The short version: if you've got ideas on how museums, libraries and archives (i.e. GLAM) and the digital humanities can inspire and learn from each other, it's your lucky day! Go add your ideas about concrete actions the Association for Computers and the Humanities can take to bring the two communities together or suggestions for a top ten 'get started in museums and the digital humanities' list (whether conference papers, journal articles, blogs or blog posts, videos, etc) to: 'GLAM and Digital Humanities together FTW'.
Update, August 23, 2012: the document is shaping up to be largely about ‘what can be done’ – which issues are shared by GLAMs and DH, how can we reach people in each field, what kinds of activities and conversations would be beneficial, how do we explain the core concepts and benefits of each field to the other? This suggests there’d be a useful second stage in focusing on filling in the detail around each of the issues and ideas raised in this initial creative phase. In the meantime, keep adding suggestions and sharing issues at the intersection of digital humanities and memory institutions.
A note on nomenclature: the genesis of this particular conversation was among museumy people so the original title of the document reflects that; it also reflects the desire to be practical and start with a field we knew well. The acronym GLAM (galleries, libraries, archives and museums) neatly covers the field of cultural heritage and the arts, but I'm never quite sure how effective it is as a recognisable call-to-action. There's also a lot we could learn from the field of public history, so if that's you, consider yourself invited to the party!
The longer version: in an earlier post from July's Digital Humanities conference in Hamburg I mentioned that a conversation over twitter about museums and digital humanities lead to a lunch with @ericdmj, @clairey_ross, @briancroxall, @amyeetx where we discussed simple ways to help digital humanists get a sense of what can be learnt from museums on topics like digital projects, audience outreach, education and public participation. It turns out the Digital Humanities community is also interested in working more closely with museums, as demonstrated by the votes for point 3 of the Association for Computers and the Humanities (ACH)'s 'Next Steps' document, "to explore relationships w/ DH-sympathetic orgs operating beyond the academy (Museum Computer Network, Nat'l Council on Public History, etc)". At the request of ACH's Bethany Nowviskie (@nowviskie) and Stéfan Sinclair (@sgsinclair), Eric D. M. Johnson and I had been tossing around some ideas for concrete next steps and working up to asking people working at the intersection of GLAM and DH for their input.
However, last night a conversation on twitter about DH and museums (prompted by Miriam Posner's tweet asking for input on a post 'What are some challenges to doing DH in the library?') suddenly took off so I seized the moment by throwing the outline of the document Eric and I had been tinkering with onto Google docs. It was getting late in the UK so I tweeted the link and left it so anyone could edit it. I came back the next morning to find lots of useful and interesting comments and additions and a whole list of people who are interested in continuing the conversation. Even better, people have continued to add to it today and it's already a good resource. If you weren't online at that particular time it's easy to miss it, so this post is partly to act as a more findable marker for the conversation about museums, libraries, archives and the digital humanities.
Explaining the digital humanities to GLAMs
This definition was added to the document overnight. If you're a GLAM person, does it resonate with you or does it need tweaking?
"The broadest definition would be 1) using digital technologies to answer humanities research questions, 2) studying born digital objects as a humanist would have studied physical objects, and or 3) using digital tools to transform what scholarship is by making it more accessible on the open web."
How can you get involved?
Off the top of my head…
Add your name to the list of people interested in keeping up with the conversation
Read through the suggestions already posted; if you love an idea that's already there, say so!
Read and share the links already added to the document
Suggest specific events where GLAM and DH people can mingle and share ideas/presentations
Suggest specific events where a small travel bursary might help get conversations started
Offer to present on GLAMs and DH at an event
Add examples of digital projects that bridge the various worlds
Add examples of issues that bridge the various worlds
Write case studies that address some of the issues shared by GLAMs and DH
Spread the word via specialist mailing lists or personal contacts
Share links to conference papers, journal articles, videos, podcasts, books, blog posts, etc, that summarise some of the best ideas in ways that will resonate with other fields
Consider attending or starting something like Decoding Digital Humanities to discuss issues in DH. (If you're in or near Oxford and want to help me get one started, let me know!)
Something else I haven't thought of…
I'm super-excited about this because everyone wins when we have better links between museums and digital humanities. Personally, I've spent a decade working in various museums (and their associated libraries and archives) and my PhD is in Digital Humanities (or more realistically, Digital History), and my inner geek itches to find an efficient solution when I see each field asking some of the same questions, or asking questions the other field has been working to answer for a while. This conversation has already started to help me discover useful synergies between GLAMs and DH, so I hope it helps you too.
I'm in Hamburg for the 2012 Digital Humanities conference. The conference only officially started last night, but after two days of workshops and conversations I already feel like my brain is full, so this post is partly a brain dump to free up some space for new ideas.
The session I chaired on Methods was a chance to think about the ways in which tools are instantiations of methods. If the methods underlying tools aren't those of humanists, or aren't designed suitably for glorious but messy humanities data, are they suitable for humanities work? If they're not suitable, then what? And if they're used anyway, how do humanists learn when to read a visualisation 'with a grain of salt' and distinguish the 'truthiness' of something that appears on a screen from the complex process of selecting and tidying sources that underlies it? What are the implications of this new type of digital literacy for peer reviews of DH work (whether work that explicitly considers impact of digitality on scholarly practice, or work that uses digital content within more traditional academic frameworks)? How can humanists learn to critique tool choice in the same way they critique choice of sources? Humanists must be able to explain the methods behind the tools they've used, as they have such a critical impact on the outcomes.
