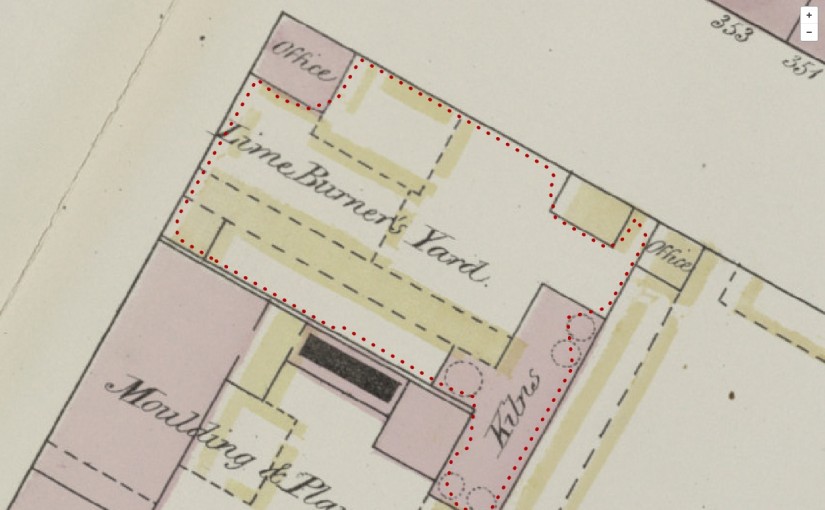
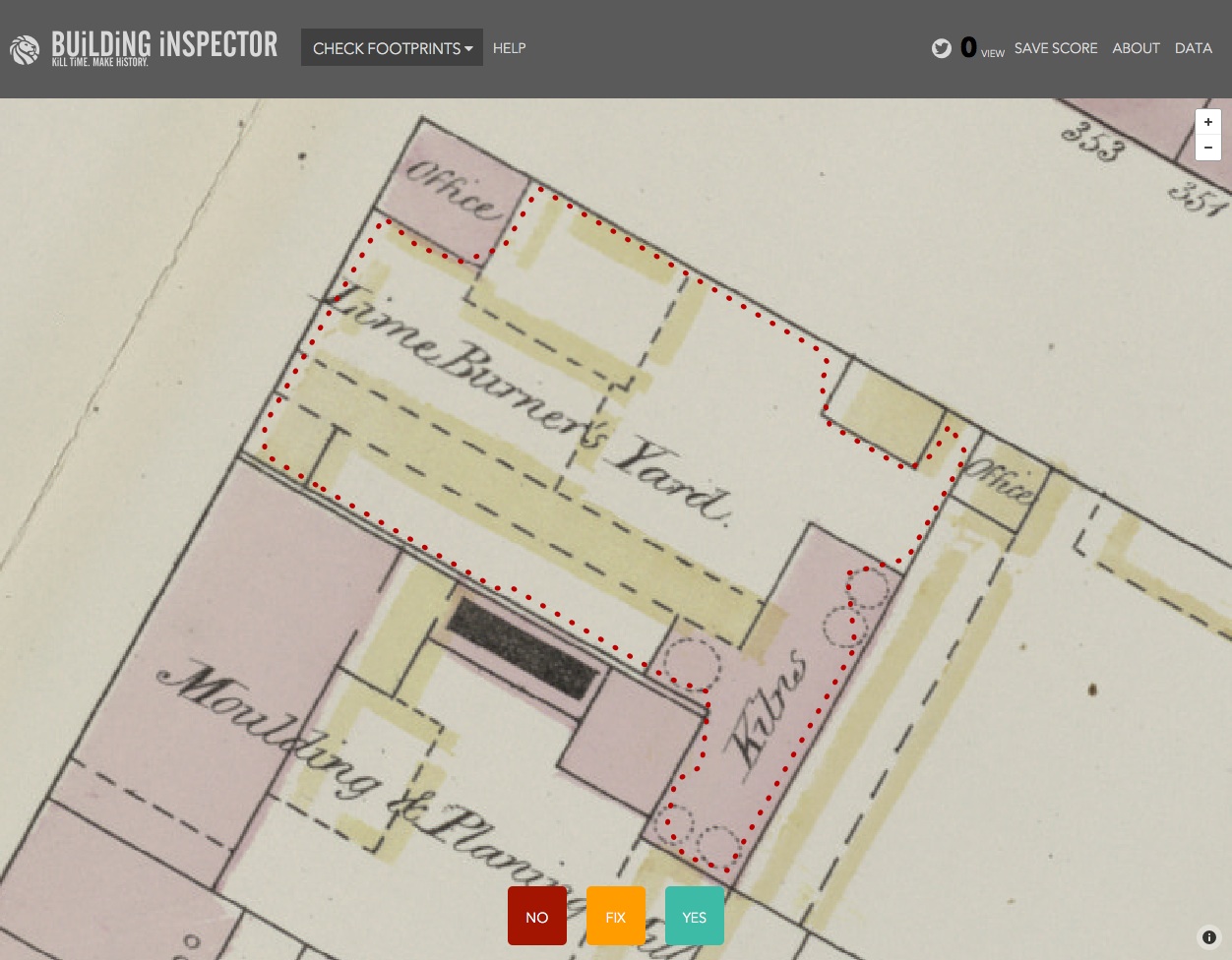
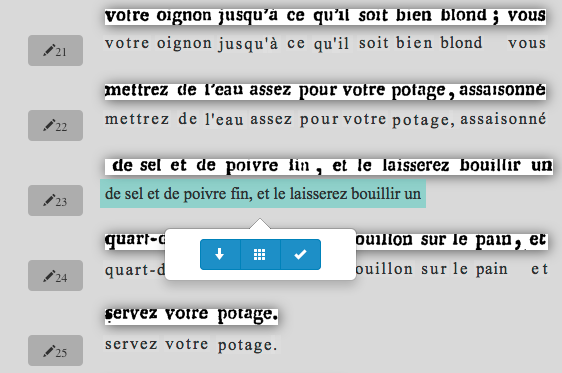
More new projects and project updates I've noticed over September 2016.
