This is a slightly abridged version of my notes for my keynote, 'Open for engagement: GLAM audiences and digital participation' at EuropeanaTech (#etech11) in Vienna in October 2011.
Introduction
I'm really excited about being here to talk about some of my favourite things with you. I think helping people appreciate cultural heritage is one of the best jobs in the world so I feel lucky to be here with people working toward the same goal.
This is a chance to remind ourselves why we should get audiences participating digitally – how does it benefit both GLAM (galleries, libraries, archives, museums) and their audiences? I'm going to take you through some examples of digital participation and explain why I think they're useful case studies. I'll finish by summarising what we can learn from those case studies, looking for tips you can take back to your organisations. Hopefully we'll have time for a few questions or some discussion.
Why enable participation?
Isn't it easier to just keep doing what we're already doing? Maybe not – here are some problems your GLAM organisation might be facing…
You need to think digitally to enable participation at scale – to reach not tens or hundreds, but thousands or hundreds of thousands of people. As cultural heritage organisations, we have lots of experience with access and participation at reference desks and in galleries. We are good at creating experiences to engage, delight, and educate in person, but these are limited by the number of staff required, the materiality of the objects or documents, the size of a venue, its location and opening hours. We're still learning how to translate those brilliant participative experiences into the digital domain…
Collections are big, resources are small. In most cases we're still digitising catalogue records, let alone taking images and writing beautiful contextualised interpretative material for our collections. We'll be at it for centuries if we try to do it alone…
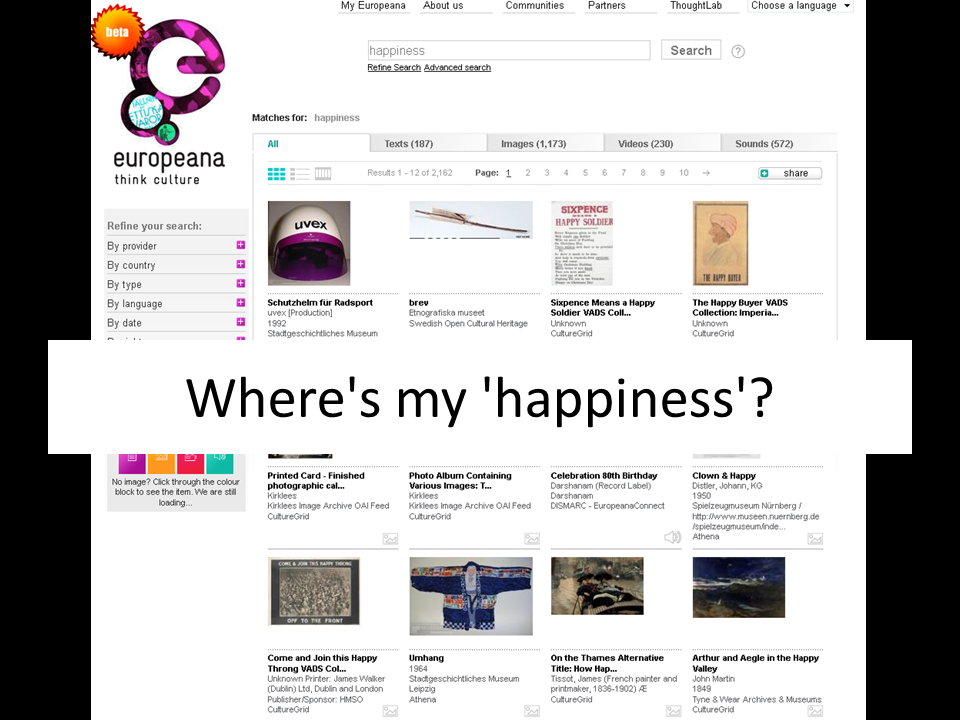
What's more, it's not enough for content to be online – it has to be findable. Our digitised content is still not very discoverable in search engines – which means it's effectively invisible to most potential audiences. We need better content to help search engines find the stuff we've put so much work into putting online. For example, I wanted to use Europeana images to illustrate my slides, but I had trouble finding images to match my ideas – but if other people had tagged them with words like 'happiness', 'excitement', 'crowds', I might have been able to find what I needed.