[Update: 'FairCite' is an attempt to create 'clear citation guidelines for digital projects that acknowledge the collaborative reality of these undertakings' for the Alliance of Digital Humanities Organizations.] We also discussed the notion of academic publications designed so that participation and interaction is necessary to unlock the argument or narrative they represent, so that the reader is made aware of the methods behind the tools by participating in their own interpretive process. How do we get to have 'interactive scholarly works' in academia – what needs to change to enable them? How are they reviewed, credited, sustained? And what can we learn from educators and museum people about active reading, participation and engagement?
Our group also came up with the idea of methods as a bridge between different experts (technologists, etc) and humanists, a place for common understanding (generated through the process of making tools?), and I got to use the phrase 'the siren's lure of the shiny tool', which was fun. We finished on a positive note with mention of the DH Commons as a place to find a technologist or a humanist to collaborate with, but also to find reviewers for digital projects.
Having spent a few days thinking about messy data, tweets about a post on The inevitable messiness of digital metadata were perfectly timed. The post quotes Neil Jeffries from the Bodleian Library, who points out:
we need to capture additional metadata that qualifies the data, including who made the assertion, links to differences of scholarly opinion, omissions from the collection, and the quality of the evidence. "Rather than always aiming for objective statements of truth we need to realise that a large amount of knowledge is derived via inference from a limited and imperfect evidence base, especially in the humanities," he says. "Thus we should aim to accurately represent the state of knowledge about a topic, including omissions, uncertainty and differences of opinion."
and concludes "messiness is not only the price we pay for scaling knowledge aggressively and collaboratively, it is a property of networked knowledge itself". Hoorah!
What can the digital humanities learn from museums?
After a conversation over twitter, a few of us (@ericdmj, @clairey_ross, @briancroxall, @amyeetx) went for a chat over lunch. Our conversation was wide-ranging, but one practical outcomes was the idea of a 'top ten' list of articles, blog posts and other resources that would help digital humanists get a sense of what can be learnt from museums on topics like digital projects, audience outreach, education and public participation. Museum practitioners are creating spaces for conversations about failures, which popped up in the #DH2012 twitter stream.
So which conference papers, journal articles, blogs or blog posts, etc, would you suggest for a top ten 'get started in museums and the digital humanities' list?
…in Britain the problem is I think that the digital humanities has failed to develop its own distinctive intellectual agendas and is still to all intents and purposes a support service. The digital humanities in Britain has generally emerged from information service units and has never fully escaped these origins. Even in units which are defined as academic departments, such as my own in King’s, the assumption generally is that the leading light in the project will be an academic in a conventional academic department. The role of the digital humanities specialists in constructing this project is always at root a support one. We try and suggest that we are collaborating in new ways, but at the end of the day a unit like that at King’s is simply an XML factory for projects led by other researchers.
Beyond the question of how and why digital people are pushed into support roles in digital humanities projects, I've also been wondering whether the academic world actually allows one to simultaneously be a technologist and a humanist. This is partly because I'm still mulling over the interactions between different disciplines at a recent research institute and partly because of a comment about a recently advertised 'digital historian' job that called it "'Digital Historian' as slave to real thing – no tenure, no topic, no future".
The statement 'no topic' particularly stood out. I'm not asking whether it's possible for someone to be a good historian and a good programmer (for example) because clearly some people are both, but rather whether hiring, funding, training and academic structures allow one to be both technologist and humanist. Can one propose both a data architecture and a research question?
It may simply be that people with specialist skills are leant on heavily in a project because their skills are vital for its success, but does this mean an individual is corralled into one type of work to the exclusion of others? If you are the only programmer-historian in a group of historians, do you only get to be a programmer, and vice versa? Are there academic roles that truly make the most of both aspects of the humanist technologist?
And does this mean, as Prescott says, that 'intellectually, the digital humanities is always reactive'?
A quick report and Storify summary from Wednesday's joint Museums Computer Group (MCG) and Digital Learning Network (DLNet) conference, 'Engaging digital audiences in museums', which was held on 11 July 2012 at the University of Manchester. I'm the Chair of the MCG and was on the Programming Committee for this event so I make absolutely no claim to impartiality, but I thought it went really well – great speakers and workshop leaders, enthusiastic and friendly participants and a variety of formats that kept energy levels up during the day.
My notes are sketchier than usual as I was co-chairing some of the sessions and keeping an eye on the running of the event, so this is more of an impressionistic overview than a detailed report. There are already a number of other posts out there, and we'll have the post from our official event blogger and illustrator up soon for more comprehensive accounts.
For the MCG, this event was experimental in a number of ways – in running an event with another practitioner organisation, in the venue, in running parallel workshops, buying in commercial wifi, and in devoting part of the day to an unconference – and I'm curious to know what response we get in the evaluation from the day. (If you were there, our short feedback form is online.)
