These are my notes for the talk I gave at OpenTech 2010 on the subject of 'Museums meet the 21st Century'. Some of it was based on the paper I wrote for Museums and the Web 2010 about the 'Cosmic Collections' mashup competition, but it also gave me a chance to reflect on bigger questions: so we've got some APIs and we're working on structured, open data – now what? Writing the talk helped me crystallise two thoughts that had been floating around my mind. One, that while "the coolest thing to do with your data will be thought of by someone else", that doesn't mean they'll know how to build it – developers are a vital link between museum APIs, linked data, etc and the general public; two, that we really need either aggregated datasets or data using shared standards to get the network effect that will enable the benefits of machine-readable museum data. The network effect would also make it easier to bridge gaps in collections, reuniting objects held in different institutions. I've copied my text below, slides are embedded at the bottom if you'd rather just look at the pictures. I had some brilliant questions from the audience and afterwards, I hope I was able to do them justice. OpenTech itself was a brilliant day full of friendly, inspiring people – if you can possibly go next year then do!
Museums meet the 21st century.
Open Tech, London, September 11, 2010
Hi, I'm Mia, I work for the Science Museum, but I'm mostly here in a personal capacity…
Alternative titles for this talk included: '18th century institution WLTM 21st century for mutual benefit, good times'; 'the Age of Enlightenment meets the Age of Participation'. The common theme behind them is that museums are old, slow-moving institutions with their roots in a different era.
Why am I here?
The proposal I submitted for this was 'Museums collaborating with the public – new opportunities for engagement?', which was something of a straw man, because I really want the answer to be 'yes, new opportunities for engagement'. But I didn't just mean any 'public', I meant specifically a public made up of people like you. I want to help museums open up data so more people can access it in more forms, but most people can't just have a bit of a tinker and create a mashup. “The coolest thing to do with your data will be thought of by someone else” – but that doesn’t mean they’ll know how to build it. Audiences out there need people like you to make websites and mobile apps and other ways for them to access museum content – developers are a vital link in the connection between museum data and the general public.
So there's that kind of help – helping the general public get into our data; and there's another kind of help – helping museums get their data out. For the first, I think I mostly just want you to know that there's data out there, and that we'd love you to do stuff with it.
The second is a request for help working on things that matter. Linkable, open data seems like a no-brainer, but museums need some help getting there.
Museums struggle with the why, with the how, and increasingly with the "we are reducing our opening hours, you have to be kidding me".
Chicken and the egg
Which comes first – museums get together and release interesting data in a usable form under a useful licence and developers use it to make cool things, or developers knock on the doors of museums saying 'we want to make cool things with your data' and museums get it sorted?
At the moment it's a bit of both, but the efforts of people in museums aren't always aligned with the requests from developers, and developers' requests don't always get sent to someone who'll know what to do with it.
So I'm here to talk about some stuff that's going on already and ask for a reality check – is this an idea worth pursuing? And if it is, then what next?
If there’s no demand for it, it won’t happen. Nick Poole, Chief Executive, Collections Trust, said on the Museums Computer Group email discussion list: "most museum people I speak to tend not to prioritise aggregation and open interoperability because there is not yet a clear use case for it, nor are there enough aggregators with enough critical mass to justify it.”
But first, an example…
An experiment – Cosmic Collections, the first museum mashup competition
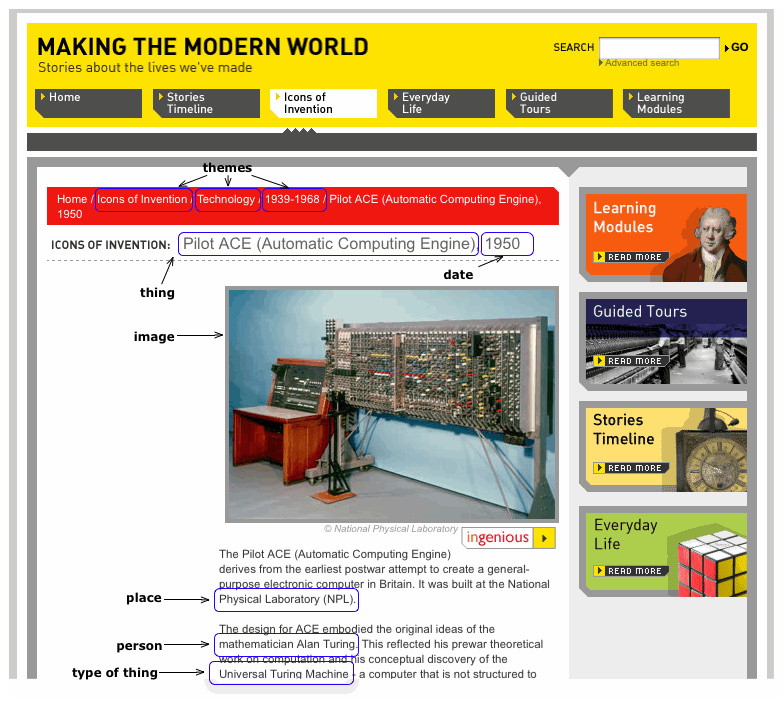
The Cosmic Collections project was based on a simple idea – what if a museum gave people the ability to make their own collection website for the general public? Way back in December 2008 I discovered that the Science Museum was planning an exhibition on astronomy and culture, to be called ‘Cosmos & Culture’. They had limited time and resources to produce a site to support the exhibition and risked creating ‘just another exhibition microsite’. I went to the curator, Alison Boyle, with a proposal – what if we provided access to the machine-readable exhibition content that was already being gathered internally, and threw it open to the public to make websites with it? And what if we motivated them to enter by offering competition prizes? Competition participants could win a prize and kudos, and museum audiences might get a much more interesting, innovative site. Astronomy is one of the few areas where the amateur can still make valued scientific contributions, so the idea was a good match for museum mission, exhibition content, technical context, and hopefully developers – but was that enough?