User-contributed content can help bridge the 'semantic gap' between the language used in catalogues and the language that most people would use to look for content.
Even when our content is found by our audiences, it's not always very accessible without information about the significance, and cultural and historical context of the item. Further, in Europeana's case, there's a gap between the many languages of the user community and the catalogue metadata; as well as gaps between historical and contemporary language. Sadly, at the moment, many records lack enough context for a non-expert to have a meaningful experience with them.
Why support participation?
So, those are some of the problems we're looking for solve… what are the benefits of digital participation?
Firstly, the benefits to organisations…
Engagement and participation is often part of your core mission.
inspire, passion, educate, enhance, promote preserve, record, access, learn, discover, use, memory, culture, conservation, innovation
I had a look at some mission statements from various museums, libraries, and archives, and these are the words that frequently occurred. The benefits of audience participation are both tangible and intangible, and exactly how they relate to your mission (and can be measured in relation to it) depends on the organisation. And don't forget that access may not be enough if your content isn't also discoverable and engaging.
Participation can increase traffic. It's pretty simple – if content is more discoverable, more people will discover it. If audiences can actively participate, they'll engage with your collections for longer, and return more often. They may even turn into physical visitors or buy something online…
Turn audiences into advocates – there are many people who forget that GLAMs even exist once they've left school – but these are often the people we can reach with digital projects. When people directly benefit from your resources, they know why your organisation is important. You're no longer dusty old stuff in boxes, you're their history, part of the story of how their lives came to be and how their future is formed. When people have a great experience with you, they become fans. When you encourage people to participate in meaningful work, they gain a sense of ownership and pride. These intangible outcomes can be as important as the content created through audience participation. It's a chance to let people see the full complexity of what you do, how much work goes into providing access and interpretation; understand that what they see on the shelves or in the galleries is the tip of the iceberg..
There are more experts outside your GLAM than within. Participatory projects let you access external knowledge. This knowledge can include the experience of using, repairing or building an object; memories of the events or places you've recorded; or it may be specialist knowledge they've built through their own research. Let them share their knowledge with you, and through you, with your audiences.
Finally, the rest of the world is moving from broadcast to dialogue and interaction. If you spend time around kids, you may have seen them interact with old-fashioned screens – for them, an interface you can only look at is broken.
Benefits to audience
It's all very well saying participation creates deeper engagement, but rather than tell you again, I'd rather show you with a quick thought experiment.
First I want you to imagine taking a photo of an object in a museum. Ok – so, how many times do you really go back and look at that photo? How much do you remember about that object? Do you find yourself thinking about it later? Do you ever have a conversation with friends about it?
Now I want you to imagine sketching the object, perhaps at this handy sketching station in the Musée des Beaux-Arts de Dijon.
As you draw, you'll find yourself engaging with the particular materiality of the object – the details of its construction, the way time has affected it. You may start wondering about the intention of the creators, what it was like to use it or encounter it in everyday life. In having an active relationship with that object, you've engaged more deeply, perhaps even changed a little as a result. New questions have been raised that you may find yourself pondering, and may even decide to find out more, and start your own research, or share your feelings with others.
Perhaps surprisingly, even the act of tagging an object has a similar effect, because you have to pay it some attention to say something about it…
A big benefit for audiences is that participation is rewarding. There are many reasons why, but these are some I think are relevant to participation. Games researcher Jane McGonigal (Gaming the future of museums) says people crave:
1. satisfying work to do
2. the experience of being good at something
3. time spent with people we like
4. the chance to be a part of something bigger
Participation in digital cultural heritage projects can meet all those needs.
