible the following are recorded: <number of objects> <name of object, qualifier> <model name, number> <what is the type of object?> <specific information>:<made by…> <type of object> <place made> <date made> <any associated relevant fact> <materials> <colour><serial number><containers> <accessories> <dimensions> <condition and completeness> <identification of parts> <acquisition/provenance information> <story of display, conservation etc.> <other details>
WHOLE_PART
Mostly an internal field.
COLLECTION
A broad subject specialism applied during the Acquisition/ Entry process. NMeM National Media Museum NRM National Railway Museum SCM Science Museum. Collection terms are listed at http://museum-api.pbworks.com/w/page/36515349/NMSI-Collections-list
For more information on authority records, see http://en.wikipedia.org/wiki/Authority_control
You can use it to construct URLs to images of the objects. (The images are hosted on a site built with a third-party solution so the URLs aren't ideal.)
objects.ID_NUMBER is the equivalent to media. OBJECT, giving you a link between the object and media tables (e.g. 1999-719). The media. MEDIAKEY (e.g. 125972) can then be included in a URL, e.g. the image file URL uses the media key: http://collectionsonline.nmsi.ac.uk/grabimg.php?wm=1&kv=125972
Column title
What is it?
MEDIA_ID
e.g. 10327065.jpg
OBJECT
The object ID_NUMBER e.g. 1999-719
MEDIAKEY
e.g. 125972
CAPTION
Optional. E.g. ‘Class 84 locomotive at Barrow Hill, sanding and filling in progress, August 1984'
Currently this data set has fairly random coverage but we would be interested to see whether people find the content useful. If the object was linked to any significant event (historical, political, developmental or other milestone events) or if an object featured at some significant and well-known event or activity, it might be recorded in this table.
Column title
What is it?
Event Name
Includes location and date/date range.
Event Short Name
Event title without location or date (usually)
Event Category
Values include era, war, exhibition, expedition (term list?)
Occurrence Type
E.g. one-time, periodic, annual. Optional
Event Start Date
Single date as year or y/m/d. Mixed formats (sorry!). Also includes BCE dates expressed as negative integers e.g. -3100 Optional
Event End Date
As for Event Start Date. Optional
Display Date
?
Duration
Integer – use with Duration Unit. Optional
Duration Unit
E.g. days, months, years. Use with Duration. Optional
Event Description
Text. Optional
Description Source(s)
May be a URL. Optional
Sort Name
Internal use version of event name
Produced for the Science Museum, London. Last updated by Mia Ridge, March 2011. With thanks to the web, database and documentation teams at NMSI for their support and assistance. Thanks also to @rboulton for testing the documentation.
I originally posted this on the Science Museum API wiki. This version dates to March 2011, as I documented things before leaving to do a PhD.
Documentation for collections data from Science Museum, National Media Museum, National Railway Museum (NMSI) released as CSV
About this data
These data sets contain information about objects from the collections of the Science Museum, the National Media Museum and the National Railway Museum. These datasets include many items not on display in our galleries, as well as authority records about related people and organisations, events and image files.
The collections include objects relating to aeronautics, agriculture, astronomy, cinematography, medicine, materials, space, television, time measurement, transport and more. They range in size from contact lenses to Concorde 002.
We hope to publish our lists of c9000 people and organisations related to these objects soon, alongside a table linking objects to events.
The data is supplied in CSV (comma-separated format, exported from Excel). The first line of each file contains the field headings. Files may be up to 15mb in size.
The data is released under the Creative Commons Attribution-NonCommercial-ShareAlike (CC BY-NC-SA) licence (http://creativecommons.org/licenses/by-nc-sa/3.0/). Please contact us if you would like to use this data under different conditions.
Why we're releasing the data
We have been providing access to a searchable database of our collections online at http://collectionsonline.nmsi.ac.uk/ for some time now, but through staff attendance at various hack days, we've learned that this interface does not support programmatic search or exploration of the data. We've also learned (through the Cosmos & Culture project) that a number of people found the XML provided by the default .Net service that published the API too complex. CSV is a very simple format, accessible to a wider range of people. We hope that it will be usable by most people.
