I'm speaking at Open Tech 2010 (book your ticket now, only £5!) and it feels like the situation (and the mood) in the UK has changed since I first wrote my proposal and I'm not sure it suits anymore. So I wanted to throw a few questions open to you to help me re-focus on the things that matter now:
what do you value about museums and technology, particularly the web, social media, open data?
what do you want to know from someone working behind the scenes in museum technology?
what suggestions would you make if you were able to talk to museums?
what aren't museums asking our audiences (including our geek audiences) that we should be asking?
what's your favourite biscuit (or cookie)?
The title, by the way, is a play on 'ask a curator', an online event of some sort where you can ask whatever you've always wanted to ask a curator by using the hash tag #askacurator on twitter (or possibly also by commenting on a museum's blog, Facebook wall, twitter account, etc).
Somehow I've ended up organising an (very informal) event about 'Linking museums: machine-readable data in cultural heritage' on Wednesday, July 7, at a pub near Liverpool St Station. I have no real idea what to expect, but I'd love some feisty sceptics to show up and challenge people to make all these geeky acronyms work in the real museum world.
As I posted to the MCG list: "A very informal meetup to discuss 'Linking museums: machine-readable data in cultural heritage' is happening next Wednesday. I'm hoping for a good mix of people with different levels of experience and different perspectives on the issue of publishing data that can be re-used outside the institution that created it. … please do pass this on to others who may be interested. If you would like to come but can't get down to that London, please feel free to send me your questions and comments (or beer money)."
Why? I'm trying to cut through the chicken and egg problem – as a museum technologist, I can work towards getting machine-readable data available, but I'm not sure which formats and what data would be most useful for developers who might use it. Without a critical mass of take-up for any one type, the benefits of any one data source are more limited for developers. But museums seem to want a sense of where the critical mass is going to be so they can build for that. How do we cut through this and come up with a sensible roadmap?
Who? You! If you're interested in using museum data in mashups but find it difficult to get started or find the data available isn't easily usable; if you have data you want to publish; if you work in a museum and have a data publication problem you'd like help in solving; if you are a cheerleader for your favourite acronym…
Put another way, this event is for you if you're interested in publishing and sharing data about their museums and collections through technologies such as linked data and microformats.
It'll be pretty informal! I'm not sure how much we can get done but it'd be nice to put faces to names, and maybe start some discussions around the various problems that could be solved and tools that could be created with machine-readable data in cultural heritage.
Nick Serota, Director of the Tate, writes about modern museums in 'Why Tate Modern needs to expand'. I'm not sure he convinces me that the expansion needs to be physical, but it's a brilliant case for expanding Tate's online presence:
The world also sees museums differently. Wide international access, directly or through digital media and at all levels of understanding offers the opportunity for new kinds of collaboration with individuals and institutions.
The traditional function of the museum has been that of instruction, with the curator setting the terms of engagement between the visitor and the work of art. But in the past 20 years the development of the internet, the rise of the blog and social networking sites, as well as the more direct intervention in museum spaces by artists themselves, has begun to change the expectations of visitors, and their relationship with the curator as authoritative specialist. The challenge for museums in the 21st century is to find new ways of engaging with much more demanding, sophisticated and better informed viewers. Our museums have to respond to and become places where ideas, opinions and experiences are exchanged, and not simply learned.
…
The museum of the 21st century should be based on encounters with the unfamiliar and on exchange and debate rather than only on an idea of the perfect muse—private reflection and withdrawal from the "real" world. Of course, the museum continues to provide a place of contemplation and of protection from the direct pressures of the commercial and the market. It has to have some anchors or fixed points for orientation and stability, but it also has to be a dynamic space for ideas, conversations and debate about new and historic art within a global context.
The Tate's Head of Online, John Stack, has put the Tate Online Strategy 2010–12, including their 'Ten principles for Tate Online'. Go read it – with any luck UK parliament will have managed to form a government by the time you're done.
So, do you agree with Serota? What are the challenges you face in your museum in the 21st century?
This is a lazy post, a straight copy and paste of my presentation notes (my excuse is that I'm eight days behind on everything at work and uni after being grounded in the US by volcanic ash). Anyway, I hope you enjoy it or that it's useful in some way.
The Cosmic Collections project was based on a simple idea – what if we gave people the ability to make their own collection website? The Science Museum was planning an exhibition on astronomy and culture, to be called ‘Cosmos & Culture’. We had limited time and resources to produce a site to support the exhibition and we risked creating ‘just another exhibition microsite’. So what if we provided access to the machine-readable exhibition content that was already being gathered internally, and threw it open to the public to make websites with it? And what if we motivated them to enter by offering competition prizes? Competition participants could win a prize and kudos, and museum audiences might get a much more interesting, innovative site.
The idea was a good match for museum mission, exhibition content, technical context, hopefully audience – but was that enough?