The event was designed to bring museum learning and technology staff together because we felt we were missing opportunities to benefit from each others skills and experience. I know technologists are grappling with measuring impact, and learning people with reaching new audiences in different ways – hopefully each group would have something to offer and something to learn, though it might mean seeing past each others jargon and understanding different views of the world. (This 'Interloper Report' and comments from MW2012 provide some insight into the potential.) We planned the day as a mixture of inspiring talks and opportunities to get stuck into conversation about topical issues. It was also a day for making connections so we'd included coffee breaks, lunch and the unconference so that people could find others interested in similar things or to put faces to names from the MCG and DLNet lists and social media. The various tweets I've added to storify do a reasonable job of covering the day, but I've left out things like the QR code discussion. Other conversations about generic learning outcomes have taken on a life of their own – for example, Rhiannon's post 'Generic Learning Outcomes – friend or foe?' seeks to understand why non-learning people don't seem to like them.
I thought Nick Winterbotham's presentation of the Group for Education in Museums (GEM) 'self-evident truths' was interesting, and some of his points were picked up and retweeted widely:
Our heritage is not about things it is about people
Everyone has a right to know about and be at ease with heritage
Heritage embraces the past and present of all cultures
Heritage is essential as the cradle of everyone's tomorrow
Heritage encompasses all literature, science, technology, environments and arts
The multiple narratives of heritage deserve respect
Learning is an entitled journey, not a destination
Heritage learning is an entitlement for everyone
The development of heritage learning skills must be a perpetual excellence
Learning is not simply a justification for cultural spending, it is THE justification for cultural spending
Nick advocated for a world where no-one hesitates at taking a risk in learning, and said that we love art, digital culture because of how we feel about it, not what we know about it. He urged us to focus on how your audiences live, learn and love your subject matter; to acknowledge the intellectual generosity needed; and find the big idea that will transform your organisation.
Matthew Cock talked about the challenges of audiences, particularly around mobile. The three-pronged model for audiences in museums: attract -> engage -> impact. He asked, when you see someone in a museum with a phone, what space are they in? Are they engaged, distracted, focused? Is it a sign of disrespect and disengagement or a sign of bonding with the group they're with? And how do you know?
He talked about the work Morris Hargreaves McIntyre had done to understand their audiences and their varying motivations for visiting: social – museums as enjoyable place to spend time with friends and family; intellectual – interested in knowledge; emotional – experience what the past was like; spiritual – creative stimulation, quiet contemplation, etc. (See also MHM's Culture Segments report). How does this connect to using mobiles to engage people? People have different activities – chat, read, recording audio or photo, playing media back, share something via social media etc. Each fulfills a different need. The challenge is to match specific things you can do on a mobile with your motivations for visiting. He referred to Maslow's hierarchy of needs to think about the needs a museum satisfies in our lives and the experience economy.
People are seeking venues and events that engage them in a memorable (and authentic?) ways – we're shifting from buying lots of stuff to seeking unique and engaging experiences. The visitor wants to walk away with the engagement having effected a transformation (the impact point of the three-pronged model). Measuring that impact is really hard. Evaluation can look at lots of things but it's hard to understand the needs of our visitors and what works for them in this space.
Later I asked what Learning people like Nick could tell us technologists about measuring impact, but it seems like it's the holy grail for their field too. Nick did mention that we go from a stage of cognitive to affective impact over time after an experience, which is a good start for thinking about this. Judging from the response on twitter, I'm not the only one who thinks that measuring the impact of a museum experience and understanding whether it's ephemeral or lifelong is one of the big tasks for museums right now.
John Coburn's presentation on the Hidden Newcastle app harked back to the buzz around storytelling a few years ago, but it also resonated with conversations about the different types and purposes of museum websites – an app that's not about sharing collections or objects but about sharing compelling stories fits firmly in the 'messy middle'. In this case, 'it's the story that creates the impact, not the object. The value of the object is as the source for the story'. I love that they wanted to create intrigue about the people and the times in which they lived and compel exploration.
It was a difficult choice but I popped into the 'tech on a budget' workshop where Shona Carnall and Greg Povey presented some interesting ways to use existing, readily available technologies to create interactive experiences.
I'll leave the detail of the other presentations to the storify below and other people's posts and skip to the unconference.Because time was short we asked for session ideas and votes from the podium, rather than letting people write ideas and put their votes up on a shared board. After the unconference we all gathered again to hear what had been discussed in each group. The summaries were:
Commercial side of commissioning cool things: reluctant to put a price on it, but UK has cultural expectations around free museums which makes it harder to charge. Digital is received as god given right, something that should be free. But how come the West End theatre is able to charge so much for a ticket? Museums providing paid-for entertainment not just a browsing experience. We pay for entertainment but we don't expect to be entertained in museums.
Learning outcomes: friends or foe? Attitude is sometimes that learning outcomes are rubbish – decided generic learning outcomes (GLOs) are a really good thing. It's not about shoe-horning facts into everything or pure knowledge transfer – it's also about inspiration, experience, skills, wonderment. The wondrous Romans! Trying to change the stigma about what learning actually is, it's an experience as much as formal education. Maybe 'aims and objectives' a better term than 'learning outcomes'.
How do you evaluate wonderment – with difficulty. What is it? Element of surprise, something being visceral, physiological responses. Are adults too cynical for wonderment? 'Smiling Victorians' – challenge expectations. Imagine writing a budget to get iris recognition to measure wonder! Hard to measure or evaluate it but should always aspire to it.