Types of participation
The Center for Advancement of Informal Science Education came up with these forms of public participation in science research. Nina Simon of the Museum 2.0 blog mapped them to museums and added 'co-option'; I've included 'platform'.
- Contributory – Most GLAM user-generated content projects. Designed by the organisation, the public contributes data.
- Collaborative – the public may be active partners in some decisions, but the project is lead by the organisation
- Co-creative – all partners define goals and make decisions together
- Platform – organisation as venue or host for other activity.
It's also important to remember that there are some types of participation where the value lies mostly in the effect of the act of creation for the individual – for example, most commenting doesn't add much to my experience of the thing commented on. However, sometimes there's also value more widely – for example, when someone comments and includes a new fact or interesting personal story. Taking this further, participatory projects can be designed so that each contribution helps meet a defined goal. Crowdsourcing involves designing carefully scaffolded tasks so that the general public can contribute to a shared goal. Crowdsourcing in cultural heritage is probably most often contributory rather than collaborative or co-creative.
Case studies
I've chosen two established examples and two experimental ones to demonstrate how established digital participation is, and also where it's going…
Flickr Commons – I'm sure you've all probably heard of this, but it's a great reminder of how effective simply sharing content in places where people hang out can be. The first tip: go fishing where the fish are biting. Find the digital spaces where people are already engaging with similar content.
Example page: [Sylvia Sweets Tea Room, corner of School and Main streets, Brockton, Mass.]. You can see from the number of views, comments, tags, favourites and notes that organisations are still finding much higher levels of discoverability, traffic and user contributions on the Commons than they'd ever get on their own, individual sites. It's also a nice example of the public identifying a location, and there are wonderful personal recollections and family histories in the comments below.
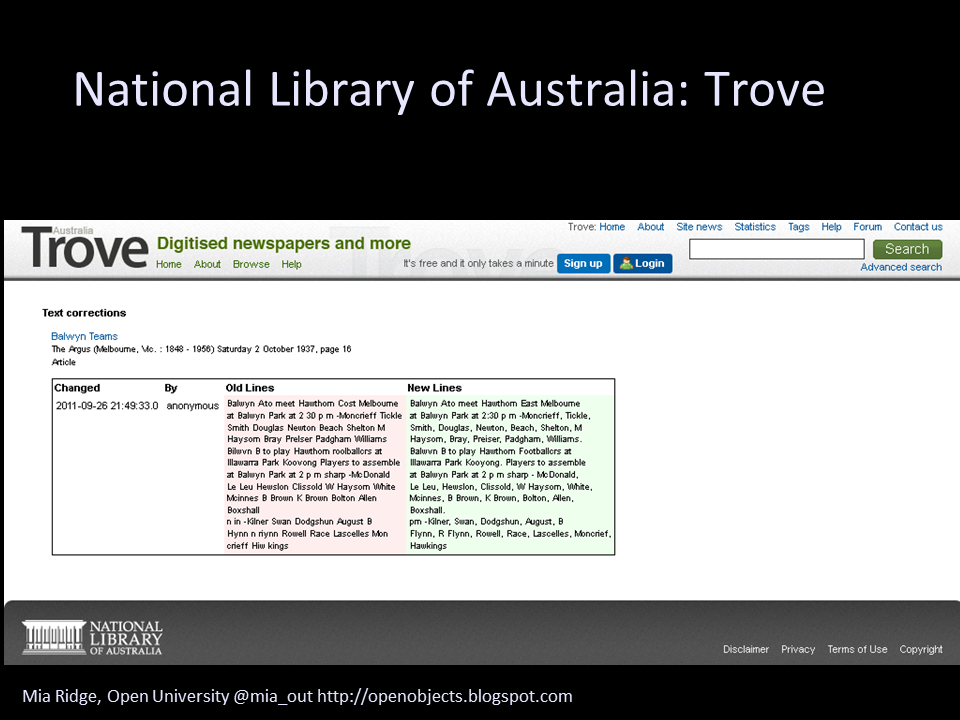
Trove – crowdsourcing OCR correction. Tasks like OCR correction that require judgement or complicated visual processing are perfect for crowdsourcing.