Slide 2 (satellite dish):
Questions…
If we built an API, would anyone use it?
Can you really crowdsource the creation of collections interfaces?
The project gave me a chance to investigate some specific questions. At the time, there were lots of calls from some quarters for museums to produce APIs for each project, but would anyone actually use a museum API? The competition might help us understand whether or how we should invest in APIs and machine-readable data.
We can never build interfaces to meet the needs of every type of audience. One of the promises of machine-readable data is that anyone can make something with your data, allowing people with particular needs to create something that supports their own requirements or combines their data with ours – but would anyone actually do it?
Slide 3 (map mashup):
Mashups combine data from one or more sources and/or data and visualisation tools such as maps or timelines.
I'm going to get the geek stuff out of the way and quickly define mashups and APIs…
Mashups are computer applications that take existing information from known sources and present it to the viewer in a new way. Here’s a mashup of content edits from Wikipedia with a map showing the location of the edit.
Slide 4 (APIs)
APIs (Application Programming Interfaces) are a way for one machine to talk to another: ‘Hi Bob, I’d like a list of objects from you, and hey, Alice, could you draw me a timeline to put the objects on?’
APIs tell a computer, 'if you go here, you will get that information, presented like this, and you can do that with it'.
A way of providing re-usable content to the public, other museums and other departments within our museum – we created a shared backend for web and gallery interactives.
I think of APIs as user interfaces for developers and wanted to design a good experience for developers with the same care you would for end users*. I hoped that feedback from the competition could be used to improve the beta API
* we didn’t succeed in the first go but it’s something to aim for post-beta
Slide 5: (what if nobody came?)
AKA 'the fears and how to deal with them'
Acknowledge those fears
Plan for the worst case scenario
Take a deep breath and do it anyway
And on the next slides, the results. If I was replicating the real experience, you’d have several nerve-biting months while you waited for the museum to lumber into gear, planned the launch event, publicised the project in the participant communities… Then waited for results to come in. But let’s skip that bit…
The results – our judges declared a winner and a runner-up, these are screenshots – this is the second prize winning entry.
People came to the party. Yay! I'd like to thank all the participants, whether they submitted a final entry or not. It wouldn't have worked without them.
Slide 7: (Natalie and Simon's http://cosmos.natimon.com/)
This is a screenshot from the winning site – it made the best use of the API and was designed to lure the visitor in and keep drawing them through the site.
(We didn’t get subject specialists scratching their own itch – maybe they don’t need to share their work, maybe we didn’t reach them. Would like to reach researchers, let them know we have resources to be used, also that they can help us/our audiences by sharing their work)
Slide 8: (astrolabe – what did we learn?)
People need (more) help to participate in a geektastic project like this
The dynamics of a competition are tricky
Mashups are shaped by the data provided – you get out what you put in
Can we help people bring their own content to a future mashup?
Slide 9: (evaluation)
I did a small survey to evaluate the project… Turns out the project was excellent outreach into the developer community. People were really excited about being invited to play with our data. My favourite quote: "The very idea of the competition was awesome"
Slide 10: (paper sheet)
Also positive coverage in technical press. So in conclusion?
Slide 11: (Tim Berners-Lee):
“The thing people are amazed about with the web is that, when you put something online, you don’t know who is going to use it—but it does get used.”
There are a lot of opportunities and excitement around putting machine-readable data online…
Slide 12: Tim Berners-Lee 2:
But: It doesn’t happen automatically; It’s not a magic bullet
But people won't find and use your APIs without some encouragement. You need to support your API users. People outside the museum bring new ideas but there's still a big role for people who really understand the data and audiences to help make it a quality experience…
Slide 13 (space):
What next?
Using the feedback to focus and improve collection-wide API
Adding other forms of machine-readable data
Connecting with data from your collections?
I've been thinking about how to improve APIs – offer subject authorities with links to collections, embed markup in the collections pages to help search engines understand our data…
I want more! The more of us with machine-readable data available for re-use, the better the cross-collections searches, the region or specialism-wide mashups… I'd love to be able to put together a mashup showing all the cultural heritage content about my suburb; all the Boucher self-portraits; all the inventions that helped make the Space Shuttle work…
Slide 14: (thank you)
If you're interested in possibilities of machine-readable data and access to your collections, join in the conversation on the museum API wiki or follow along on twitter or on blogs. Join in at http://museum-api.pbworks.com/
This was originally posted on the 'Museums and the machine-processable web' wiki.
This is a rough report from an unconference session on RDFa, microformats and museum data held during Museums and the Web 2010.
I'm writing it up later than I intended (blame the volcano) so please excuse any mistakes in writing up, misattributions, etc – you can sign in to edit them yourself, leave a comment or drop me a line (contact details on the register your interest page).
I'm also writing it up just before I head to the airport, so this first version won't be complete so do jump in and add your own notes if you were there (or wanted to be).