We're publishing the data in CSV format now as a relatively lightweight experiment. We'd like to understand whether, and if so, how, people would use our data. We'd also like to explore the benefits for the museum and for programmers using our data – your feedback would inform decisions about future investment in more structured data as well as helping shape our understanding of the requirements of those users.
We hope you will be creative with it, but please use it responsibly. If you're not sure whether the museum would be comfortable with your idea, please drop us a line to discuss it.
How you can help
You can help us to improve this resource – let us know if you have any information about our objects, or if you find any errors, though we will probably not republish this data set in the short-term. Please quote the Object Number/s and email: Collections.Online@nmsi.ac.uk
We'd like this experiment to help us understand the needs of potential users but we can only do that with your help – we'd love to hear your comments on how you've used the data, and how we could improve it. If possible, we'd like to feature mashups or other applications made with our data. Please email us at web.team@nmsi.ac.uk, send @sciencemuseum a message on twitter or leave a comment at http://sciencemuseumdiscovery.com/blogs/museumdev.
The unique identifier for a record, based on the museum's own accession number. The number may refer to a single object or (historically) to a collection of objects.
ITEM_NAME
Object name – a simple name or common name. Where possible this is from an established thesaurus (i.e. http://museum-api.pbworks.com/f/NMSI_draft200903_object_name.csv)
TITLE
A short one-line caption or brief description of the object, derived from the existing data. The title should be a summary capturing the essence of an object. Often includes related place and date.
MAKER
The name of the person or company or other organisation that made the object. The Maker field is indexed and linked to the People/Organisation records (to be released shortly) – links should be made by matching strings (internal IDs are not available).
DATE_MADE
The date when an object was made (production date). Dates should be recorded consistently and ranges should be in the format <earlier year>-<later year> e.g. 1671-1700. Approximate dates are written as e.g. c. 1936. This field also contains various strings, including ‘Unknown'.
PLACE_MADE
Place names are indexed in the database and linked into a hierarchy (Getty Thesaurus of Geographic Names with in-house modifications i.e. http://museum-api.pbworks.com/f/NMSI_draft200903_place.csv) and should be recorded consistently because they are derived from a term list. Where known with certainty or reasonable probability the town or city of production is recorded. As a minimum the nation/country of origin or the probable nation/country of production should be recorded. If there is some uncertainty this can be explained in the general description.
MATERIALS
Records what the object is made of and what part of the object is made of that material.
MEASUREMENTS
Record the type of measurements that are most useful for an object, with ‘overall' being the most usual dimensions recorded. Overall will be the amount of space the object takes up when it first arrives in the museum and is stored. Measurements must be recorded consistently in metric units. Compulsory measurements are Size and Weight. The default units of measurement are millimetres and kilograms. Example: overall: 51 mm x 95 mm x 80 mm, 0.371kg,
DESCRIPTION
In this field we try to describe what the what, when, why, where, who information about the object, what it is, what it does, is made of, who made it, where was it made and what makes it unique. This field should be exported as plain text (without markup). The information here is used by the museum to audit an object so it should be described well with each part defined. It should also contain all the information about the object so that an interpreted description can be written (suitable for publication). Technical terms have been avoided as far as possible. Names, dates, places and significant events should be recorded here in a normalized form but will also be recorded in other indexed fields. As far as possible the following are recorded: <number of objects> <name of object, qualifier> <model name, number> <what is the type of object?> <specific information>:<made by…> <type of object> <place made> <date made> <any associated relevant fact> <materials> <colour><serial number><containers> <accessories> <dimensions> <condition and completeness> <identification of parts> <acquisition/provenance information> <story of display, conservation etc.> <other details>
WHOLE_PART
Mostly an internal field.
COLLECTION
A broad subject specialism applied during the Acquisition/ Entry process. NMeM National Media Museum NRM National Railway Museum SCM Science Museum. Collection terms are listed at http://museum-api.pbworks.com/w/page/36515349/NMSI-Collections-list
For more information on authority records, see http://en.wikipedia.org/wiki/Authority_control
You can use it to construct URLs to images of the objects. (The images are hosted on a site built with a third-party solution so the URLs aren't ideal.)
objects.ID_NUMBER is the equivalent to media. OBJECT, giving you a link between the object and media tables (e.g. 1999-719). The media. MEDIAKEY (e.g. 125972) can then be included in a URL, e.g. the image file URL uses the media key: http://collectionsonline.nmsi.ac.uk/grabimg.php?wm=1&kv=125972
Column title
What is it?