Coherent experience, call to action in gallery to online with mobile in gallery: talked about pressure museums are under to introduce next tech, be whizzy, or is it addressing a real need? Can you piggyback on software that's already out there?
Reaching different audiences: particularly teenagers: find out what inspires them, tap into that. What are the barriers to engaging them? They're creative, maybe we should work with them to create digital offers, empower them. Apps for apps sake – under pressure to deliver them.
Big ideas: intellectual generosity. (Goodness! There was a long list of the characteristics MCG and DLNet would have if they were an animal or a tool…) We are intricate explosions. Intricate – all the stuff we're talking about is detailed and a little fragile but explosive because the world will catch fire with what we're doing.
Failure confessionals: web content management systems – maybe simple is the way to go. Failure is a good thing, and at least we didn't screw up like the bankers.
Social media audiences: does it make sense just to have one FB, twitter, etc account per org? Keeping a brand together is good but it doesn't always make sense to lump all audience conversations into one channel.
And with the final thanks to the student volunteers, programme committee, unconference organisers and speakers (and particularly to Ade as local contact and Rhiannon as the tireless organiser that made it all happen), it was over.
We're already looking ahead to the MCG's Spring 2013 meeting, which may be an experimental 'distributed' meeting held in the same week or evening in different regional locations. If you're interested in hosting a small-scale event with us somewhere in the UK, get in touch! We're also thinking about themes for UK Museums on the Web 2012, so again, let us know if you have any ideas.
A few years ago the Museums Computer Group committee started inviting people attending our events to join us for drinks the night before. For locals and people who've travelled up the night before an event, it's a nice way to start to catch up with or meet people who are interested in technology in museums. These days people around the world are organising events under the #drinkingaboutmuseums label, so we thought we'd combine the two and have a #drinkingaboutmuseums in Manchester on Tuesday July 10, 2012. Come join us from 6:30pm at the Sandbar, 120 Grosvenor Street, Manchester M1 7HL.
And of course, the reason we're gathering – on Wednesday July 11, 2012, the MCG (@ukmcg) are running an event with the Digital Learning Network (@DLNet) on 'Engaging digital audiences in museums' in Manchester (tickets possibly still available at http://mcg-dlnet.eventbrite.com/ or follow the hashtag #EngageM on twitter) so we'll have a mixed crowd of museum technologists and educators. You're welcome to attend even if you're not going to the conference.
If you've got any questions, just leave a comment or @-mention me (@mia_out) on twitter. We'll also keep an eye on the #drinkingaboutmuseums tag. You can find out more about #drinkingaboutmuseums in my post about the June New York edition which saw 20-ish museum professionals gather to chat over drinks.
Our time at the NEH Institute on Spatial Narratives & Deep Maps is almost at an end. The past fortnight feels both like it’s flown by and like we’ve been here for ages, which is possibly the right state of mind for thinking about deep maps. After two weeks of debate deep maps still seem definable only when glimpsed in the periphery and yet not-quite defined when examined directly. How can we capture the almost-tangible shape of a truly deep map that we can only glimpse through the social constructs, the particular contexts of creation and usage, discipline and the models in current technology? If deep maps are an attempt to get beyond the use of location-as-index and into space-as-experience, can that currently be done more effectively on a screen or does covering a desk in maps and documents actually allow deeper immersion in a space at a particular time?
We’ve spent the past three days working in teams to prototype different interfaces to deep maps or spatial narratives, and each group presented their interfaces today. It’s been immensely fun and productive and also quite difficult at times. It’s helped me realise that deep maps and spatial narratives are not dichotomous but exist on a scale – where do you draw the line between curating data sources and presenting an interpreted view of them? At present, a deep map cannot be a recreation of the world, but it can be a platform for immersive thinking about the intersection of space, time and human lives. At what point do you move from using a deep map to construct a spatial and temporal argument to using a spatial narrative to present it?
The experience of our (the Broadway team) reinforces Stuart’s point about the importance of the case study. We uncovered foundational questions whilst deep in the process of constructing interfaces: is a deep map a space for personal exploration, comparison and analysis of sources, or is it a shared vision that is personalised through the process of creating a spatial narrative? We also attempted to think through how multivocality translates into something on a screen, and how interfaces that can link one article or concept to multiple places might work in reality, and in the process re-discovered that each scholar may have different working methods, but that a clever interface can support multivocality in functionality as well as in content.
I'm a week and a bit into the NEH Institute for Advanced Topics in the Digital Humanities on 'Spatial Narrative and Deep Maps: Explorations in the Spatial Humanities', so this is a (possibly self-indulgent) post to explain why I'm over in Indianapolis and why I only seem to be tweeting with the #PolisNEH hashtag. We're about to dive into three days of intense prototyping before wrapping things up on Friday, so I'm posting almost as a marker of my thoughts before the process of thinking-through-making makes me re-evaluate our earlier definitions. Stuart Dunn has also blogged more usefully on Deep maps in Indy.