We started by introducing ourselves and briefly describing our interest in the session.
Those present were: Richard Urban, Nate Solas, Paul Hagon, Peter Goodall, Bart Grob (?), Ilya, Piotr Adamczyk, Richard Morgan, Paul Rowe, Darren Scott, Erich Schroeder, Patrick Schmitz, Gunter Waibel…
Interests included: included inference rules based on metadata, embedding metadata in webpages, breaking through the 'analysis paralysis' and choosing a standard to implement (even if it wasn't perfect),
What problems are people having? Picking a standard!
What issues arose during the unconference?
There was an interesting tension between the 'just do it, near enough is good enough' and the 'let's wait until we've got the standard right' impulses – as museum technologists I guess many of us are a mixture of both. But there was also a feeling that we should find a way to move beyond the questions to the point where we start implementing something, with an eye to having a demonstrator project available by this time next year (so April 2011).
We made a useful distinction between a lightweight shared 'standard' that aimed to increase the discoverability of content, and more heavyweight standards that might be used internally or implemented with particular uses in mind. This distinction allows us to keep working through the issues to come up with a suitable (usable, robust, sustainable, implementable, accurate) long-term solution while trying out existing or ad hoc standards in the shorter term.
The voices of reason
One of the reasons I was so happy with this unconference session is that all kinds of people contributed commonsense warnings from their various domains and experiences. Piotr and Richard said they were still looking for the things that could be done in RDFa that couldn't be done with existing infrastructure.
The use cases
Providing use cases helps everyone understand what we each want to do with the data as well as what we have in our collections.
Peter Goodall wants to make it easy for museums to do mashup collections.
Piotr is still looking for what can be done in RDFa that can't be done with existing infrastructure…
Ilya – neighbourhood project – Open Source Software Foundary – implemented RDFa as a demonstration – FOAF is format to describe social networks and DOPE – description of a project. What kind of aggregation service could we endorse to harvest from our collections?
One of mine: Caroline Herschel (1750 1848) is an astronomer, and there's content about her in lots of museums across the world. I've encountered her in Brooklyn Museum, the National Maritime Museum, the National Portrait Gallery… I'd love to link to images and content from all those other museums from our page about her – but how would I find that content, and how could I reliably link to it?
Erich from Illinois state museum – was working on oral historyproject on agriculture, indexed to really detailed level – wants to provide user with a proper citation for an interview clip. Found zotero but only got as far as that.
Gunter: OAI-PMH and CDWA-Lite on last project; writing tips for museums working on stuff like this.
FOAF? Richard, V&A – just done collections online with an API that wasn't really standards-based. Is with Piotr – we should just be able to do this stuff with NLP and text mining – also interested in FOAF. FOAF sounds like a winner as we know there are people out there lookig for people's names.
Peter Goodall – large db of people to disambiguate names. Paul – playing with FOAF – someone made a FOAF generator from their API. Paul Rowe – NZ museums project – looking at terminologies and overlaps.
Or maybe not FOAF… Patrick from CollectionSpace and UC Berkeley – in past life has done lots of semantic work but has reservations about RDFa. Worries about vocabs e.g. Dublin Core that turns out to be irreconcilable but once embedded make it hard to do more serious things. Interested in reasoning and inferencing across collections. Ontologies are a point of view, doesn't believe can have a universal point of view. Use NLP (natural language processing) to index collections from a given community. Interesting to explore more specifically the use cases e.g. compelling cases around events. FOAF doesn't let you model different types of relationships and roles that one person may fulfil. e.g. of how it's hard to shift a community to something more refined once a model is in place. Potential to generate multiple points of view with different vocabs, use cases will help him understand.
What next? AKA, getting on with it
Testing standards – I'm really up for implementing something on our existing pages – I was thinking that a comparison of two different standards, both marked up as RDFa on existing Science Museum/NMSI web pages (Dublin Core on Ingenious and LIDO on Making the Modern World) , would help provide some useful data on the utility of the approach and the beginning of a comparison between standards. I've written about it a bit at http://museum-api.pbworks.com/Science-Museum-linked-data – it's a very unfinished document but if you've got suggestions how making it better I'd love to hear them.
[My notes get sketchy from here on it because I'm returning to them after a few months, and some use cases may have ended up in this section, but that's probably ok]
It was suggested that versioning could be a way of dealing with the fact that we don't have a perfect standard right now – it could allow us to iterate through various prototypes and demonstrators until we get something good, while not breaking projects that are built in the meantime.
Microformats – Paul Hagon has used them on event (and other stuff?), Nate pointed out that they're used by Google and Yahoo.