MEDIA_ID
e.g. 10327065.jpg
OBJECT
The object ID_NUMBER e.g. 1999-719
MEDIAKEY
e.g. 125972
CAPTION
Optional. E.g. ‘Class 84 locomotive at Barrow Hill, sanding and filling in progress, August 1984'
Currently this data set has fairly random coverage but we would be interested to see whether people find the content useful. If the object was linked to any significant event (historical, political, developmental or other milestone events) or if an object featured at some significant and well-known event or activity, it might be recorded in this table.
Column title
What is it?
Event Name
Includes location and date/date range.
Event Short Name
Event title without location or date (usually)
Event Category
Values include era, war, exhibition, expedition (term list?)
Occurrence Type
E.g. one-time, periodic, annual. Optional
Event Start Date
Single date as year or y/m/d. Mixed formats (sorry!). Also includes BCE dates expressed as negative integers e.g. -3100 Optional
Event End Date
As for Event Start Date. Optional
Display Date
?
Duration
Integer – use with Duration Unit. Optional
Duration Unit
E.g. days, months, years. Use with Duration. Optional
Event Description
Text. Optional
Description Source(s)
May be a URL. Optional
Sort Name
Internal use version of event name
Produced for the Science Museum, London. Last updated by Mia Ridge, March 2011. With thanks to the web, database and documentation teams at NMSI for their support and assistance. Thanks also to @rboulton for testing the documentation.
I originally posted this on the Science Museum API wiki in 2008, this version dates from about March 2011 (when I left the Science Museum Group to start a PhD).
I thought I’d have a quick play with the data last night, and so managed to import them into a database and built a quick web app called ‘Things’: http://what-is-this.heroku.com/
The main thing I wanted out of the data was to be able to browse by type-of-thing (eg ‘steam engines’). Given that this information isn’t easily accessible from the existing data, the first thing that ‘Things’ does is ask people to help classify the objects.
It’s sort of like tagging. But easier. :-)
If I get enough things classified I may have a go at seeing if an algorithm can learn from the data and classify the rest.
Given the number of crowdsourcing projects around*, the next step for the museum may be working out how to manage and make the most of user-created data we get back from projects like this. This would be an excellent problem to have.
* I’ve also got lots of data to handover based on tags and facts added by people playing with the astronomy collections on Museum Metadata Games, which was again only possible because the Powerhouse Museum has an API and the Science Museum made an earlier, XML-based API.
A few people have commented on the licence (Creative Commons Attribution-NonCommercial-ShareAlike, CC BY-NC-SA) and on the format (CSV). As tomorrow is my last day, I can’t really speak for the museum but the intention is to learn from how people use the data – the things they make, the barriers they face, etc – and iterate (as resources allow) until we get to an optimal solution (or solutions). So please get in touch if you’ve got requests or think you can help clear up some of the issues these kinds of projects face, because there’s a good chance you’ll help make a difference.
The licence is a pragmatic solution – it’s clarification of existing terms rather than a change to our terms, because this avoided a need for legal advice, policy review, etc, that would have added several months to the process.
And yes, I know CSV is quick and dirty, but it’s effective. The museum sector is still working out how to match the resources available with the needs of mash-up type developers who work best with JSON and those who are aiming for linked open data; my hope is that your feedback on this will help museums figure out how to support people using open data in various forms. A simple solution like this also means it’s easy for the museum to re-run the export to update the data as time goes on, and that anyone, geek or not, can open the files without being startled by angle brackets and acronyms. Also, did I mention it was quick?
I converted the source CSV to XML using my CSV Converter program, which is a home-made program I wrote to do a “mail-merge” on CSV data, with the aim of easily generating other formats such as XML.
The geocoding was carried out by calls to my place URL-ifier program. This uses the standard Geonames query API, but splits a place description into its component place names (e.g. “Swindon, Wiltshire, England” becomes three place names) and searches for a “Swindon” contained within places “Wiltshire” and “England”.