We spent the first week hearing from the co-directors David Bodenhamer (history, IUPUI), John Corrigan (religious studies, Florida State University), and Trevor Harris (geography, West Virginia University) and guest lecturers Ian Gregory (historical GIS and digital humanities, Lancaster University) and May Yuan (geonarratives, University of Oklahoma), and also from selected speakers at the Digital Cultural Mapping: Transformative Scholarship and Teaching in the Geospatial Humanities at UCLA. We also heard about the other participants projects and backgrounds, and tried to define 'deep maps' and 'spatial narratives'.
It's been pointed out that as we're at the 'bleeding edge', visions for deep mapping are still highly personal. As we don't yet have a shared definition I don't want to misrepresent people's ideas by summarising them, so I'm just posting my current definition of deep maps:
A deep map contains geolocated information from multiple sources that convey their source, contingency and context of creation; it is both integrated and queryable through indexes of time and space.
Essential characteristics: it can be a product, whether as a snapshot static map or as layers of interpretation with signposts and pre-set interactions and narrative, but is always visibly a process. It allows open-ended exploration (within the limitations of the data available and the curation processes and research questions behind it) and supports serendipitous discovery of content. It supports curiosity. It supports arguments but allows them to be interrogated through the mapped content. It supports layers of spatial narratives but does not require them. It should be compatible with humanities work: it's citable (e.g. provides URL that shows view used to construct argument) and provides access to its sources, whether as data downloads or citations. It can include different map layers (e.g. historic maps) as well as different data sources. It could be topological as well as cartographic. It must be usable at different scales: e.g. in user interface – when zoomed out provides sense of density of information within; e.g. as space – can deal with different levels of granularity.
Essential functions: it must be queryable and browseable. It must support large, variable, complex, messy, fuzzy, multi-scalar data. It should be able to include entities such as real and imaginary people and events as well as places within spaces. It should support both use for presentation of content and analytic use. It should be compelling – people should want to explore other places, times, relationships or sources. It should be intellectually immersive and support 'flow'.
Looking at it now, the first part is probably pretty close to how I would have defined it at the start, but my thinking about what this actually means in terms of specifications is the result of the conversations over the past week and the experience everyone brings from their own research and projects.
For me, this Institute has been a chance to hang out with ace people with similar interests and different backgrounds – it might mean we spend some time trying to negotiate discipline-specific language but it also makes for a richer experience. It's a chance to work with wonderfully messy humanities data, and to work out how digital tools and interfaces can support ambiguous, subjective, uncertain, imprecise, rich, experiential content alongside the highly structured data GIS systems are good at. It's also a chance to test these ideas by putting them into practice with a dataset on religion in Indianapolis and learn more about deep maps by trying to build one (albeit in three days).
I've always been fascinated with the idea of making the invisible and intangible layers of history linked to any one location visible again. Millions of lives, ordinary or notable, have been lived in London (and in your city); imagine waiting at your local bus stop and having access to the countless stories and events that happened around you over the centuries. … The nice thing about local data is that there are lots of people making content; the not nice thing about local data is that it's scattered all over the web, in all kinds of formats with all kinds of 'trustability', from museums/libraries/archives, to local councils to local enthusiasts and the occasional raving lunatic. … Location-linked data isn't only about official cultural heritage data; it could be used to display, preserve and commemorate histories that aren't 'notable' or 'historic' enough for recording officially, whether that's grime pirate radio stations in East London high-rise roofs or the sites of Turkish social clubs that are now new apartment buildings. Museums might not generate that data, but we could look at how it fits with user-generated content and with our collecting policies.
Amusingly, four years ago my obsession with 'open sourcing history' was apparently already well-developed and I was asking questions about authority and trust that eventually informed my PhD – questions I hope we can start to answer as we try to make a deep map. Fun!
Finally, my thanks to the NEH and the Institute organisers and the support staff at the Polis Center and IUPUI for the opportunity to attend.
Inspired by Koven J. Smith and Kathleen Tinworth's 'Drinking About Museums' in Denver and Ed Rodley's version in Boston, we'redrinking about museums (and libraries and archives) in New York this Friday (June 15, 2012), and you're invited! Since I'm only in NYC for a week and still get confused about whether I'm heading uptown or downtown at any given time, Neal Stimler @nealstimler has kindly taken care of organising things. If you're interested in coming, let him know so you can grab his contact details and we know to keep an eye out for you. We're heading to k2 Friday night at the Rubin Museum of Art, 150 W. 17 St., NYC 10011. We'll be there from 6:30 until closing at 10pm. The table is booked for Mia Ridge, and we should have enough room that you can just turn up and grab a seat. It's free entry to the gallery from 6-10:00 p.m and the K2 Lounge serves food.
If you've got any questions, just leave a comment or @-mention me (@mia_out) on twitter. We'll also keep an eye on the #drinkingaboutmuseums tag.
Museums should stick to what they do best – to preserve, display, study and where possible collect the treasures of civilisation and of nature. They are not fit to do anything else. It is this single rationale for the museum that makes each one unique, which gives each its own distinctive character. It is the hard work of scholars and curators in their own areas of expertise that attracts visitors. Everybody knows that the harder you try to win friends and ingratiate yourself with people, the more repel you them. It would seem however that those running our new museums need to learn afresh this simple human lesson.
Source: Josie Appleton, "Museums for 'The People'?" in 'Museums and their Communities', edited by Sheila Watson (2007).