Dublin Core is 'messy'. Patrick: 'is a little better than tagging'. Peter – interested in using really dumb taxa cos people catalogue inconsistently anyway. Patrick – taxa even in life sciences don't agree. Something that's good enough vs something perfect. Map to shared system with mapping to the authorities used to back things up. PS: instead of describing a free concept, e.g. a pig, but 'a pig' and when we say pig, we mean it as in this name authority. GW: identifier-based systems. How much do we aim for perfection? PS: don't tie yourself to a syntax that doesn't allow for that. NS: What can we solve today? PS: don't want to say figure everything out before you start but consider later options. NS: let's do something lightweight – add RDFa to marked up pages. Peter G: interested in something really simple… really interesting thing is the objects – being able to refer to the identity of an object from a pictorial represntation.
LIDO as vocab that works for social history museums and not just art galleries; Dublin Core as quick win.
NS: if we provide enough good enough markup… PA: satisficing approach. WordNet as term, authority list. Grappling with issues around how lightweight/heavyweight to go that allows useful exchange of records/assertions. PS: can I pivot across museums based on some RDFa tags?
[So as you can see, there were no solid conclusions and we didn't leave with an agreement "let's all try implementing x". I still like the idea of an MW2010 challenge, ideally something you can participate in as a publisher or consumer of data… Suggestions?]
I’m particularly interested in finding the balance between a solution we can achieve in the medium-term and something that works with standards as much as possible.
It’s nearly time for the Museums and the Web 2010 conference, where questions like this might be addressed in one of the unconference sessions so I’d love to hear your thoughts.
This is very much a work in progress, and in fact I suspect it's not even the latest version, but hopefully at least it's more useful up here than on my hard drive, even in a very draft-ish state.
February, 2010.
This is a thoughts-in-development piece on how the Science Museum/NMSI could provide re-usable, interoperable, structured machine-readable data for use as linked data or APIs.
I'm including here things that we generally have enough information about for it to make sense for us to link them. I'll talk about ways to link to the rest of the world below.
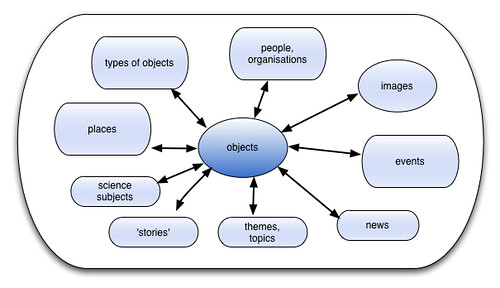
Objects – we have lots of these. Yay! Each record is about a specific accessioned object. As you can see from the diagram above, objects can be related to everything else (and to each other, in various ways). An object might be as big and iconic as Robert Stephenson's Rocket or as small as a spark plug.
Types of objects – a more generic view. It allows us to solve two problems – our collections don't cover everything we want to talk about, and we have lots and lots of certain types of objects. So a page on spark plugs is a user-friendly layer of content about spark plugs for general readers and provides links to all 8000 spark plugs in the collection (I totally made that number up).
It lets us discuss topics that our collections don't cover comprehensively, and to create a user-friendly layer between the detail of our collection (8000 spark plugs) and general information about spark plugs.
[If you're not familiar with museum collections – coverage varies according to what was collectable or collected – our collections may represent fashions in history of collecting more than an ideal uber-collection. Unlike, say, an art gallery, not every single item in our collection is a precious and unique diamond – for the general user, it might be enough to know what we have some information about dental forceps and a picture of one – but for the specialist researcher, browsing our collection of 300 of them might be the highlight of their week. (Maybe).]
Places – in our collections databases, we can look at the place an object was made, used, designed, destroyed, collected, restored, redesigned, invented, etc, etc. People and events also have various possible relationships to places.
People/organisations – ideally, we'd like to Wikipedia for every person and place, but not everyone we refer to in our collections has Wikipedia notability.
Images – we also have lots of related images, which are a major asset but work better in relation to other things (like objects) than as concepts on their own.
Other hooks in our content include dates and materials – these might be particularly useful for facetted browsing or mashups made with our data, but don't particularly make sense as concepts on their own. We also produce contemporary science news through our (re-opening in June) Antenna gallery, and marking this up with hNews seems a no-brainer. Working out how to link to the original news stories, whether in Nature, the BBC, whatever, would be good – something we can build into the publishing platform (WordPress MU) to make it nice and easy for our content authors would be even better.
Linking concepts and microsites, creating a canonical object home
I'm proposing a model that should allow us to make the most of all the data we've got online already as well as designing around concepts.
[see notes below for some background]
As well as 'objects' as a basic concept, museums come with a handy set of stable concepts built into our collections management systems. Sometimes these are called 'subject authorities'. They cover things like people and organisations, places, events and the relationships between them. We often build various interpretative narrative layers on top of them – themes, topics, stories, whatever.
If we build permanent URIs around those concepts, we can link to them from the existing microsites. We can also wrap metadata around the elements already on the pages of those microsites so that the data is meaningfully machine-accessible in situ.