I wrote an XSLT transform which copied the source document, and each time it found a place field, it called out to my URL-ifier using the document() function:
Where this was successful in inferring a Geonames identifier, it added a “geonamesId” attribute to the PLACE_MADE field. So the result is a copy of the source data, with added geocoding.
All of the NRM data was geocoded in a single XSLT operation, but this operation had to call my URL-ifier, and hence the Geonames API, many times. There are limits on how hard you can hit this service, so care needs to be exercised! (You can get your own Geonames identifier for free, and then have your own allocation of API calls, if you want to use this service in a serious way.)
Now that the data contains Geonames URLs, you have access to all the background information about each place. All Geonames entries have lat/long co-ordinates (which is what you need to stick a pin on a map in your browser, using e.g. KML markup), but in addition will often have info such as population. You just need to make an HTTP request for the Geonames URL, specifying that you want RDF back, e.g.: http://light.demon.co.uk/scripts/cgiforwarder.exe?url=http://sws.geonames.org/2633352/&accept=rdf and process the RDF/XML which comes back.
Personally, this kind of thing makes it all worthwhile – we can’t easy export our entire geographical hierarchy, so being able to geocode the imperfect data we have is really useful.
If you’ve done something interesting with our data we’d love to feature it. We’re also curious to know who’s having a look at it, even if you’re not at the point of having something to share.
Finally, I’d almost forgotten to thank the many wonderful people who’d contributed to the Museums and the machine-processable web site or come along to #linkingmuseums meetups to work out how to get to re-usable museum data. I’ll be keeping up the wiki in future, and can be contacted @mia_out.
I’m very excited about sharing this with you – we’ve just released 218,822 records about objects from the collections of the Science Museum, the National Media Museum and the National Railway Museum.
The collections include objects relating to aeronautics, agriculture, astronomy, cinematography, medicine, materials, space, television, time measurement, transport and more. They range in size from contact lenses to Concorde 002.
We’ve released the files as a lightweight experiment – we’d like to understand whether, and if so, how, people would use our data. We’d also like to explore the benefits for the museum and for programmers using our data – your feedback will inform decisions about future investment in more structured data as well as helping shape our understanding of the requirements of those users. The files are in CSV format – because it’s a really simple format, viewable in a text editor, we hope that it will be usable by most people.
[Update: I'm working on a shorter version with fewer long words. Something like crowdsourcing geolocated historial materials/artefacts with specialist users/academic contributors/citizen historians.]
A few people have asked me about my PhD* topic, and while I was going to wait until I'd started and had a chance to review it in light of the things I'm already starting to learn about what else is going on in the field, I figured I should take advantage of having some pre-written material to cover the gap in blogging while I try to finish various things (like, um, my MSc dissertation) that were hijacked by a broken wrist. So, to keep you entertained in the meantime, here it is.
Please bear in mind that it's already out-of-date in terms of my thinking and sense of what's already happening in the field – I'm really looking forward to diving into it but my plan to spend some time thinking about the project before I started has been derailed by what felt like a year of having an arm in a cast.
* I never got around to posting about this because my disastrous slip on the ice happened just two days after I resigned, but I'm leaving my job at the Science Museum to take up the offer of a full-time PhD in Digital Humanities at the Open University in mid-March.
Provisional title: Participatory digitisation of spatially indexed historical data
This project aims to investigate 'participatory digitisation' models for geo-located historical material.
This project begins with the assumption that researchers are already digitising and geo-locating materials and asks whether it is possible to create systems to capture and share this data. Could the digital records and knowledge generated when researchers access primary materials be captured at the point of creation and published for future re-use? Could the links between materials, and between materials and locations, created when researchers use aggregated or mass-digitised resources, be 'mined' for re-use?
Through the use of a case study based around discovering, collating, transforming and publishing geo-located resources related to early scientific women, the project aims to discover:
how geo-located materials are currently used and understood by researchers,
what types of tools can be designed to encourage researchers to share records digitised for their own personal use
whether tools can be designed to allow non-geospatial specialists to accurately record and discover geo-spatial references
the viability of using online geo-coding and text mining services on existing digitised resources
Possible outcomes include an evaluation of spatially-oriented approaches to digital heritage resource discovery and use; mental models of geographical concepts in relation to different types of historical material and research methods; contributions to research on crowdsourcing digital heritage resources (particularly the tensions between competition and co-operation, between the urge to hoard or share resources) and prototype interfaces or applications based on the case study.