Crowdsourcing can solve real problems – helping scientists identify galaxies and proteins that could save lives, or providing data about climate change through history. In this example, crowdsourcing is helping correct optical character recognition (OCR) errors. In the example here, the correction is subtle, but as someone from the location described, I can tell you that the transcription now makes a lot more sense… And making that correction felt good.
According to the National Library of Australia, by February 2011 they had '20,000+ people helping out and 30 million lines of text had been corrected during the last 2 years'. This is a well-designed interface. Their clear 'call to action' – 'fix this text' – is simple and located right where it needs to be. Another tip: you don't need to register, but you can if you want to track your progress. Registration isn't a barrier, and it's presented as a benefit to the audience, not the organisation. They've also got a forum as a platform for conversation between participants.
So, crowdsourcing is great. But as crowdsourcing gets more popular, you will be competing for 'participation bandwidth' with other participatory and crowdsourcing projects – people will be deciding whether to work with your site or something else that meets their needs… What to do?
Well, it turns out that crowdsourcing games can act as 'participation engines'…
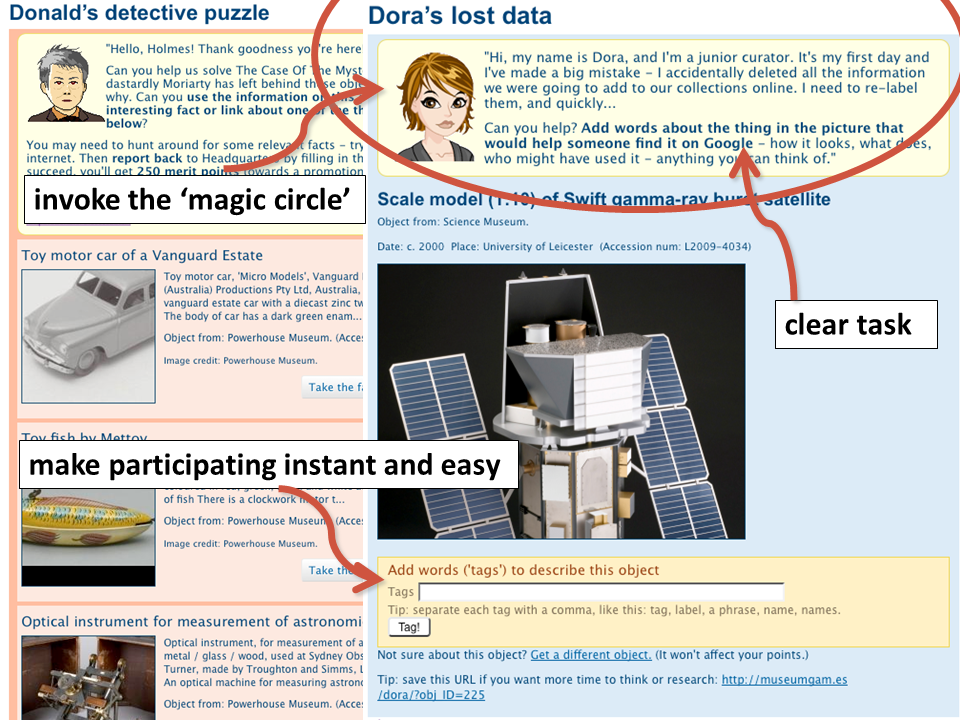
[I then talked about 'a small tagging game I researched, designed and made in my evenings and weekends, so that you can see the potential for crowdsourcing games even for GLAMs that don't have a lot of resources' – if you're curious, it's probably easiest to check out the slides at http://www.slideshare.net/miaridge/everyone-wins-crowdsourcing-games-and-museums alongside the video at http://vimeo.com/26858316].