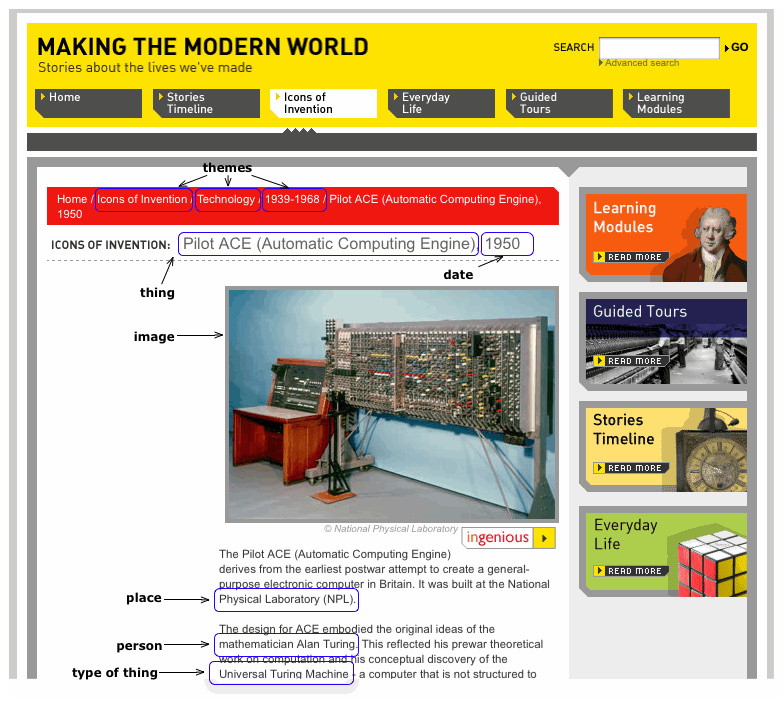
As an example, we'd have http://sciencemuseum.org.uk/objects/1956-152 as the 'home page' for the Pilot ACE computer in our collection. This page would contain the basic 'tombstone' information – when, where, what, etc, and link to every known instance of the object in other sites, as below. These other sites might be exhibitions, subject-specialist sites, cross-institution collections. Often they'll contain information written specifically for that site, particularly tailored for its scope and audiences.
This object is represented in various microsites. The image below shows up we might mark up those sites with links to our Science Museum concepts:
The object home page could also link to the Pilot Ace page on Ingenious and on our Centenary site, and they could link back to the object home. They could also link to our Alan Turing page, National Physical Laboratory page, etc.
It'd be great if we could link to other content about that object – this BBC article on Pilot ACE is a pointer to more content.
Vocabularies
This is one of the places I get stuck… Do we go general or specific? There's lots of stuff out there for visual resources but that doesn't describe our collections well. There's some discussion of this on various pages here, including Authority Lists, Implementation formats, and RDFa (the names get out of control fairly quickly!).
Notes on URIs
Some of our accession numbers are going to make things difficult because they contain '/'.
On Wednesday [you can tell how long ago I started this because that was February 24] I went to the second London Linked Data meetup, held during dev8D.
For a while I've been wondering what we (Science Museum/NMSI) could do with linked data, but it's also taken a while for the issues to bubble up.
The first two issues are data standards and vocabulary. As the saying goes, 'the good thing about standards is that there are so many to choose from'. http://museum-api.pbworks.com/Implementation-formats and http://museum-api.pbworks.com/RDFa bear witness to the difficulties of… finding out what developers prefer to work with (if they care at all), finding out what other museums can output to try and get some critical mass going…
The third is machine-readable interface design. Tom Scott [Apis and APIs] advocates building APIs so that you're linking people to the concepts that matter to them, and making your website your API. I think this is the right way to go, but it's made trickier by the fact that we're not a greenfield site – we've got exhibition microsites that are over ten years old. We're gradually migrating all that data into a central repository, but it'd be good if we could make the data already online in those sites re-usable too.
Other earlier notes… When designing the Cosmic Collections API last year, I'd considered building it into the 'human-facing' website architecture, so that a device could request XML or JSON versions of the pages alongside the (X)HTML pages. In the end I went for a standalone API as an interim solution. The Cosmic Collections competition was designed in part to answer some of my questions about the formats preferred by developers.
Comments on the Science Museum linked data wiki page
This made me realise I've also completely missed out 'exhibitions' as a concept – we do cover this for current exhibitions to an extent, but there's a lot of information hidden in the choices made for previous exhibitions that could be useful. It also contributes to really making the object home the definitive resource.
And another comment – can you tell I should be doing something else today? It's all about constructive procrastination.
Richard Morgan from across the road at the V&A commented (http://twitter.com/rmorg/status/10831225400), 'linked data vocabularies tricky for me too. For V&A I'm tending towards just geo, foaf and dbpedia – more about links than data' which I think is a useful perspective. There is a level at which the precise application of term lists matters, but if it means we spend the next ten years trying to get it perfect rather than doing something now, I'd rather we did something now. The two aren't mutually exclusive technically, but pragmatically I only have limited time/brain space in which to get something done.