The project also provides opportunities to reflect on what it means to generate as well as consume digital data in the course of research, and on the changes digital opportunities have created for the arts and humanities researcher.
** This case study is informed by my thinking around the possibilities of re-populating the landscape with references to the lives, events, objects, etc, held by museums and other cultural heritage institutions, e.g. outside museum walls and by an experimental, collaborative project around 'modern bluestockings', that aimed to locate and re-display the forgotten stories around unconventional and pioneering women in science, technology and academia.
I’m particularly interested in finding the balance between a solution we can achieve in the medium-term and something that works with standards as much as possible.
It’s nearly time for the Museums and the Web 2010 conference, where questions like this might be addressed in one of the unconference sessions so I’d love to hear your thoughts.
This is very much a work in progress, and in fact I suspect it's not even the latest version, but hopefully at least it's more useful up here than on my hard drive, even in a very draft-ish state.
February, 2010.
This is a thoughts-in-development piece on how the Science Museum/NMSI could provide re-usable, interoperable, structured machine-readable data for use as linked data or APIs.
I'm including here things that we generally have enough information about for it to make sense for us to link them. I'll talk about ways to link to the rest of the world below.
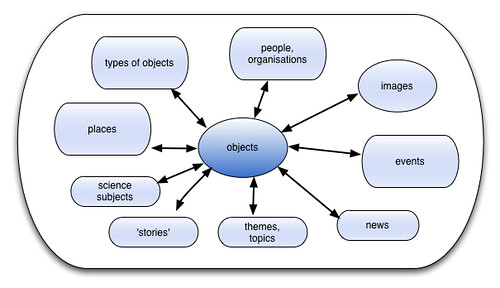
Objects – we have lots of these. Yay! Each record is about a specific accessioned object. As you can see from the diagram above, objects can be related to everything else (and to each other, in various ways). An object might be as big and iconic as Robert Stephenson's Rocket or as small as a spark plug.
Types of objects – a more generic view. It allows us to solve two problems – our collections don't cover everything we want to talk about, and we have lots and lots of certain types of objects. So a page on spark plugs is a user-friendly layer of content about spark plugs for general readers and provides links to all 8000 spark plugs in the collection (I totally made that number up).
It lets us discuss topics that our collections don't cover comprehensively, and to create a user-friendly layer between the detail of our collection (8000 spark plugs) and general information about spark plugs.
[If you're not familiar with museum collections – coverage varies according to what was collectable or collected – our collections may represent fashions in history of collecting more than an ideal uber-collection. Unlike, say, an art gallery, not every single item in our collection is a precious and unique diamond – for the general user, it might be enough to know what we have some information about dental forceps and a picture of one – but for the specialist researcher, browsing our collection of 300 of them might be the highlight of their week. (Maybe).]
Places – in our collections databases, we can look at the place an object was made, used, designed, destroyed, collected, restored, redesigned, invented, etc, etc. People and events also have various possible relationships to places.
People/organisations – ideally, we'd like to Wikipedia for every person and place, but not everyone we refer to in our collections has Wikipedia notability.
Images – we also have lots of related images, which are a major asset but work better in relation to other things (like objects) than as concepts on their own.
Other hooks in our content include dates and materials – these might be particularly useful for facetted browsing or mashups made with our data, but don't particularly make sense as concepts on their own. We also produce contemporary science news through our (re-opening in June) Antenna gallery, and marking this up with hNews seems a no-brainer. Working out how to link to the original news stories, whether in Nature, the BBC, whatever, would be good – something we can build into the publishing platform (WordPress MU) to make it nice and easy for our content authors would be even better.
Linking concepts and microsites, creating a canonical object home
I'm proposing a model that should allow us to make the most of all the data we've got online already as well as designing around concepts.
[see notes below for some background]
As well as 'objects' as a basic concept, museums come with a handy set of stable concepts built into our collections management systems. Sometimes these are called 'subject authorities'. They cover things like people and organisations, places, events and the relationships between them. We often build various interpretative narrative layers on top of them – themes, topics, stories, whatever.