The project gave me a chance to investigate some specific questions. At the time, there were lots of calls from some quarters for museums to produce APIs for each project, but there was also doubt about whether anyone would actually use a museum API, whether we could justify an investment in APIs and machine-readable data. And can you really crowdsource the creation of collections interfaces? The Cosmic Collections competition was a way of finding out.
Lessons? An API isn't a magic bullet, you still need to support the dev community, and encourage non-technical people to find ways to play with it. But the project was definitely worth doing, even if just for the fact that it was done and the world didn't end. Plus, the results were good, and it reinforced the value of working with geeks. [It also got positive coverage in the technical press. Who wouldn’t be happy to hear ‘the museum itself has become an example of technological innovation’ or that it was ‘bringing museums out into the open as places of innovation’?]
Back to the chicken and the egg – linking museums
So, back to the chicken and the egg… Progress is being made, but it gets bogged down in discussions about how exactly to get data online. Museums have enough trouble getting the suppliers they work with to produce code that meets accessibility standards, let alone beautifully structured, re-usable open data.
One of the reasons open, structured data is so attractive to museum technologists is that we know we can never build interfaces to meet the needs of every type of audience. Machine-readable data should allow people with particular needs to create something that supports their own requirements or combines their data with ours to make lovely new things.
Explore with us – tell museums what you need
So if you're someone who wants to build something, I want to hear from you about what standards you're already working with, which formats work best for you…
To an extent that's just moving the problem further down the line, because I've discovered that when you ask people what data standards they want to use, and they tell you it turns out they're all different… but at least progress is being made.
Dragons we have faced
I think museums are getting to the point where they can live with the 80% in the interest of actually getting stuff done.
Museums need to get over the idea that linkable data must be perfect – perfectly clean data, perfectly mapped to perfect vocabularies and perfectly delivered through perfect standards. Museums are used to mapping data from their collections management systems for a known end-use, they've struggled with open-ended requirements for unknown future uses.
The idea that aggregated data must be able to do everything that data provided at source can do has held us back. Aggregated data doesn't need to be able to do everything – sometimes discoverability is enough, as long as you can get back to the source if you need the rest of the data. Sometimes it's enough to be able to link to someone else's record that you've discovered.
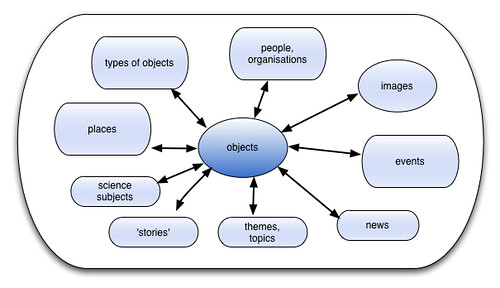
Museum data and the network effect
One reason I'm here (despite the fact that public speaking is terrifying) is a vision of the network effect that could apply when we have open museum data.
We could re-unite objects across time and place and people, connecting visitors and objects, regardless of owing institution or what type of object or information it is. We could create highlight collections by mining data across museums, using the links people are making between our collections. We can help people tell their local stories as well as the stories about big subject and world histories. Shared data standards should reduce learning curve for people using our data which would hopefully increase re-use.
Mismatches between museums and tech – reasons to be patient
So that's all very exciting, but since I've also learnt that talking about something creates expectations, here are some reasons to be patient with museums, and tolerant when we fail to get it right the first time…
IT is not a priority for most museums, keeping our objects secure and in one piece is, as is getting some of them on display in ways that make sense to our audiences.
Museums are slow. We'll be talking about stuff for a long time before it happens, because we have limited resources and risk-averse institutions. Museum project management is designed for large infrastructure projects, moving hundreds of delicate objects around while major architectural builds go on. It's difficult to find space for agility and experimentation within that.
Nancy Proctor from the Smithsonian said this week: "[Museum] work is more constrained than a general developer" – it must be of the highest quality; for everybody – public good requires relevance and service for all, and because museums are in the 'forever business' it must be sustainable.
How you can make a difference
Museums are slowly adapting to the participation models of social media. You can help museums create (backend) architectures of participation. Here are some places where you can join in conversations with museum technologists:
Museums Computer Group – events, mailing list http://museumscomputergroup.org.uk/ #ukmcg @ukmcg
Linking Museums – meetups, practical examples, experimenting with machine-readable data http://museum-api.pbworks.com/
Space Time Camp – Nov 4/5, #spacetimecamp
‘Museums and the Web’ conference papers online provide a good overview of current work in the sector http://www.archimuse.com/conferences/mw.html
So that‘s all fun, but to conclude – this is all about getting museums to the point where the technology just works, data flows like water and our energy is focussed on the compelling stories museums can tell with the public. If you want to work on things that matter – museums matter, and they belong to all of us – we should all be able to tell stories with and through museums.
Thank you for listening
Keep in touch at @mia_out or https://openobjects.org.uk/