Mia, hi… I think you'll need to model both real-world objects and web documents as part of this. So, for example… for any particular artefact, say the lunar lander, you have the thing itself (a real-world object which is assigned one URI) and the description of that thing (a Web document which is assigned a different URI).
To get from the 'object' URI to the 'description' URI requires an HTTP 303 redirect response (unless you choose to use hash URIs).
The 'description' URI can offer multiple representations, e.g. HTML with embedded RDFa and RDF/XML.
I like your list of "URIs and concepts we could model" and the idea of how the web page about an object in the collection can be linked to relevant people, places, images etc.
There's a lot of scope for this approach to help people to explore the collection from different perspectives and via different dimensions.
Vocabularies: this is an area where it makes sense to re-use existing work where possible, but if there is nothing out there that fits your purpose, don't be afraid to invent a new specialist vocabulary of your own. It's easy (and normal practice) to 'mix and match' terms from multiple vocabularies/ontologies as required.
Thanks for your really useful comments, Bill. I've been horribly busy preparing for a conference next week but will respond properly when my feet are back on the ground!
Try to keep in mind that an important reason for publishing the museums artifacts, whether real or digital, is to enable data about them to be "meshed" with other data (from the museum and from elsewhere) and republished, possibly in unanticipated ways, and the "mashed" applications that are created from those datasets. So the answer to whether you are doing it "correctly" will depend on the feedback you get!
The most important thing for you to do is ensure that you make it easy for your community of users to provide you with feedback, wiki a wiki or whatever. Make sure this is obvious and easy, AND that you adapt as they provide that feedback!
You might consider using OpenVocab http://open.vocab.org/ as a means for your community to add new terms.
There's already a great authoritative reference for places: GeoNames Ontology http://www.geonames.org/ontology/ "over 6.2 million geonames toponyms now have a unique URL with a corresponding RDF web service"
I think we can add a point that a RESTful web services (esp. based on simple common standards like Atom) can be useful for bridging between more "Plain Web" design approaches and linked data approaches. Here's a<a href='http://www.alexandriaarchive.org/blog/?p=497'> paper</a> I gave at the Computer Applications in Archaeology conference about this issue.
OK. Try this again, since HTML doesn't work in the comments.
Great discussion of the linked data issues.
I think we can add a point that a RESTful web services (esp. based on simple common standards like Atom) can be useful for bridging between more "Plain Web" design approaches and linked data approaches. Here's a(http://www.alexandriaarchive.org/blog/?p=497) I gave at the Computer Applications in Archaeology conference about this issue.
These thoughts are my own "take homes" from the discussion, rather than any sense of the meeting's overall conclusions.
What data do museums have?
Database content, mostly fielded and designed mainly for collections management support. Textual materials, much of it in a non-accessible "grey literature" format. Images.
The database content is typically (reasonably) self-consistent within a given environment. Thus we have known properties (from the field name) with usable string values. The challenge from a Linked Data perspective is the cost-effective generation of URLs from the string values currently held, e.g. for people and places, given that different museums will have different vocabularies to control their content.
Who wants to use this data?
The public, who are typically interested in classes of objects (rather than individual objects), or in objects with certain properties (e.g. coming from a place of interest to them). Educators, or more specifically people who create resources for educators to use. Students, if relevant objects could be easily accessed as "follow up" to formal learning materials.
Notes on 7 July 2010 meetup (part 2) How do we improve the data?
There is nothing to stop every museum publishing URLs, and whatever associated Linked Data they have to hand, for each object in their own collection, and thereby giving them a "hook" onto which others can hang added-value information and assertions of their own. They should treat this task as an urgent priority.
Where possible, convert string values in data to URLs, ideally widely-used (not just local) ones. Could use e.g. geonames.org for place names, or dbpedia for object class names. Interest in Portsmouth's historical gazetteer for "old" place names.
There is a clear need for a sector-specific ontology which represents the properties found, i.e. the types of information recorded in museum databases. This will act as the "predicate" in Linked Data triples/assertions. It could be based on an existing agreement about these semantics, e.g. CIDOC CRM or LIDO.
Axis-based data such as geographical co-ordinates or dates/date ranges could be treated as purely numerical data, or "pixellated" by assigning a URL which imposes a certain level of precision (e.g. year for dates). Or both approaches could be adopted.
What's the museum take on Linked Data?
Simple assertions are not enough; we care about the attribution of those assertions (i.e. who is making the assertion). We also want a framework which allows the expression of uncertainty and doubt.
We are not particularly bothered about the specific format (RDF/XML, RDFa, JSON, Topic Maps) in which Linked Data is published, but we would like to be able to "do the job once" and have done with it.