If we build permanent URIs around those concepts, we can link to them from the existing microsites. We can also wrap metadata around the elements already on the pages of those microsites so that the data is meaningfully machine-accessible in situ.
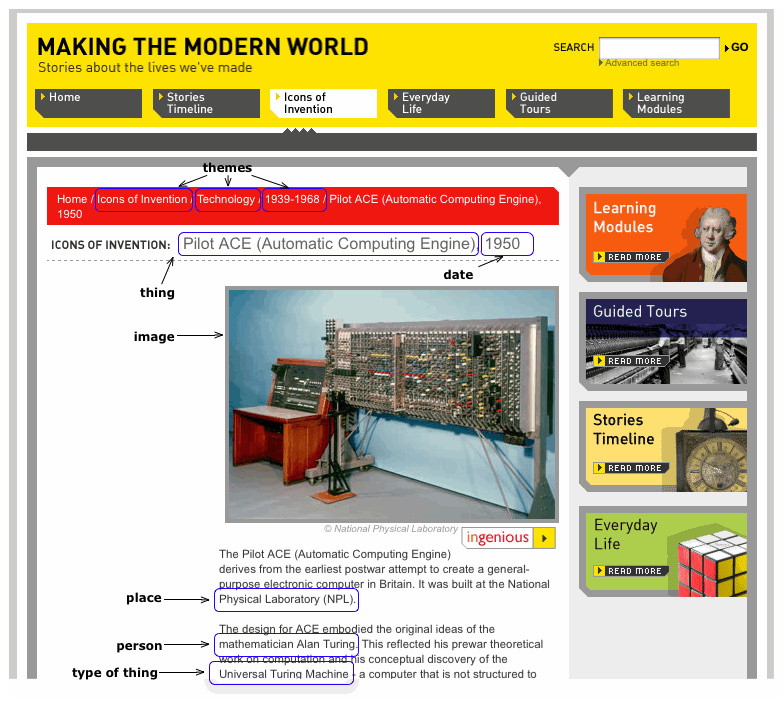
As an example, we'd have http://sciencemuseum.org.uk/objects/1956-152 as the 'home page' for the Pilot ACE computer in our collection. This page would contain the basic 'tombstone' information – when, where, what, etc, and link to every known instance of the object in other sites, as below. These other sites might be exhibitions, subject-specialist sites, cross-institution collections. Often they'll contain information written specifically for that site, particularly tailored for its scope and audiences.
This object is represented in various microsites. The image below shows up we might mark up those sites with links to our Science Museum concepts:
The object home page could also link to the Pilot Ace page on Ingenious and on our Centenary site, and they could link back to the object home. They could also link to our Alan Turing page, National Physical Laboratory page, etc.
It'd be great if we could link to other content about that object – this BBC article on Pilot ACE is a pointer to more content.
Vocabularies
This is one of the places I get stuck… Do we go general or specific? There's lots of stuff out there for visual resources but that doesn't describe our collections well. There's some discussion of this on various pages here, including Authority Lists, Implementation formats, and RDFa (the names get out of control fairly quickly!).
Notes on URIs
Some of our accession numbers are going to make things difficult because they contain '/'.
On Wednesday [you can tell how long ago I started this because that was February 24] I went to the second London Linked Data meetup, held during dev8D.
For a while I've been wondering what we (Science Museum/NMSI) could do with linked data, but it's also taken a while for the issues to bubble up.
The first two issues are data standards and vocabulary. As the saying goes, 'the good thing about standards is that there are so many to choose from'. http://museum-api.pbworks.com/Implementation-formats and http://museum-api.pbworks.com/RDFa bear witness to the difficulties of… finding out what developers prefer to work with (if they care at all), finding out what other museums can output to try and get some critical mass going…
The third is machine-readable interface design. Tom Scott [Apis and APIs] advocates building APIs so that you're linking people to the concepts that matter to them, and making your website your API. I think this is the right way to go, but it's made trickier by the fact that we're not a greenfield site – we've got exhibition microsites that are over ten years old. We're gradually migrating all that data into a central repository, but it'd be good if we could make the data already online in those sites re-usable too.