We just think that Creative Commons data is real data. It’s data that people can really use. It’s all about access, and access is about several things: licensing and publishing the raw data. Any data that you capture should be available to be the public. … The other important thing is to put the data in places where people can find it… The Walters is a museum that’s free to the public, and to be public these days is to be on the Internet. Therefore to be a public museum your digital data should be free. And the great thing about digital data, particularly of historic collections, is that they’re the greatest advert that these collections have. … The digital data is not a threat to the real data, it’s just an advertisement that only increases the aura of the original…
…
…people go to the Louvre because they’ve seen the Mona Lisa; the reason people might not be going to an institution is because they don’t know what’s in your institution. Digitization is a way to address that issue, in a way that with medieval manuscripts, it simply wasn’t possible before. People go to museums because they go and see what they already know, so you’ve got to make your collections known. Frankly, you can write about it, but the best thing you can do is to put out free images of it. This is not something you do out of generosity, this is something you do because it makes branding sense, and it even makes business sense. So that’s what’s in it for the institution.
The other main reason to do it is to increase the knowledge of and research on your collection by the people, which has to be part of your mission at least, even in the most conservative of institutions.
Btw, if you're in New York and fancy meeting up for a coffee before June 17, drop me a line in the comments or @mia_out. (Or ditto for Indianapolis June 17-30).
Over time I've noticed the repetition of various misconceptions and apprehensions about crowdsourcing for cultural heritage and digital history, so since this is a large part of my PhD topic I thought I'd collect various resources together as I work to answer some FAQs. I'll update this post over time in response to changes in the field, my research and comments from readers. While this is partly based on some writing for my PhD, I've tried not to be too academic and where possible I've gone for publicly accessible sources like blog posts rather than send you to a journal paywall.
[Last updated: February 2016, to address 'crowdsourcing steals jobs'. Previous updates added a link to CCLA events, crowdsourcing projects to explore and a post on machine learning+crowdsourcing.]
What is crowdsourcing?
Definitions are tricky. Even Jeff Howe, the author of 'Crowdsourcing' has two definitions:
The White Paper Version: Crowdsourcing is the act of taking a job traditionally performed by a designated agent (usually an employee) and outsourcing it to an undefined, generally large group of people in the form of an open call.
The Soundbyte Version: The application of Open Source principles to fields outside of software.
For many reasons, the term 'crowdsourcing' isn't appropriate for many cultural heritage projects but the term is such neat shorthand that it'll stick until something better comes along. Trevor Owens (@tjowens) has neatly problematised this in The Crowd and The Library:
'Many of the projects that end up falling under the heading of crowdsourcing in libraries, archives and museums have not involved large and massive crowds and they have very little to do with outsourcing labor. … They are about inviting participation from interested and engaged members of the public [and] continue a long standing tradition of volunteerism and involvement of citizens in the creation and continued development of public goods'
Defining crowdsourcing in cultural heritage
To summarise my own thinking and the related literature, I'd define crowdsourcing in cultural heritage as an emerging form of engagement with cultural heritage that contributes towards a shared, significant goal or research area by asking the public to undertake tasks that cannot be done automatically, in an environment where the tasks, goals (or both) provide inherent rewards for participation.
Good question! One tension underlying the 'openness' of the call to participate in cultural heritage is the fact that there's often a difference between the theoretical reach of a project (i.e. everybody) and the practical reach, the subset of 'everybody' with access to the materials needed (like a computer and an internet connection), the skills, experience and time… While 'the crowd' may carry connotations of 'the mob', in 'Digital Curiosities: Resource Creation Via Amateur Digitisation', Melissa Terras (@melissaterras) points out that many 'amateur' content creators are 'extremely self motivated, enthusiastic, and dedicated' and test the boundaries between 'between definitions of amateur and professional, work and hobby, independent and institutional' and quotes Leadbeater and Miller's 'The Pro-Am Revolution' on people who pursue an activity 'as an amateur, mainly for the love of it, but sets a professional standard'.
There's more and more talk of 'community-sourcing' in cultural heritage, and it's a useful distinction but it also masks the fact that nearly all crowdsourcing projects in cultural heritage involve a community rather than a crowd, whether they're the traditional 'enthusiasts' or 'volunteers', citizen historians, engaged audiences, whatever. That said, Amy Sample Ward has a diagram that's quite useful for planning how to work with different groups. It puts the 'crowd' (people you don't know), 'network' (the community of your community) and 'community' (people with a relationship to your organisation) in different rings based on their closeness to you.
'The crowd' is differentiated not just by their relationship to your organisation, or by their skills and abilities, but their motivation for participating is also important – some people participate in crowdsourcing projects for altruistic reasons, others because doing so furthers their own goals.
I'm worried about about crowdsourcing because…
…isn't letting the public in like that just asking for trouble?
@lottebelice said she'd heard people worry that 'people are highly likely to troll and put in bad data/content/etc on purpose' – but this rarely happens. People worried about this with user-generated content, too, and while kids in galleries delight in leaving rude messages about each other, it's rare online.
It's much more likely that people will mistakenly add bad data, but a good crowdsourcing project should build any necessary data validation into the project. Besides, there are generally much more interesting places to troll than a cultural heritage site.