Thanks for the minutes Richard – seems like it was a really interesting discussion – shame I couldn't be there – particularly as we've been working with the author of CIDOC to start mapping our data! Look forward to the next meeting. Josh
I been wondering about identifiers, pref. UUID types this sort of fits in where you have [insert museum-y discussion of the exceptions] in your doc. given we have loads of object numbers full of illegal characters (for both file systems and URIs) I thought the concept of MuseumID may be very helpful as we moved toward linked data.. http://museumid.net/about
My Museums and the Web 2010 paper is up at Cosmic Collections: Creating a Big Bang and I'm working on the slides now and I'm curious – what would you like to see more of in a presentation? It's only short (6 minutes) so I'm currently thinking setup (including lots of definitions for non-geeks), outcomes (did the project succeed?), and a bit on what I think the next steps are (basically a call to get your data online in re-usable formats).
I'm thinking of leading with this Tim Berners-Lee quote from an article in Prospect, Mash the state:
"The thing people are amazed about with the web is that, when you put something online, you don't know who is going to use it—but it does get used."
I've been meaning to finish this for ages so I could post it, but then I realised it's more use in public in imperfect form than in private, so here goes – my thoughts on linked data, APIs and the Science Museum on the 'Museums and the machine-processable web' wiki. I'm still trying to find time to finish documenting my thoughts, and I've already had several useful comments that mean I'll need to update it, but I'd love to hear your thoughts, comments, etc.
Wikimedia@MW2010 is a workshop to be held in Denver in April, just before the Museums and the Web 2010 conference. The goal is to develop 'policies that will enable museums to better contribute to and use Wikipedia or Wikimedia Commons, and for the Wikimedia community to benefit from the expertise in museums'.
I'm going to be at the workshop and will do my best to represent any issues raised at the meeting. I think it's particularly important that we avoid 'Feeling glum after GLAM-WIKI' if we possibly can, so I'd like to go there with a really good understanding of the possible points of resistance, clashes in organisational culture or world view, incompatible requirements or wishlists so that they can be raised and hopefully dealt with during the in-person workshop. I'd love to hear from you if there are messages you want to pass on.
I'm also thinking about an informal meetup in London to help cultural heritage people articulate some of the issues that might help or hinder collaboration so they can be represented at the workshop – if you're a museum, gallery, archive, library or general cultural heritage bod, would that be useful for you?
Question 2 was added in response to a suggestion from a respondent after 20 responses had already been given, so for this reason alone, the results should not be taken as anything other than an interesting indication of responses. I've shared the written responses to various questions, and provided a quick and dirty analysis of the results.
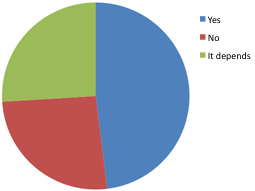
1. If you follow a museum on twitter, do you want it to follow you back?
Yes 49% No 26.50% It depends 26.50%
13 further comments were given for 'it depends':
if they're conversational or broadcasting
I hope they do, they don't have to.
Depends on what the account is doing. If it's just sending out announcements, who cares if it follows you back? If they're actually using Twitter, and there's an actual person back there somewhere doing something interesting, I'd be pleased if they decided to follow me, like any other user.
Of couirse I'd like it, but I understand if they don't due to over-following capacity!
If the museum is going to engage w/ me then yes; if it's just to broadcast I'm on the fence
I'm an art historian, so if an art museum started to follow me, I would be flattered! But if another kind of museum followed me, I would be slightly confused. So I think it would depend entirely on the profession of the person and if they use their account in a professional way
If they start wanting to be my best bud, I'd probably get creeped out and block them.
I wouldn't mind being followed, but not as a data point in a marketing database or to get impersonal spam.
I don't think I really have a strong view either way.
Why?
If I've started a discussion with said museum through twitter
Don't mind either way in most cases
it has no material effect — I don't gain anything from it following me.
I also posted the question on Facebook, and two people said it was weird. One went further, "I think it's weird, unless you primarily tweet about museums. I assume that anyone following me that is following more than 200 people doesn't actually read my tweets.".
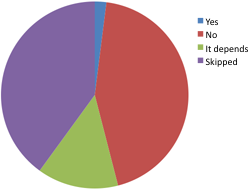
2. If you follow a museum on twitter, do you mind if it follows you back?
Yes 2% No 44% It depends 14% Skipped 40% [See note above about the number of 'skipped' responses]
7 further comments were given for 'it depends':
I'd rather be able to look at who you follow to find other twitterers of interest. Can't do that if you follow thousands of people back. Be selective so we can look thru them.
not unless my tweet is museum related
It depends on whether I know who is behind the tweets. Being a museum professional, sometimes they are colleagues, and that's okay with me.
I don't really care, but I think it's silly.
I just don't see why they would, it doesn't help either of us
See above :)
I would prefer it to follow back, especially if it's relevant to my own areas of historical interest, but no one has to follow anyone they don't want to.