Other earlier notes… When designing the Cosmic Collections API last year, I'd considered building it into the 'human-facing' website architecture, so that a device could request XML or JSON versions of the pages alongside the (X)HTML pages. In the end I went for a standalone API as an interim solution. The Cosmic Collections competition was designed in part to answer some of my questions about the formats preferred by developers.
Comments on the Science Museum linked data wiki page
This made me realise I've also completely missed out 'exhibitions' as a concept – we do cover this for current exhibitions to an extent, but there's a lot of information hidden in the choices made for previous exhibitions that could be useful. It also contributes to really making the object home the definitive resource.
And another comment – can you tell I should be doing something else today? It's all about constructive procrastination.
Richard Morgan from across the road at the V&A commented (http://twitter.com/rmorg/status/10831225400), 'linked data vocabularies tricky for me too. For V&A I'm tending towards just geo, foaf and dbpedia – more about links than data' which I think is a useful perspective. There is a level at which the precise application of term lists matters, but if it means we spend the next ten years trying to get it perfect rather than doing something now, I'd rather we did something now. The two aren't mutually exclusive technically, but pragmatically I only have limited time/brain space in which to get something done.
Mia, hi… I think you'll need to model both real-world objects and web documents as part of this. So, for example… for any particular artefact, say the lunar lander, you have the thing itself (a real-world object which is assigned one URI) and the description of that thing (a Web document which is assigned a different URI).
To get from the 'object' URI to the 'description' URI requires an HTTP 303 redirect response (unless you choose to use hash URIs).
The 'description' URI can offer multiple representations, e.g. HTML with embedded RDFa and RDF/XML.
I like your list of "URIs and concepts we could model" and the idea of how the web page about an object in the collection can be linked to relevant people, places, images etc.
There's a lot of scope for this approach to help people to explore the collection from different perspectives and via different dimensions.
Vocabularies: this is an area where it makes sense to re-use existing work where possible, but if there is nothing out there that fits your purpose, don't be afraid to invent a new specialist vocabulary of your own. It's easy (and normal practice) to 'mix and match' terms from multiple vocabularies/ontologies as required.
Thanks for your really useful comments, Bill. I've been horribly busy preparing for a conference next week but will respond properly when my feet are back on the ground!
Try to keep in mind that an important reason for publishing the museums artifacts, whether real or digital, is to enable data about them to be "meshed" with other data (from the museum and from elsewhere) and republished, possibly in unanticipated ways, and the "mashed" applications that are created from those datasets. So the answer to whether you are doing it "correctly" will depend on the feedback you get!
The most important thing for you to do is ensure that you make it easy for your community of users to provide you with feedback, wiki a wiki or whatever. Make sure this is obvious and easy, AND that you adapt as they provide that feedback!
You might consider using OpenVocab http://open.vocab.org/ as a means for your community to add new terms.
There's already a great authoritative reference for places: GeoNames Ontology http://www.geonames.org/ontology/ "over 6.2 million geonames toponyms now have a unique URL with a corresponding RDF web service"
I think we can add a point that a RESTful web services (esp. based on simple common standards like Atom) can be useful for bridging between more "Plain Web" design approaches and linked data approaches. Here's a<a href='http://www.alexandriaarchive.org/blog/?p=497'> paper</a> I gave at the Computer Applications in Archaeology conference about this issue.
OK. Try this again, since HTML doesn't work in the comments.
Great discussion of the linked data issues.
I think we can add a point that a RESTful web services (esp. based on simple common standards like Atom) can be useful for bridging between more "Plain Web" design approaches and linked data approaches. Here's a(http://www.alexandriaarchive.org/blog/?p=497) I gave at the Computer Applications in Archaeology conference about this issue.
These thoughts are my own "take homes" from the discussion, rather than any sense of the meeting's overall conclusions.
What data do museums have?
Database content, mostly fielded and designed mainly for collections management support. Textual materials, much of it in a non-accessible "grey literature" format. Images.
The database content is typically (reasonably) self-consistent within a given environment. Thus we have known properties (from the field name) with usable string values. The challenge from a Linked Data perspective is the cost-effective generation of URLs from the string values currently held, e.g. for people and places, given that different museums will have different vocabularies to control their content.
Who wants to use this data?