And as Matt Popke pointed out in a comment, 'When you have thousands of people contributing to an entry you have that many more pairs of eyes watching it. It's like having several hundred editors and fact-checkers. Not all of them are experts, but not all of them have to be. The crowd is effectively self-policing because when someone trolls an entry, somebody else is sure to notice it, and they're just as likely to fix it or report the issue'. If you're really worried about this, an earlier post on Designing for participatory projects: emergent best practice' has some other tips.
…doesn't crowdsourcing take advantage of people?
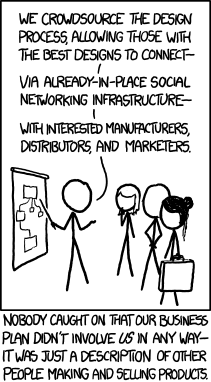
XKCD on the ethics of commercial crowdsourcing
Sadly, yes, some of the activities that are labelled 'crowdsourcing' do. Design competitions that expect lots of people to produce full designs and pay a pittance (if anything) to the winner are rightly hated. (See antispec.com for more and a good list of links).
But in cultural heritage, no. Museums, galleries, libraries, archives and academic projects are in the fortunate position of having interesting work that involves an element of social good, and they also have hugely varied work, from microtasks to co-curated research projects. Crowdsourcing is part of a long tradition of volunteering and altruistic participation, and to quote Owens again, 'Crowdsourcing is a concept that was invented and defined in the business world and it is important that we recast it and think through what changes when we bring it into cultural heritage.'
[Update, May 2013: it turns out museums aren't immune from the dangers of design competitions and spec work: I've written On the trickiness of crowdsourcing competitions to draw some lessons from the Sydney Design competition kerfuffle.]
"when you treat a crowd as disposable and anonymous, you prevent them from achieving their maximum ability. Disposable crowds create disposable output. Simply put: crowds need a sense of identity and community to achieve their potential."
…crowdsourcing can't be used for academic work
Reasons given include 'humanists don't like to share their knowledge' with just anyone. And it's possible that they don't, but as projects like Transcribe Bentham and Trove show, academics and other researchers will share the work that helps produce that knowledge. (This is also something I'm examining in my PhD. I'll post some early findings after the Digital Humanities 2012 conference in July).
Looking beyond transcription and other forms of digitisation, it's worth checking out Prism, 'a digital tool for generating crowd-sourced interpretations of texts'.
…it steals jobs
Once upon a time, people starting a career in academia or cultural heritage could get jobs as digitisation assistants, or they could work on a scholarly edition. Sadly, that's not the case now, but that's probably more to do with year upon year of funding cuts. Blame the bankers, not the crowdsourcers.
The good news? Crowdsourcing projects can create jobs – participatory projects need someone to act as community liaison, to write the updates that demonstrate the impact of crowdsourced contributions, to explain the research value of the project, to help people integrate it into teaching, to organise challenges and editathons and more.
What isn't crowdsourcing?
…'the wisdom of the crowds'?
Which is not just another way of saying 'crowd psychology', either (another common furphy). As Wikipedia puts it, 'the wisdom of the crowds' is based on 'diverse collections of independently-deciding individuals'. Handily, Trevor Owens has just written a post addressing the topic: Human Computation and Wisdom of Crowds in Cultural Heritage.
…user-generated content
So what's the difference between crowdsourcing and user-generated content? The lines are blurry, but crowdsourcing is inherently productive – the point is to get a job done, whether that's identifying people or things, creating content or digitising material.
Conversely, the value of user-generated content lies in the act of creating it rather than in the content itself – for example, museums might value the engagement in a visitor thinking about a subject or object and forming a response to it in order to comment on it. Once posted it might be displayed as a comment or counted as a statistic somewhere but usually that's as far as it goes.
And @sherah1918 pointed out, there's a difference between asking for assistance with tasks and asking for feedback or comments: 'A comment book or a blog w/comments isn't crowdsourcing to me … nor is asking ppl to share a story on a web form. That is a diff appr to collecting & saving personal histories, oral histories'.
Crowdfunding (it's often just asking for micro-donations, though it seems that successful crowdfunding projects have a significant public engagement component, which brings them closer to the concerns of cultural heritage organisations. It's also not that new. See Seventeenth-century crowd funding for one example.)
Data-mining social media and other content (though I've heard this called 'passive' or 'implict' crowdsourcing)
General calls for content, help or participation (see 'user-generated content') or vaguely asking people what they think about an idea. Asking for feedback is not crowdsourcing. Asking for help with your homework isn't crowdsourcing, as it only benefits you.
Buzzwords applied to marketing online. And as @emmclean said, "I think many (esp mkting) see "crowdsourcing" as they do "viral" – just happens if you throw money at it. NO!!! Must be great idea" – it must make sense as a crowdsourced task.
Ok, so what's different about crowdsourcing in cultural heritage?
'The process of crowdsourcing projects fulfills the mission of digital collections better than the resulting searches… Far better than being an instrument for generating data that we can use to get our collections more used it is actually the single greatest advancement in getting people using and interacting with our collections. … At its best, crowdsourcing is not about getting someone to do work for you, it is about offering your users the opportunity to participate in public memory … it is about providing meaningful ways for the public to enhance collections while more deeply engaging and exploring them'.
[This was written in 2012. I've kept it for historical reasons but think differently now.]