So it looks like you can't win – almost 50% of new followers expect you to follow them and 50% either don't, or only do under some circumstances. As you can see from the responses to questions 3 and 4 (below), the results have presumably been skewed as 50% of respondents have a close involvement with museums, and a whopping two-thirds have a professional or academic interest in social media. I'm using the free version of SurveyMonkey so can't easily split out the 'social media' or 'museum professional' responses from the rest to see if people who are neither have different views on reciprocal following.
The only way to get a sense of whether followers of your particular museum account expect to be followed back, or mind being followed back, may be to ask them directly.
Of the people who were able to answer question 2, a very small minority unequivocally minded being followed by a museum account, but 44% of those who answered don't mind if a museum account doesn't follow them back.
Another interesting question would have been 'is it friendly or weird if an organisation follows you after you mention them?' – if you do any more research into the issue, let me know.
Question 6 asked for 'Any other comments?'.
Though I don't work in a museum, I work in or with museums. I think the main issue is that museums tweeting should have personality, you should feel it's a person (or group of people) that want to engage with you. I think if they follow me, it's more likely they will hear me and engage.
By following and being followed by a museum it creates a sense of community (although of course I realize the museums won't have time to read all the tweets).
I run a twitter account on behalf of a library, and think it's good manners to follow back someone who follows you (like returning a hello). I always try to reply to people who want to talk to us, but try not to butt into conversations that are *about* us, but which don't want us to reply to them (this can be tricky). As a user, by and large – I only want to talk to museums when I know the people doing the tweeting – and in New Zealand, I know most of these people anyway. Internationally, I do the same thing. Courtney Johnston, @auchmill, @nlnz
I like when museums respond to my comments or @ replies, but I'm not as comfortable with them following me. Being responsive is different than following.
Twiter has become one of the best sources for professional info & contacts @innova2
It would be more useful for the museum to keep track of hashtags, etc.
I want to communicate with people I follow, so following me back makes it easier. I don't expect them to read all/most of what I say, but it's nice…especially on my protected account (otherwise they never see the @)
Museums rock!
I don't really mind either way. I find it flattering if an institution wants to follow me. They must think I have something to say!
I feel that museums have a great opp to get more individuals involved in history and the arts via social media – personally I follow a few and am always pleased to hear about new exhibits, events, etc.
I work with museums, that's why I would like them to follow me back. I use Twitter for work, so I don't mind if they follow back. If I would talk to my friends over Twitter about private stuff maybe I WOULD mind….
If a museum (or anyone) didn't follow back, I would probably unfollow after a while unless their tweets were really something special.
I want people/institutions to follow me if they have genuine interest in my tweets – the same criteria I apply when choosing who to follow myself!
The real question probably should have been (or maybe an additional question should have been): do you MIND if a museum you follow follows you back. Because really, I don't necessarily want them to, but I don't mind if they do. I have the power to block if need be.
I think if the Museum was clear about WHY it was following me on twitter it would be less "stalkerish". In general I somewhat expect to be followed by those I am following. Although I am not sure if organizations (Museums) really need to follow individuals. I would imagine the Museum's staff would be overwhelmed with the number of completely unrelated tweets. What would be the advantage that couldn't be obtained better by simply searching twitter for key terms related to the museum, content, exhibit, etc? (Note: I do not work "in" a museum but have worked with over 6 museums to define and develop their websites and web marketing activities)
I manage a twitter feed for a project at a science center. I follow people, organizations and businesses that are in the service area for the project (a watershed). I also follow other organizations that are working on similar issues (water quality).
I think not following people back is poor Twitter etiquette. That is like saying to someone, "Listen to me! But I won't listen to you!"
1. Personally, I find follow bots mildly more insulting than not being followed back. 2. In my professional capacity tweeting for a museum, if someone @mentions us, I follow them (I consider it friendly). The fact that this could be done equally well (and more efficiently) by a bot disturbs me a bit.
I tweet with an interest in culture, art, and museums in mind. It's more of a compliment for museums to follow back than a feeling of being stalked, as it shows interest in its reader's tweets.
Leave the poor souls alone, they only want to know what's going on at your museum. I've blocked Museum of London (and I have every reason to trust them. Or not)
How is it stalkerish…dumb survey
Happy to be followed if it would help the museum understand more about its audience
So that's that. I thought 'being responsive is different than following' summed things up quite nicely, but whatever your view, some interesting opinions have been expressed above.
I hadn't considered before that not following someone back was rude – I must appear terribly rude on my personal accounts but I just can't keep up with so many accounts, especially as I can have lots of time away from the keyboard.
Finally, the demographic questions (kept brief to keep the survey short) 3. Do you work, study or volunteer in a museum? Yes 56% No 44%
4. Do you work, study or volunteer in social media? Yes 68% No 32%