Because crowdsourcing games can be more accessible to the general public, they can also increase the number of overall contributors, as well as encouraging each contributor to stay for longer, do more work, engage more deeply. Crowdsourcing games can be much more productive than a non-game interface by encouraging people to spend more time and play with more content. If games not suitable for your audience, you can adopt some of the characteristics of games – clear initial tasks to start with and a sense of the rules of the game, good feedback on the results of player actions towards a goal, mastering new skills and providing interesting problems to solve…
Continuing the [Europeana Tech] theme of openness, this project was only possible because the Science Museum (UK) and the Powerhouse Museum had APIs into their object records – I was able to create a game that united their astronomy objects without ever having to negotiate a partnership or licensing agreement.
Oramics – co-creation (and GLAM as platform). My final example is something I worked on just before I left the Science Museum but I make the caveat that I can't claim any credit for all the work done since, and I haven't seen any internal evaluation on the project.

The Oramics project was a conscious experiment in co-curation and public history, part of a wider programme of research. This is the Oramics machine. It's a difficult object to interpret – it's a hand-built synthesiser, and not much to look at – it's all about how it sounded, but it's too fragile to restore to working order. So the museum needed help interpreting the object, in understanding how to explain its significance and market it to new audiences. They tried a few different things in this project… They worked with young people from the National Youth Theatre who met museum staff to learn about the people who invented and built the machine, and they visited the object store to see the machine. They worked with developers to make an app to recreate the sounds of the synthesiser so that people could make new music with it. They also worked with a group of co-curators recruited online to help make it interesting to general visitors as well as music fans – the original call to action was something like 'we have an amazing object we need to bring to life, and six empty cases – help us fill them!'.
While the main outputs of all this activity are pretty traditional – a performance event, an exhibition – it's also been the catalyst for the creation of an ad hoc online community and conversations on Facebook and blogs.
As Clay Shirky told the Smithsonian 2.0 workshop in 2009, it's possible that "the artefact itself has created the surface to which the people adhere. … Every artefact is a latent community". It's nice to think we're finally getting to that point.
Best practice tips
So what do you need to think about to design a participatory project?
- Have an answer to 'Why would someone spend precious time on your project?'
- Be inspired by things people love
- Design for the audience you want
- Make participating pleasurable
- Don't add unnecessary friction, barriers
- Show how much you value contributions
- Validate procrastination – offer the opportunity to make a difference, and show, don't tell, how it's making a difference
- Make it easy to start participating, design scaffolded tasks to keep people going
- Let audiences help manage problems
- Test with users; iterate; polish
- Empower audience to keep the place tidy – let them know what's acceptable and what's discouraged and how they can help.
Best practice within your GLAM
How can your organisation make the most of the opportunities digital participation provides?
- Have a clear objective
- Know how to measure success
- Allow for community management resources
- Realistically assess fears, decide acceptable risk
- Put the audience's needs first. You need a balance between the task want to achieve, the skills and knowledge of audience and the content you have to work with.
- Fish where the fish are – find the spaces where people are already engaging with similar content and see how you can slot in, don't expect people to find their way to you.
- Decide where it's ok to lose control – let go… you may find audiences you didn't expect, or people may make use your content in ways you never imagined. Watch and learn – another reason to iterate and go into public beta earlier rather than later.
- Open data – let people make new things with your content. Bad people will do it anyway, but by not having open data, you're preventing exactly the people you want to work with from doing anything with your data. Unclear or closed licenses are the biggest barrier that friendly hackers and developers raise with me when I ask about cultural heritage data…
In a 2008 post about museum-as-platform, Nina Simon says it's about moving from controlling everything to providing expertise; learning to change from content provider to platform. [More recently, Rob Stein posted about participatory culture and the subtle differences between authoritarian and authoritative approaches.]
Conclusion
Perhaps most important of all – enjoy experiencing your collections through new eyes!