The public, who are typically interested in classes of objects (rather than individual objects), or in objects with certain properties (e.g. coming from a place of interest to them). Educators, or more specifically people who create resources for educators to use. Students, if relevant objects could be easily accessed as "follow up" to formal learning materials.
Notes on 7 July 2010 meetup (part 2) How do we improve the data?
There is nothing to stop every museum publishing URLs, and whatever associated Linked Data they have to hand, for each object in their own collection, and thereby giving them a "hook" onto which others can hang added-value information and assertions of their own. They should treat this task as an urgent priority.
Where possible, convert string values in data to URLs, ideally widely-used (not just local) ones. Could use e.g. geonames.org for place names, or dbpedia for object class names. Interest in Portsmouth's historical gazetteer for "old" place names.
There is a clear need for a sector-specific ontology which represents the properties found, i.e. the types of information recorded in museum databases. This will act as the "predicate" in Linked Data triples/assertions. It could be based on an existing agreement about these semantics, e.g. CIDOC CRM or LIDO.
Axis-based data such as geographical co-ordinates or dates/date ranges could be treated as purely numerical data, or "pixellated" by assigning a URL which imposes a certain level of precision (e.g. year for dates). Or both approaches could be adopted.
What's the museum take on Linked Data?
Simple assertions are not enough; we care about the attribution of those assertions (i.e. who is making the assertion). We also want a framework which allows the expression of uncertainty and doubt.
We are not particularly bothered about the specific format (RDF/XML, RDFa, JSON, Topic Maps) in which Linked Data is published, but we would like to be able to "do the job once" and have done with it.
Thanks for the minutes Richard – seems like it was a really interesting discussion – shame I couldn't be there – particularly as we've been working with the author of CIDOC to start mapping our data! Look forward to the next meeting. Josh
I been wondering about identifiers, pref. UUID types this sort of fits in where you have [insert museum-y discussion of the exceptions] in your doc. given we have loads of object numbers full of illegal characters (for both file systems and URIs) I thought the concept of MuseumID may be very helpful as we moved toward linked data.. http://museumid.net/about
Find out who won our Cosmic Collections competition.
Cosmic Champions
Last October, we launched a competition to release hundreds of stories from the Cosmos & Culture exhibition on to the web. We invited astronomy enthusiasts, designers and web developers to create their own websites with our objects – and the results are now in.
There were two competitions, to create websites for adults and for the 11-16 age group. We didn’t get enough entries in the second group to award a prize, but the quality of the entries in the adult group was so high that we’ve decided to award an extra prize for that.
Overall winner (£1000 prize)
Simon Willison and Natalie Down Entry at http://cosmos.natimon.com/ The judges felt that Simon and Natalie’s entry made the best use of our collections data, as it allows users to browse objects by people, places and celestial body, making links between them. Judge Chris Lintott describes it as 'having a wikipedia-like quality of sucking the user in for just one more click'.
Runner-up (£750 prize)
Ryan Ludwig Entry at http://www.serostar.com/cosmic/ The judges were really impressed with the visual appeal of Ryan’s entry, particularly the image gallery with thumbnails and zoom function.
The judges also commended Ray Shah’s entry (http://collection.thinkdesign.com/), particularly the function for users to add their own data.
What happens next?
We’ll be working with our winners to incorporate the best aspects of their entries into a finished product. We will be launching it on the Science Museum’s website in February, so watch this space!
Notes
1) The competition judges were:
Christian Heilmann A geek and hacker at heart, Christian Heilmann has been a professional web developer for about eleven years. He has been nominated "standards champion of the year 2008" by .net magazine in the UK and he currently sports the fashionable job title "International Developer Evangelist" spending his time speaking and training people on systems provided by Yahoo and other web companies that want to make this web thing work well for everybody.
Chris Lintott Chris Lintott is a post-doctoral researcher in the Department of Physics at the University of Oxford. His research looks at the analysis of star formation, including being principal investigator for the Galaxy Zoo project. He is also co-presenter on the Sky at Night program alongside Sir Patrick Moore.
2) Entries to the competition were assessed under the following categories:
Use of collections data
Creativity
Accessibility
User experience
Ease of deployment and maintenance
3) The Cosmos & Culture exhibition is supported by the Patrons of the Science Museum with additional support from the Science & Technology Facilities Council, STFC.