Gillian Lattimore @Irl_HeritageDig has posted some of her dissertation research on Crowdsourcing Motivations in a GLAM Context: A Research Survey of Transcriber Motivations of the Meitheal Dúchas.ie Crowdsourcing Project. dúchas.ie is 'a project to digitize the National Folklore Collection of Ireland, one of the largest folklore collections in the world'.
A long read on Brighton Pavilion and Museums’ Map The Museum, '#HeritageEveryware Map The Museum: connecting collections to the street' includes some great insights from Kevin Bacon.
Meghan Ferriter and Christine Rosenfeld have produced a special edition of a journal, 'Exploring the Smithsonian Institution Transcription Center' with articles on 'Crowdsourcing as Practice and Method in the Smithsonian Transcription Center' and more.
Two YouGov posts on American and British people's knowledge of their recent family history provide some useful figures on how many people in each region have researched family history.
Richard Light's posted some interesting questions and feedback for crowdsourcing projects at The GB1900.org project – first look.
'Archiving the Civil War’s Text Messages' provides more information about the Decoding the Civil War project.
Zooniverse blog post 'Why Cyclone Center is the CrockPot of citizen science projects' gives some insight into why some projects appear 'slower' than others.
A December 2015 post, 'How a citizen science app with over 70,000 users is creating local community' (HT Jill Nugent @ntxscied) and an interesting contrast to 'Volunteer field technicians are bad for wildlife ecology'. A nice quote from the first piece: 'Young says that the number one thing that keeps iNaturalist users involved is the community that they create: “meeting other people who are into the same thing I am”'.
iNaturalist Bioblitz's are also more evidence for the value of time-limited challenges, or as they describe them, 'a communal citizen-science effort to record as many species within a designated location and time period as possible'.
Micropasts continue to add historical and archaeological projects.
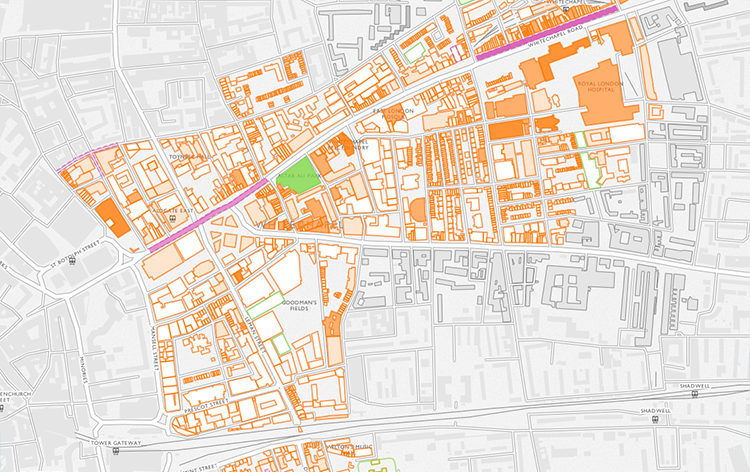
Survey of London and CASA launched the Histories of Whitechapel website, providing 'a new interactive map for exploring the Survey’s ongoing research into Whitechapel' and 'inviting people to submit their own memories, research, photographs, and videos of the area to help us uncover Whitechapel’s long and rich history'.
New Zooniverse project Mapping Change: 'Help us use over a century's worth of specimens to map the distribution of animals, plants, and fungi. Your data will let us know where species have been and predict where they may end up in the future!'
New Europeana project Europeana Transcribe: 'a crowdsourcing initiative for the transcription of digital material from the First World War, compiled by Europeana 1914-1918. With your help, we can create a vast and fully digital record of personal documents from the collection.'
'Holiday pictures help preserve the memory of world heritage sites' introduces Curious Travellers, a 'data-mining and crowd sourced infrastructure to help with digital documentation of archaeological sites, monuments and heritage at risk'. Or in non-academese, send them your photos and videos of threatened historic sites, particularly those in 'North Africa, including Cyrene in Libya, as well as those in Syria and the Middle East'.
I've added two new international projects, Les herbonautes, a French herbarium transcription project led by the Paris Natural History Museum, and Loki a Finnish project on maritime, coastal history to my post on Crowdsourcing the world's heritage – as always, let me know of other projects that should be included.