First, another definition. As Fiona Romeo writes, 'Citizen science projects use the time, abilities and energies of a distributed community of amateurs to analyse scientific data. In doing so, such projects further both science itself and the public understanding of science'. As Romeo points out in a different post, 'All citizen science projects start with well-defined tasks that answer a real research question', while citizen history projects rarely if ever seem to be based around specific research questions but are aimed more generally at providing data for exploration. Process vs product?
I'm still thinking through the differences between citizen science and citizen history, particularly where they meet in historical projects like Old Weather. Both citizen science and citizen history achieve some sort of engagement with the mindset and work of the equivalent professional occupations, but are the traditional differences between scientific and humanistic enquiry apparent in crowdsourcing projects? Are tools developed for citizen science suitable for citizen history? Does it make a difference that it's easier to take a new interest in history further without a big investment in learning and access to equipment?
I have a feeling that 'citizen science' projects are often more focused on the production of data as accurately and efficiently as possible, and 'citizen history' projects end up being as much about engaging people with the content as it is about content production. But I'm very open to challenges on this…
What kind of cultural heritage stuff can be crowdsourced?
I wrote this list of 'Activity types and data generated' over a year ago for my Masters dissertation on crowdsourcing games for museums and a subsequent paper for Museums and the Web 2011, Playing with Difficult Objects – Game Designs to Improve Museum Collections (which also lists validation types and requirements). This version should be read in the light of discussion about the difference between crowdsourcing and user-generated content and in the context of things people can do with museums and with games, but it'll do for now:
Activity
Data generated
Tagging (e.g. steve.museum, Brooklyn Museum Tag! You're It; variations include two-player 'tag agreement' games like Waisda?, extensions such as guessing games e.g. GWAP ESP Game, Verbosity, Tiltfactor Guess What?; structured tagging/categorisation e.g. GWAP Verbosity, Tiltfactor Cattegory)
Tags; folksonomies; multilingual term equivalents; structured tags (e.g. 'looks like', 'is used for', 'is a type of').
Debunking (e.g. flagging content for review and/or researching and providing corrections).
Linking (e.g. linking objects with other objects, objects to subject authorities, objects to related media or websites; e.g. MMG Donald).
Relationship data; contextualising detail; information on history, workings and use of objects; illustrative examples.
Stating preferences (e.g. choosing between two objects e.g. GWAP Matchin; voting on or 'liking' content).
Preference data; subsets of 'highlight' objects; 'interestingness' values for content or objects for different audiences. May also provide information on reason for choice.
Categorising (e.g. applying structured labels to a group of objects, collecting sets of objects or guessing the label for or relationship between presented set of objects).
Relationship data; preference data; insight into audience mental models; group labels.
Creative responses (e.g. write an interesting fake history for a known object or purpose of a mystery object.)
Relevance; interestingness; ability to act as social object; insight into common misconceptions.
You can also divide crowdsourcing projects into 'macro' and 'micro' tasks – giving people a goal and letting them solve it as they prefer, vs small, well-defined pieces of work, as in the 'Umbrella of Crowdsourcing' at The Daily Crowdsource and there's a fair bit of academic literature on other ways of categorising and describing crowdsourcing.
Using crowdsourcing to manage crowdsourcing
There's also a growing body of literature on ecosystems of crowdsourcing activities, where different tasks and platforms target different stages of the process. A great example is Brooklyn Museum’s ‘Freeze Tag!’, a game that cleans up data added in their tagging game. An ecosystem of linked activities (or games) can maximise the benefits of a diverse audience by providing a range of activities designed for different types of participant skills, knowledge, experience and motivations; and can encompass different levels of participation from liking, to tagging, finding facts and links.
A participatory ecosystem can also resolve some of the difficulties around validating specialist tags or long-form, more subjective content by circulating content between activities for validation and ranking for correctness, 'interestingness' (etc) by other players (see for example the 'Contributed data lifecycle' diagram on my MW2011 paper or the 'Digital Content Life Cycle' for crowdsourcing in Oomen and Aroyo's paper below). As Nina Simon said in The Participatory Museum, 'By making it easy to create content but impossible to sort or prioritize it, many cultural institutions end up with what they fear most: a jumbled mass of low-quality content'. Crowdsourcing the improvement of cultural heritage data would also make possible non-crowdsourcing engagement projects that need better content to be viable.
Platforms aimed at bootstrapping projects – that is, getting new projects up and running as quickly and as painlessly as possible – seem to be the next big thing. Designing tasks and interfaces suitable for mobile and tablets will allow even more of us to help out while killing time. There's also a lot of work on the integration of machine learning and human computation; my post 'Helping us fly? Machine learning and crowdsourcing' has more on this.
Find out how crowdsourcing in cultural heritage works by exploring projects
There's a lot of academic literature on all kinds of aspects of crowdsourcing, but I've gone for sources that are accessible both intellectually and in terms of licensing. If a key reference isn't there, it might be because I can't find a pre-print or whatever outside a paywall – let me know if you know of one!
Thanks to everyone who responded to my call for their favourite 'misconceptions and apprehensions about crowdsourcing (esp in history and cultural heritage)', and to those who inspired this post in the first place by asking questions in various places about the negative side of crowdsourcing. I'll update the post as I hear of more, so let me know your favourites. I'll also keep adding links and resources as I hear of them.